1 从什么叫“维度”说开来
我们不断提到一些语言,比如说:随机森林是通过随机抽取特征来建树,以避免高维计算;再比如说,sklearn中导入特征矩阵,必须是至少二维;上周我们讲解特征工程,还特地提到了,特征选择的目的是通过降维来降低算法的计算成本……这些语言都很正常地被我用来使用,直到有一天,一个小伙伴问了我,”维度“到底是什么?对于数组和Series来说,维度就是功能shape返回的结果,shape中返回了几个数字,就是几维。索引以外的数据,不分行列的叫一维(此时shape返回唯一的维度上的数据个数),有行列之分叫二维(shape返回行x列),也称为表。一张表最多二维,复数的表构成了更高的维度。当一个数组中存在2张3行4列的表时,shape返回的是(更高维,行,列)。当数组中存在2组2张3行4列的表时,数据就是4维,shape返回(2,2,3,4)。

数组中的每一张表,都可以是一个特征矩阵或一个DataFrame,这些结构永远只有一张表,所以一定有行列,其中行是样本,列是特征。针对每一张表,维度指的是样本的数量或特征的数量,一般无特别说明,指的都是特征的数量。除了索引之外,一个特征是一维,两个特征是二维,n个特征是n维。

对图像来说,维度就是图像中特征向量的数量。特征向量可以理解为是坐标轴,一个特征向量定义一条直线,是一维,两个相互垂直的特征向量定义一个平面,即一个直角坐标系,就是二维,三个相互垂直的特征向量定义一个空间,即一个立体直角坐标系,就是三维。三个以上的特征向量相互垂直,定义人眼无法看见,也无法想象的高维空 间。
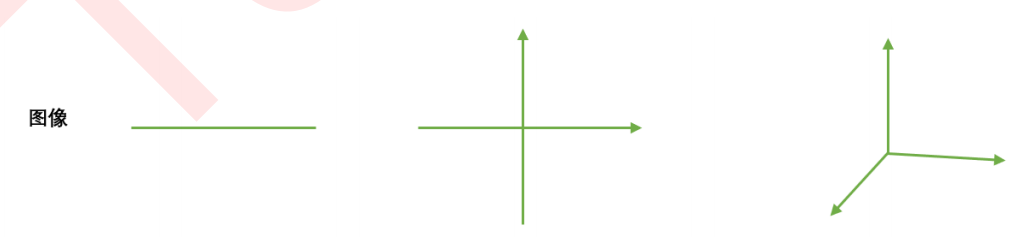
降维算法中的”降维“,指的是降低特征矩阵中特征的数量。上周的课中我们说过,降维的目的是为了让算法运算更快,效果更好,但其实还有另一种需求:数据可视化。从上面的图我们其实可以看得出,图像和特征矩阵的维度是可以相互对应的,即一个特征对应一个特征向量,对应一条坐标轴。所以,三维及以下的特征矩阵,是可以被可视化的,这可以帮助我们很快地理解数据的分布,而三维以上特征矩阵的则不能被可视化,数据的性质也就比较难理解。
2 sklearn中的降维算法
sklearn中降维算法都被包括在模块decomposition中,这个模块本质是一个矩阵分解模块。在过去的十年中,如果要讨论算法进步的先锋,矩阵分解可以说是独树一帜。矩阵分解可以用在降维,深度学习,聚类分析,数据预处理,低纬度特征学习,推荐系统,大数据分析等领域。在2006年,Netflflix曾经举办了一个奖金为100万美元的推荐系统算法比赛,最后的获奖者就使用了矩阵分解中的明星:奇异值分解SVD。
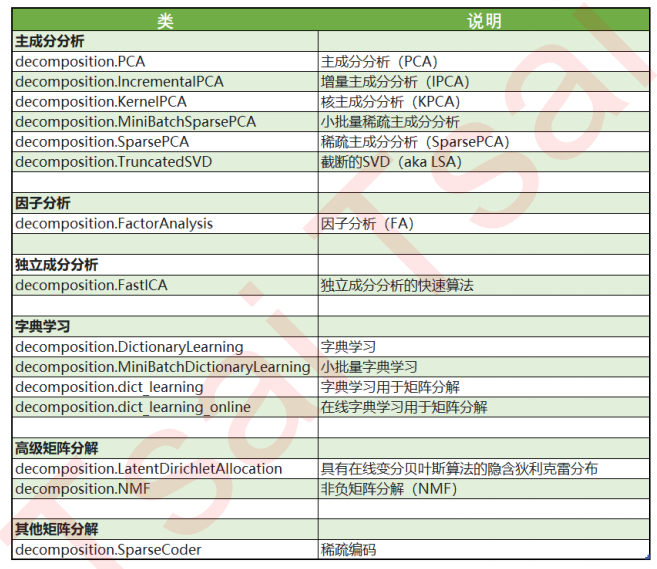
SVD和主成分分析PCA都属于矩阵分解算法中的入门算法,都是通过分解特征矩阵来进行降维,它们也是我们今天要讲解的重点。虽然是入门算法,却不代表PCA和SVD简单:下面两张图是我在一篇SVD的论文中随意截取的两页,可以看到满满的数学公式(基本是线性代数)。我会用最简单的方式为大家呈现降维算法的原理,但这注定意味着大家无法看到这个算法的全貌,在机器学习中逃避数学是邪道,所以更多原理大家自己去阅读。