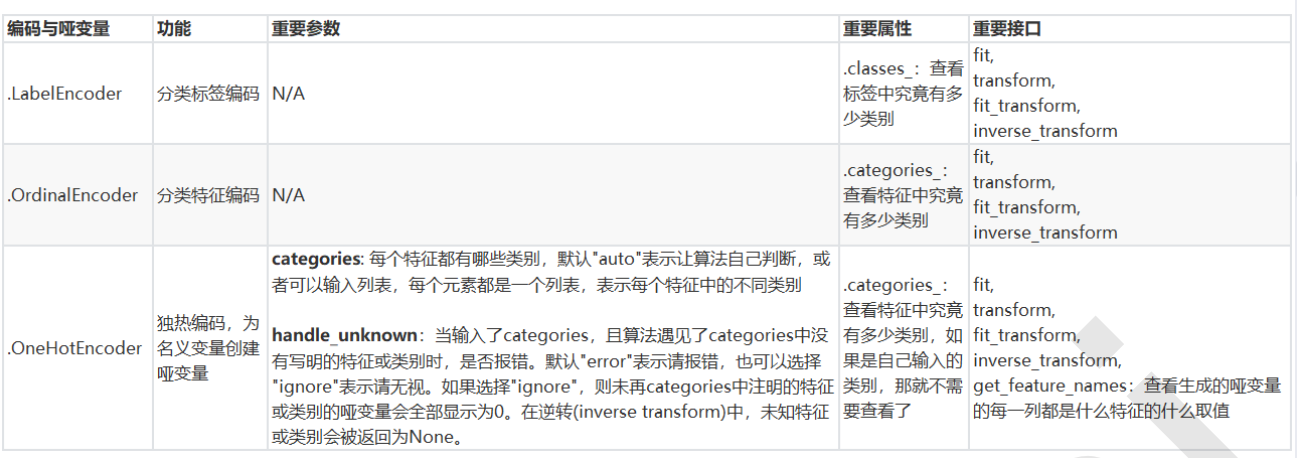
1 处理分类型特征:编码与哑变量

from sklearn.preprocessing import LabelEncoder y = data.iloc[:,-1] #要输入的是标签,不是特征矩阵,所以允许一维 le = LabelEncoder() #实例化 le = le.fit(y) #导入数据 label = le.transform(y) #transform接口调取结果 le.classes_ #属性.classes_查看标签中究竟有多少类别 label #查看获取的结果label le.fit_transform(y) #也可以直接fit_transform一步到位 le.inverse_transform(label) #使用inverse_transform可以逆转 data.iloc[:,-1] = label #让标签等于我们运行出来的结果 data.head() #如果不需要教学展示的话我会这么写: from sklearn.preprocessing import LabelEncoder data.iloc[:,-1] = LabelEncoder().fit_transform(data.iloc[:,-1])

from sklearn.preprocessing import OrdinalEncoder #接口categories_对应LabelEncoder的接口classes_,一模一样的功能 data_ = data.copy() data_.head() OrdinalEncoder().fit(data_.iloc[:,1:-1]).categories_ data_.iloc[:,1:-1] = OrdinalEncoder().fit_transform(data_.iloc[:,1:-1]) data_.head()




data.head() from sklearn.preprocessing import OneHotEncoder X = data.iloc[:,1:-1] enc = OneHotEncoder(categories='auto').fit(X) result = enc.transform(X).toarray() result #依然可以直接一步到位,但为了给大家展示模型属性,所以还是写成了三步 OneHotEncoder(categories='auto').fit_transform(X).toarray() #依然可以还原 pd.DataFrame(enc.inverse_transform(result)) enc.get_feature_names() result result.shape #axis=1,表示跨行进行合并,也就是将量表左右相连,如果是axis=0,就是将量表上下相连 newdata = pd.concat([data,pd.DataFrame(result)],axis=1) newdata.head() newdata.drop(["Sex","Embarked"],axis=1,inplace=True) newdata.columns = ["Age","Survived","Female","Male","Embarked_C","Embarked_Q","Embarked_S"] newdata.head()


2 处理连续型特征:二值化与分段

#将年龄二值化 data_2 = data.copy() from sklearn.preprocessing import Binarizer X = data_2.iloc[:,0].values.reshape(-1,1) #类为特征专用,所以不能使用一维数组 transformer = Binarizer(threshold=30).fit_transform(X) transformer

from sklearn.preprocessing import KBinsDiscretizer X = data.iloc[:,0].values.reshape(-1,1) est = KBinsDiscretizer(n_bins=3, encode='ordinal', strategy='uniform') est.fit_transform(X) #查看转换后分的箱:变成了一列中的三箱 set(est.fit_transform(X).ravel()) est = KBinsDiscretizer(n_bins=3, encode='onehot', strategy='uniform') #查看转换后分的箱:变成了哑变量 est.fit_transform(X).toarray()