1 概述
1.1 集成算法概述
集成学习(ensemble learning)是时下非常流行的机器学习算法,它本身不是一个单独的机器学习算法,而是通过在数据上构建多个模型,集成所有模型的建模结果。基本上所有的机器学习领域都可以看到集成学习的身影,在现实中集成学习也有相当大的作用,它可以用来做市场营销模拟的建模,统计客户来源,保留和流失,也可用来预测疾病的风险和病患者的易感性。在现在的各种算法竞赛中,随机森林,梯度提升树(GBDT),Xgboost等集成算法的身影也随处可见,可见其效果之好,应用之广。
集成算法的目标
集成算法会考虑多个评估器的建模结果,汇总之后得到一个综合的结果,以此来获取比单个模型更好的回归或分类表现。
多个模型集成成为的模型叫做集成评估器(ensemble estimator),组成集成评估器的每个模型都叫做基评估器(base estimator)。通常来说,有三类集成算法:装袋法(Bagging),提升法(Boosting)和stacking。

装袋法的核心思想是构建多个相互独立的评估器,然后对其预测进行平均或多数表决原则来决定集成评估器的结果。装袋法的代表模型就是随机森林。
提升法中,基评估器是相关的,是按顺序一一构建的。其核心思想是结合弱评估器的力量一次次对难以评估的样本进行预测,从而构成一个强评估器。提升法的代表模型有Adaboost和梯度提升树。
2 sklearn中的集成算法
sklearn中的集成算法模块ensemble

集成算法中,有一半以上都是树的集成模型,可以想见决策树在集成中必定是有很好的效果。在这堂课中,我们会以随机森林为例,慢慢为大家揭开集成算法的神秘面纱
复习:sklearn中的决策树
在开始随机森林之前,我们先复习一下决策树。决策树是一种原理简单,应用广泛的模型,它可以同时被用于分类和回归问题。决策树的主要功能是从一张有特征和标签的表格中,通过对特定特征进行提问,为我们总结出一系列决策规则,并用树状图来呈现这些决策规则。
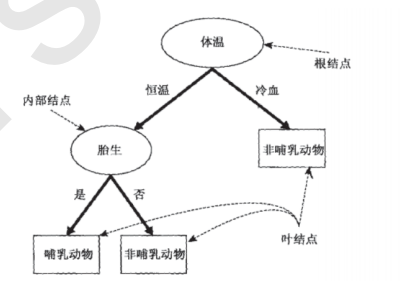
决策树的核心问题有两个,一个是如何找出正确的特征来进行提问,即如何分枝,二是树生长到什么时候应该停下。
对于第一个问题,我们定义了用来衡量分枝质量的指标不纯度,分类树的不纯度用基尼系数或信息熵来衡量,回归树的不纯度用MSE均方误差来衡量。每次分枝时,决策树对所有的特征进行不纯度计算,选取不纯度最低的特征进行分枝,分枝后,又再对被分枝的不同取值下,计算每个特征的不纯度,继续选取不纯度最低的特征进行分枝。

每分枝一层,树整体的不纯度会越来越小,决策树追求的是最小不纯度。因此,决策树会一致分枝,直到没有更多的特征可用,或整体的不纯度指标已经最优,决策树就会停止生长。
决策树非常容易过拟合,这是说,它很容易在训练集上表现优秀,却在测试集上表现很糟糕。为了防止决策树的过拟合,我们要对决策树进行剪枝,sklearn中提供了大量的剪枝参数,我们一会儿会带大家复习一下。