第五期 一些补充
101.从CSV文件中读取指定数据
#备注 从数据1中的前10行中读取positionName, salary两列
df = pd.read_csv('数据1.csv',encoding='gbk', usecols=['positionName', 'salary'],nrows = 10)
df

102.从CSV文件中读取指定数据
#备注 从数据2中读取数据并在读取数据时将薪资大于10000的为改为高
df = pd.read_csv('数据2.csv',converters={'薪资水平': lambda x: '高' if float(x) > 10000 else '低'} )
df

103.从上一题数据中,对薪资水平列每隔20行进行一次抽样
df.iloc[::20, :][['薪资水平']]

104.将数据取消使用科学计数法
#输入
df = pd.DataFrame(np.random.random(10)**10, columns=['data'])
df
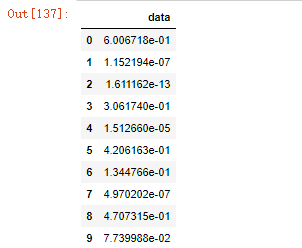

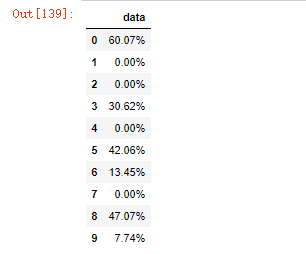
105.将上一题的数据转换为百分数
df.style.format({'data': '{0:.2%}'.format})
106.查找上一题数据中第3大值的行号
df['data'].argsort()[::-1][7]

107.反转df的行
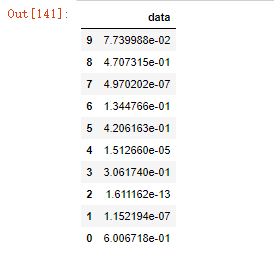
108.按照多列对数据进行合并
#输入
df1= pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
df2= pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
pd.merge(df1, df2, on=['key1', 'key2'])

109.按照多列对数据进行合并
pd.merge(df1, df2, how='left', on=['key1', 'key2'])

110.再次读取数据1并显示所有的列
df = pd.read_csv('数据1.csv',encoding='gbk')
pd.set_option("display.max.columns", None)
df

111.查找secondType与thirdType值相等的行号
np.where(df.secondType == df.thirdType)

112.查找薪资大于平均薪资的第三个数据
np.argwhere(df['salary'] > df['salary'].mean())[2]

113.将上一题数据的salary列开根号
df[['salary']].apply(np.sqrt)

114.将上一题数据的linestaion列按_拆分
df['split'] = df['linestaion'].str.split('_')
115.查看上一题数据中一共有多少列

116.提取industryField列以'数据'开头的行
df[df['industryField'].str.startswith('数据')]
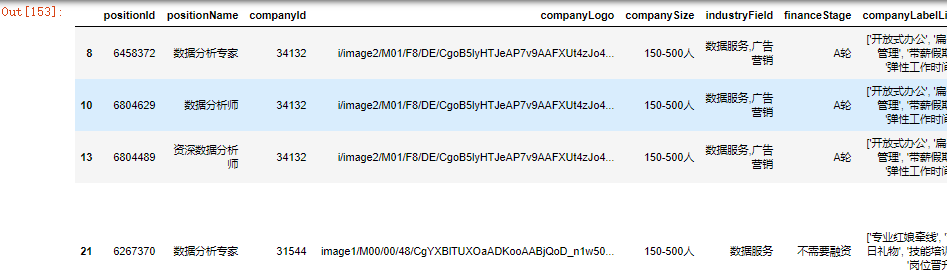
117.按列制作数据透视表
pd.pivot_table(df,values=["salary","score"],index="positionId")
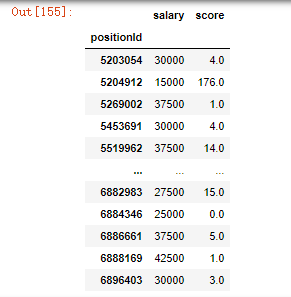
118.同时对salary、score两列进行计算
df[["salary","score"]].agg([np.sum,np.mean,np.min])
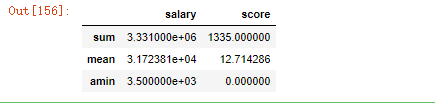
119.对salary求平均,对score列求和
df.agg({"salary":np.sum,"score":np.mean})

120.计算并提取平均薪资最高的区
df[['district','salary']].groupby(by='district').mean().sort_values('salary',ascending=False).head(1)
