3 特征工程
3.1 特征变换
import warnings warnings.filterwarnings("ignore") # 所有的数值数据拿到手 numeric_subset = data.select_dtypes('number') # 遍历所有的数值数据 for col in numeric_subset.columns: # 如果score就是y值 ,就不做任何变换 if col == 'score': next #剩下的不是y的话特征做log和开根号 else: numeric_subset['sqrt_' + col] = np.sqrt(numeric_subset[col]) numeric_subset['log_' + col] = np.log(numeric_subset[col]) # Borough:自治镇 # Largest Property Use Type: categorical_subset = data[['Borough', 'Largest Property Use Type']] # One hot encode用到了读热编码get_dummies categorical_subset = pd.get_dummies(categorical_subset) # 合并数组 一个是数值的, 一个热度编码的 features = pd.concat([numeric_subset, categorical_subset], axis = 1) features = features.dropna(subset = ['score']) # sort_values()做一下排序 correlations = features.corr()['score'].dropna().sort_values()
#sqrt结尾的变幻后就是sqrt_,log结尾的变幻后就是log_ # 这些都是负的 correlations.head(15) #Weather Normalized Site EUI (kBtu/ft²)和转换后sqrt_Weather Normalized Site EUI (kBtu/ft²)没啥变化,所以没有价值 #都差不多,没有明显的趋势,
Site EUI (kBtu/ft²) -0.723864 Weather Normalized Site EUI (kBtu/ft²) -0.713993 sqrt_Site EUI (kBtu/ft²) -0.699817 sqrt_Weather Normalized Site EUI (kBtu/ft²) -0.689019 sqrt_Weather Normalized Source EUI (kBtu/ft²) -0.671044 sqrt_Source EUI (kBtu/ft²) -0.669396 Weather Normalized Source EUI (kBtu/ft²) -0.645542 Source EUI (kBtu/ft²) -0.641037 log_Source EUI (kBtu/ft²) -0.622892 log_Weather Normalized Source EUI (kBtu/ft²) -0.620329 log_Site EUI (kBtu/ft²) -0.612039 log_Weather Normalized Site EUI (kBtu/ft²) -0.601332 log_Weather Normalized Site Electricity Intensity (kWh/ft²) -0.424246 sqrt_Weather Normalized Site Electricity Intensity (kWh/ft²) -0.406669 Weather Normalized Site Electricity Intensity (kWh/ft²) -0.358394 Name: score, dtype: float64
# 后15位下面是正的 correlations.tail(15)
sqrt_Order 0.028662 Borough_Queens 0.029545 Largest Property Use Type_Supermarket/Grocery Store 0.030038 Largest Property Use Type_Residence Hall/Dormitory 0.035407 Order 0.036827 Largest Property Use Type_Hospital (General Medical & Surgical) 0.048410 Borough_Brooklyn 0.050486 log_Community Board 0.055495 Community Board 0.056612 sqrt_Community Board 0.058029 sqrt_Council District 0.060623 log_Council District 0.061101 Council District 0.061639 Largest Property Use Type_Office 0.158484 score 1.000000 Name: score, dtype: float64
3.2 双变量绘图

import warnings warnings.filterwarnings("ignore") figsize(12, 10) # 能源得分与城镇区域之间的关系 features['Largest Property Use Type'] = data.dropna(subset = ['score'])['Largest Property Use Type'] # Largest Property Use Type 最大财产使用类型 ,isin()接受一个列表,判断该列中4个属性是否在列表中 features = features[features['Largest Property Use Type'].isin(types)] # hue = 'Largest Property Use Type'是4个种类变量 ,4个颜色 sns.lmplot('Site EUI (kBtu/ft²)', 'score', # 种类变量,有4个种类,右下角hue是有4个种类变量, hue = 'Largest Property Use Type', data = features, scatter_kws = {'alpha': 0.8, 's': 60}, fit_reg = False, size = 12, aspect = 1.2); # Plot labeling plt.xlabel("Site EUI", size = 28) plt.ylabel('Energy Star Score', size = 28) plt.title('Energy Star Score vs Site EUI', size = 36);
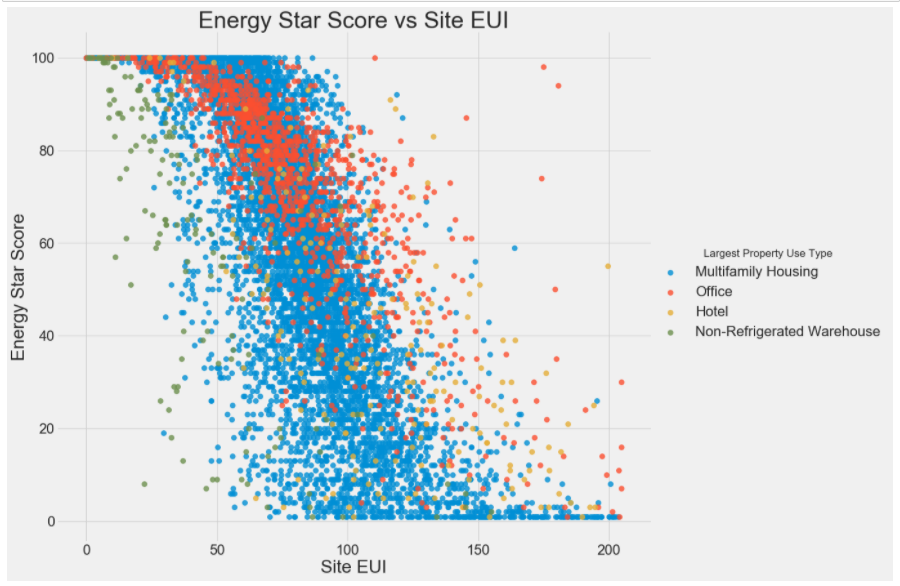

3.3 剔除共线特征

#原始数据备份一下copy(),修改后数据后保持原数据不变 features = data.copy() # select_dtypes():根据数据类型选择特征,number表示数值型特征 numeric_subset = data.select_dtypes('number') # 遍历特征是数值型在一个列表中 for col in numeric_subset.columns: # 跳过能源得分就是咱们的目标值Y if col == 'score': next else: #numeric_subset()从某一个列中选择出符合某条件的数据或是相关的列 numeric_subset['log_' + col] = np.log(numeric_subset[col]) # Borough:自治区镇 # 最大财产使用类型/多户家庭的a住宅区、办公区、酒店、不制冷的大仓库 categorical_subset = data[['Borough', 'Largest Property Use Type']] categorical_subset = pd.get_dummies(categorical_subset) #把所有数值型特征和治区镇以及最大财产的使用类型合并起来 features = pd.concat([numeric_subset, categorical_subset], axis = 1) features.shape#有110个列,比原来的列多
(11319, 110)

#Weather Normalized Site EUI (kBtu/ft²):天气正常指数的使用强度 #Site EUI:能源使用强度 plot_data = data[['Weather Normalized Site EUI (kBtu/ft²)', 'Site EUI (kBtu/ft²)']].dropna() #'bo':由点绘制的线 plt.plot(plot_data['Site EUI (kBtu/ft²)'], plot_data['Weather Normalized Site EUI (kBtu/ft²)'], 'bo') #横轴是天气正常指数的使用强度 、 纵轴是能源使用强度 plt.xlabel('Site EUI'); plt.ylabel('Weather Norm EUI') plt.title('Weather Norm EUI vs Site EUI, R = %0.4f' % np.corrcoef(data[['Weather Normalized Site EUI (kBtu/ft²)', 'Site EUI (kBtu/ft²)']].dropna(), rowvar=False)[0][1]);
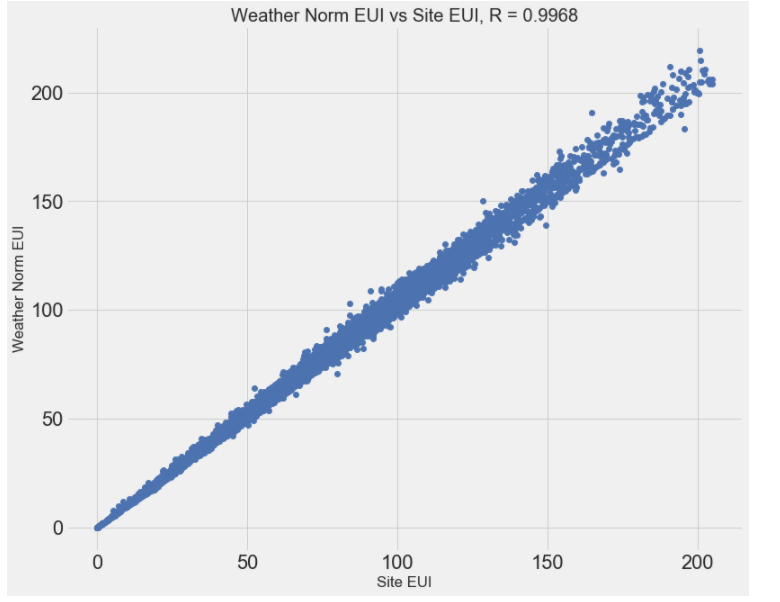
def remove_collinear_features(x, threshold): y = x['score'] #在原始数据X中”score“当做y值 x = x.drop(columns = ['score']) #除去标签值以外的当做特征 # 多长运行,直到相关性小于阈值才稳定结束 while True: # 计算一个矩阵 ,两两的相关系数 corr_matrix = x.corr() for i in range(len(corr_matrix)): corr_matrix.iloc[i][i] = 0 # 将对角线上的相关系数置为0。避免自己跟自己计算相关系数一定大于阈值 # 定义待删除的特征。 drop_cols = [] # col返回的是列名 for col in corr_matrix: if col not in drop_cols: # A和B比 ,B和A比的相关系数一样,避免AB全删了 # 取相关系数的绝对值。 v = np.abs(corr_matrix[col]) # 取的是每一列的相关系数 # 如果相关系数大于设置的阈值 if np.max(v) > threshold: # 取出最大值对应的索引。 name = np.argmax(v) # 找到最大值的的列名 drop_cols.append(name) # 列表不为空,就删除,列表为空,符合条件,退出循环 if drop_cols: # 删除想删除的列 x = x.drop(columns=drop_cols, axis=1) else: break # 指定标签 x['score'] = y return x
# 设置阈值0.6 ,tem.values相关性的矩阵的向量大于0.6的 features = remove_collinear_features(features, 0.6);
# 删除 features = features.dropna(axis=1, how = 'all') features.shape #原来时110
(11319, 68)
features.shape
(11319, 68)
4 分割数据集
4.1 划分数据
# pandas:isna(): 如果参数的结果为#NaN, 则结果TRUE, 否则结果是FALSE。 no_score = features[features['score'].isna()] # pandas:notnull()判断是否不是NaN score = features[features['score'].notnull()] print(no_score.shape) print(score.shape)
(1858, 68) (9461, 68)
features = score.drop(columns='score') targets = pd.DataFrame(score['score']) #np.inf :最大值 -np.inf:最小值 features = features.replace({np.inf: np.nan, -np.inf: np.nan}) X, X_test, y, y_test = train_test_split(features, targets, test_size = 0.3, random_state = 42) print(X.shape) print(X_test.shape) print(y.shape) print(y_test.shape)
(6622, 67) (2839, 67) (6622, 1) (2839, 1)
4.2 建立Baseline

# mae平均的绝对值 ,就是 (真实值 - 预测值) / n #abs():绝对值 def mae(y_true, y_pred): return np.mean(abs(y_true - y_pred))
- 如果用中位数来猜的话,结果是多少。
baseline_guess = np.median(y) print('The baseline guess is a score of %0.2f' % baseline_guess) # 中位数为66 print("Baseline Performance on the test set: MAE = %0.4f" % mae(y_test, baseline_guess)) # MAE = 24.5164
The baseline guess is a score of 66.00 Baseline Performance on the test set: MAE = 24.5164
4.3 结果保存下来,建模再用
# Save the no scores, training, and testing data no_score.to_csv('data/no_score.csv', index = False) X.to_csv('data/training_features.csv', index = False) X_test.to_csv('data/testing_features.csv', index = False) y.to_csv('data/training_labels.csv', index = False) y_test.to_csv('data/testing_labels.csv', index = False)
