0 简介
本次将介绍使用了真实数据集的机器学习项目的完整解决方案,让同学们的了解所有碎片是如何拼接在一起的。
编码之前是了解我们试图解决的问题和可用的数据。在这个项目中,我们将使用公共可用的纽约市的建筑能源数据。目标是使用能源数据建立一个模型,来预测建筑物的 Energy star Score (能源之星分数),并解释结果以找出影晌评分的因素。
数据包括 Energy star Score ,意味着这是一个监督回归机餐学习任务:监督:我们可以知道数据的特征和目标,我们的目标是训练可以学习两者之间映射关系的模型。回归: Energy Star Score 是一个连续变量。我们想要开发一个模型准确性,它可以实现预测Energy Star Score,并且结果接近班实值。
1 数据清洗与格式转换
1.1 数据简介


1.2 导入所需的基本工具包
import pandas as pd import numpy as np # API需要升级或者遗弃了,不想看就设置一下warning pd.options.mode.chained_assignment = None # 经常用到head(),最多展示多少条数 pd.set_option('display.max_columns', 60) import matplotlib.pyplot as plt %matplotlib inline #绘图全局的设置好了,画图字体大小 plt.rcParams['font.size'] = 24 from IPython.core.pylabtools import figsize import seaborn as sns sns.set(font_scale = 2) from sklearn.model_selection import train_test_split import warnings warnings.filterwarnings("ignore")
1.3 数据分析
# 加载数据 data = pd.read_csv('data/Energy.csv') # 展示前3行 data.head(3)
1.4 数据类型与缺失值
data.info() # 可以快速让我们知道数据类型与缺失值
1.5 缺失值处理模板
# 缺失值Not Available转换为np.nan #replace():描述Python replace() 方法把字符串中的 old(旧字符串) 替换成 new(新字符串), data = data.replace({'Not Available': np.nan}) #在原始数据中‘ft²’结尾的列中的属性显示的是有的是数值型float类型,但是在python环境中info()函数展示有其他类型的数据都是Object类型 #kBtu/ft²等本应该是float类型,在这里是object类型,所以要转换一下 ,以ft²、kBtu、Metric Tons CO2e等为结尾的astype一下float for col in list(data.columns): # 如果ft^2平方英尺结尾的,本来是object强制转换为float if ('ft²' in col or 'kBtu' in col or 'Metric Tons CO2e' in col or 'kWh' in col or 'therms' in col or 'gal' in col or 'Score' in col): data[col] = data[col].astype(float)
# 每列中只能展示数值型的count、mean、sdt等等,object不会展示 data.describe() # 3.20e+05=3.20x10^5=3.20x100000=320000 # 在科学计数法中,为了使公式简便,可以用带“E”的格式表示。当用该格式表示时,E前面的数字和“E+”后面要精确到十分位,(位数不够末尾补0),例如7.8乘10的7次方,正常写法为:7.8x10^7,简写为“7.8E+07”的形式
# 缺失值的模板,通用的 # 定义一个函数,传进来一个DataFrame def missing_values_table(df): # python的pandas库中有一个十分便利的isnull()函数,它可以用来判断缺失值,把每列的缺失值算一下总和 mis_val = df.isnull().sum() # 100相当于%,每列的缺失值的占比 mis_val_percent = 100 * df.isnull().sum() / len(df) # 每列缺失值的个数 、 每列缺失值的占比做成表 mis_val_table = pd.concat([mis_val, mis_val_percent], axis=1) # 重命名指定列的名称 mis_val_table_ren_columns = mis_val_table.rename( columns = {0 : 'Missing Values', 1 : '% of Total Values'}) # 因为第1列缺失值很大,ascending=False代表降序 #iloc[:,1] != 0的意思是对于下面的表中的第2列(缺失的占比)进行降序,从大到小 mis_val_table_ren_columns = mis_val_table_ren_columns[ mis_val_table_ren_columns.iloc[:,1] != 0].sort_values( '% of Total Values', ascending=False).round(1) # 打印所有列的个数 、 缺失了多少列 print ("Your selected dataframe has " + str(df.shape[1]) + " columns. " "There are " + str(mis_val_table_ren_columns.shape[0]) + " columns that have missing values.") return mis_val_table_ren_columns
missing_values_table(data) #第一列是每1列,第二列是缺失值个数,第三列是缺失值%比,一共是60列,有46列是有缺失值
Your selected dataframe has 60 columns. There are 46 columns that have missing values.
# 50%是阈值,大于50%的列 missing_df = missing_values_table(data); # 大于50%的列拿出来 ,后面drop()删掉 missing_columns = list(missing_df[missing_df['% of Total Values'] > 50].index) print('We will remove %d columns.' % len(missing_columns)) #原始的列中有60列,发现有缺失值的列有46列 , 缺失的46列中大于50%的将删除,有11列
Your selected dataframe has 60 columns. There are 46 columns that have missing values. We will remove 11 columns.
# 大于50%的列都drop掉 data = data.drop(columns = list(missing_columns))
2 Exploratory Data Analysis

2.1 单变量绘图
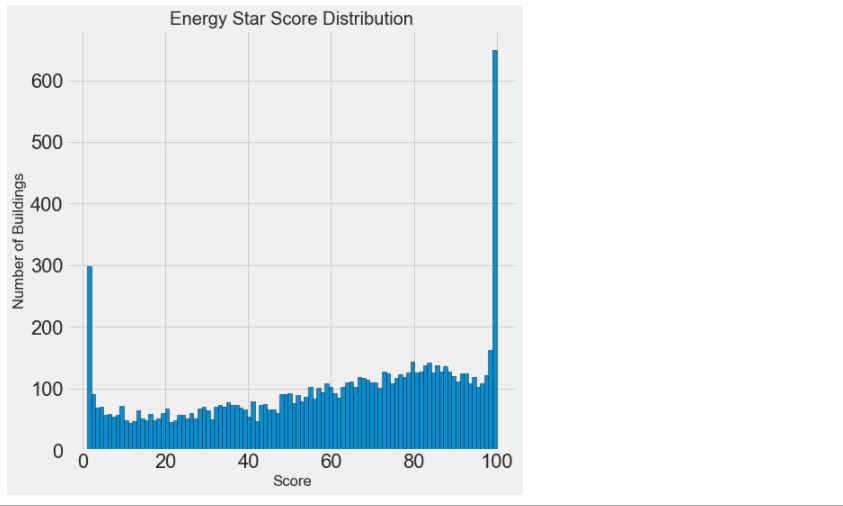
figsize(8, 8) # Y,就是从1~100的能源得分值,重命名为score data = data.rename(columns = {'ENERGY STAR Score': 'score'}) # 在seaboard中找到不同的风格 plt.style.use('fivethirtyeight') #dropna():该函数主要用于滤除缺失数据 plt.hist(data['score'].dropna(), bins = 100, edgecolor = 'k'); plt.xlabel('Score'); plt.ylabel('Number of Buildings'); plt.title('Energy Star Score Distribution'); #在展示的图中,1和100的得分比较高,原始数据都是物业自己填的报表打得分,根据实际情况,给房屋的能源利用率打的分值,人为填的, #所以1和100,得分很高,有水分,但是,我们的目标只是预测分数,而不是设计更好的建筑物评分方法! 我们可以在我们的报告中记下分数具有可疑分布,但我们主要关注预测分数。

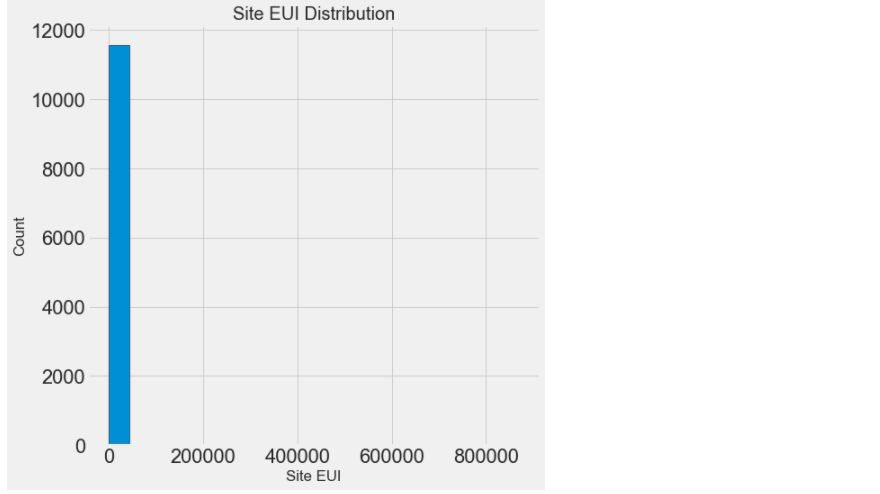
# Site EUI (kBtu/ft²:能源使用强度 figsize(8, 8) plt.hist(data['Site EUI (kBtu/ft²)'].dropna(), bins = 20, edgecolor = 'black'); # 边也是黑色 plt.xlabel('Site EUI'); plt.ylabel('Count'); plt.title('Site EUI Distribution'); #这显示我们有另一个问题:!由于存在几个非常高分的建筑物,这张图难以置信地倾斜了。所以必须进行异常值处理。 #你会很清楚地看到最后一个值异常大。出现异常值的原因很多:错字,测量设备故障,错误的单位,或者它们可能是合法的但是个极端值 #相当于分一下数据有很多点离均值很远,就有离群点
data['Site EUI (kBtu/ft²)'].describe() # 均值mean小 , 标准差很大,就意味着有很多点离均值很远,就有离群点 ,因为最小值为0,最大值为869265
count 11583.000000 mean 280.071484 std 8607.178877 min 0.000000 25% 61.800000 50% 78.500000 75% 97.600000 max 869265.000000 Name: Site EUI (kBtu/ft²), dtype: float64
平均值为280,标准差8607,std非常大了,意味着有些数据离大多数围绕均值范围的比较远,最小值为0,最大值为 869265,这才画的很奇怪。
#dropna()该函数主要用于滤除缺失数据 # sort_values()先分组 ,再看后10位 #能源使用强度(EUI) #sort_values():默认是升序 ,从小到大排序,按值排序,左边是行号,右边是数据 data['Site EUI (kBtu/ft²)'].dropna().sort_values().tail(10)
3173 51328.8 3170 51831.2 3383 78360.1 8269 84969.6 3263 95560.2 8268 103562.7 8174 112173.6 3898 126307.4 7 143974.4 8068 869265.0 Name: Site EUI (kBtu/ft²), dtype: float64
存在着一些特别大的值,因为均值才280,这些可能是离群点或记录错误点,对我们结果会有一些影响的。 可以拿过来看一看,但是这份数据看起来有点难,还是按照常规方法来过滤离群点吧。
# 怎么过滤离群点呢,查看第869265行 data.loc[data['Site EUI (kBtu/ft²)'] == 869265, :]
2.2 剔除离群点

# 在describe取25%和75%分位 first_quartile = data['Site EUI (kBtu/ft²)'].describe()['25%'] third_quartile = data['Site EUI (kBtu/ft²)'].describe()['75%'] # 2者一减就是IQ值,就是间隔 iqr = third_quartile - first_quartile #在这里判断的是正常数据,Q3 - 3IQ < EUI < Q3+ 3IQ ,保留正常数据,剩下的过滤异常点 # Q3+ 3IQ > 。。。。。。>Q3 - 3IQ ,中间的就是非离群点,就是咱们想要的数据 data = data[(data['Site EUI (kBtu/ft²)'] > (first_quartile - 3 * iqr)) & (data['Site EUI (kBtu/ft²)'] < (third_quartile + 3 * iqr))]
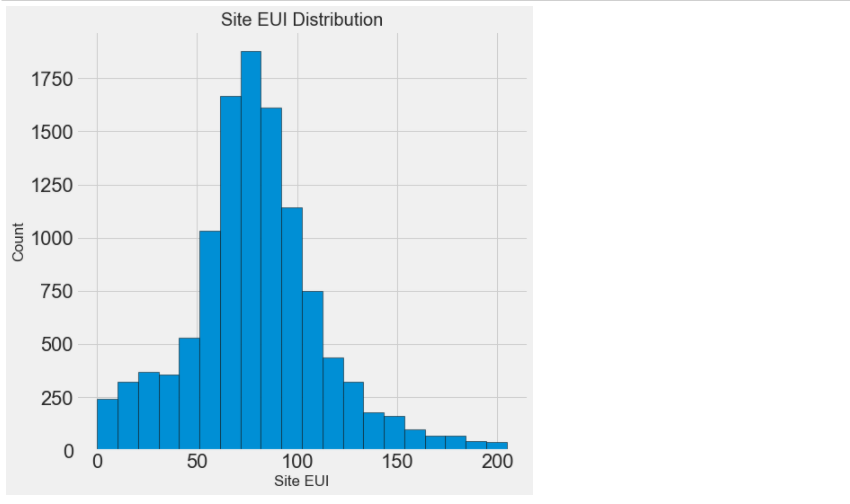
# #能源使用强度(EUI),剔除离群点后应该有的正太分布 figsize(8, 8) plt.hist(data['Site EUI (kBtu/ft²)'].dropna(), bins = 20, edgecolor = 'black'); plt.xlabel('Site EUI'); plt.ylabel('Count'); plt.title('Site EUI Distribution');
剔除离群点之后,再来看看分布情况
2.3.观察哪些变量会对结果产生影响
types = data.dropna(subset=['score']) #Largest Property Use Type:最大财产使用类型 #该列中有很多的个属性,大于100的值分别有4个属性 , 为:Multifamily Housing——多户住宅区 、 Office——办公室 、 Hotel——酒店 #Data Center, Non-Refrigerated Warehouse, Office——数据中心、非冷藏仓库、办公室 types = types['Largest Property Use Type'].value_counts() types = list(types[types.values > 100].index)
# 找出差异大的2个选取特征 #Largest Property Use Type:最大财产使用类型 figsize(12, 10) # b_type是变量,types是4种类型 for b_type in types: #当前Largest Property Use Type就是画的类型b_type4个 变量 subset = data[data['Largest Property Use Type'] == b_type] # 拿到subset的得分值,alpha指的是透明度 sns.kdeplot(subset['score'].dropna(), label = b_type, shade = False, alpha = 0.8); # 横轴是能源得分 ,纵轴是密度 plt.xlabel('Energy Star Score', size = 20); plt.ylabel('Density', size = 20); plt.title('Density Plot of Energy Star Scores by Building Type', size = 28); #红色和黄色差距很大

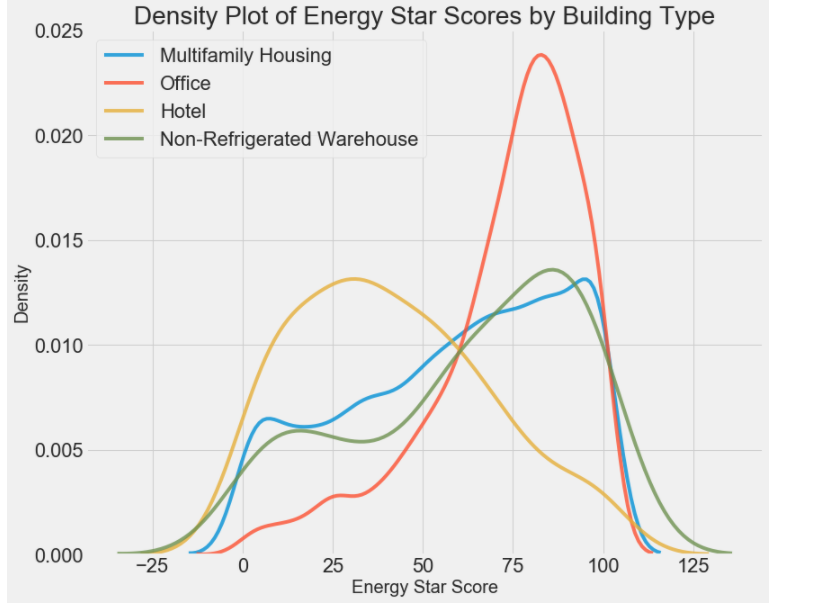
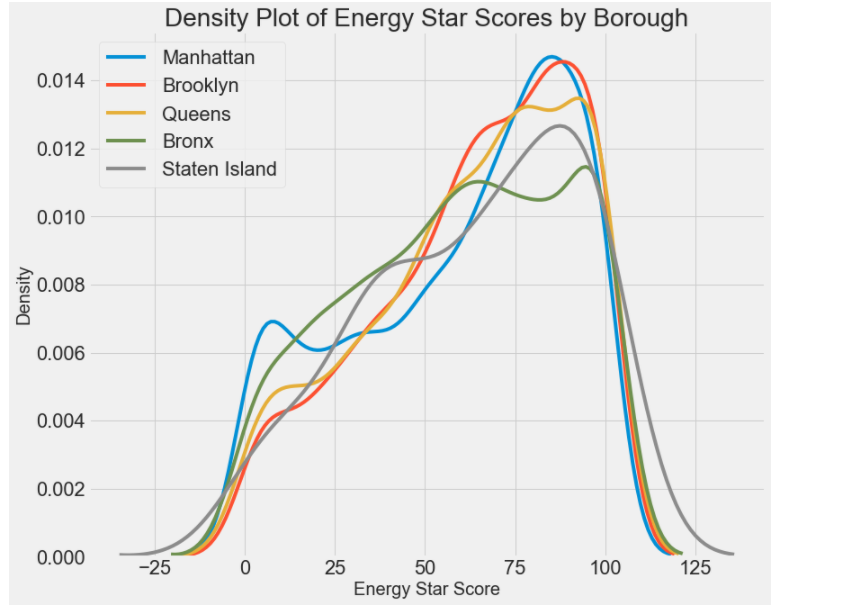
# 查看当前的结果跟地区有什么结果 结果 boroughs = data.dropna(subset=['score']) # 地区 boroughs = boroughs['Borough'].value_counts() boroughs = list(boroughs[boroughs.values > 100].index)

# 4个从差异程度来说,影响不大,特征的差异性不强 #Borough:自治区镇 ,该列中有5个属性,分别为:Manhattan——曼哈顿 、 Brooklyn——布鲁克林 、 Queens——皇后区 、 Bronx——布朗克斯 # Staten Island——斯塔顿岛 figsize(12, 10) # 遍历5个属性遍历,画出图,横轴是能源得分、纵轴是密度 for borough in boroughs: subset = data[data['Borough'] == borough] sns.kdeplot(subset['score'].dropna(), label = borough); plt.xlabel('Energy Star Score', size = 20); plt.ylabel('Density', size = 20); plt.title('Density Plot of Energy Star Scores by Borough', size = 28);

# corr()相关系数矩阵,即给出任意X与Y之间的相关系数 X——>Y两两相关的,负相关多,-0.046605接近于0的都删掉 , 正相关的少 correlations_data = data.corr()['score'].sort_values()#升序,从小到大 # 后10个 print(correlations_data.head(10), ' ') print("---------------------------") # 前10个 print(correlations_data.tail(10))
Site EUI (kBtu/ft²) -0.723864 Weather Normalized Site EUI (kBtu/ft²) -0.713993 Weather Normalized Source EUI (kBtu/ft²) -0.645542 Source EUI (kBtu/ft²) -0.641037 Weather Normalized Site Electricity Intensity (kWh/ft²) -0.358394 Weather Normalized Site Natural Gas Intensity (therms/ft²) -0.346046 Direct GHG Emissions (Metric Tons CO2e) -0.147792 Weather Normalized Site Natural Gas Use (therms) -0.135211 Natural Gas Use (kBtu) -0.133648 Year Built -0.121249 Name: score, dtype: float64 --------------------------- Water Use (All Water Sources) (kgal) -0.013681 Water Intensity (All Water Sources) (gal/ft²) -0.012148 Census Tract -0.002299 DOF Gross Floor Area 0.013001 Property GFA - Self-Reported (ft²) 0.017360 Largest Property Use Type - Gross Floor Area (ft²) 0.018330 Order 0.036827 Community Board 0.056612 Council District 0.061639 score 1.000000 Name: score, dtype: float64