来源:https://mp.weixin.qq.com/s/_jZr9CIEtu92kE1r6XIFzA
导读:HiveSQL是数据仓库与数据分析过程中的必备技能,随着数据量增加,这一技能越来越重要,熟练应用的同时会带来效率的问题,
动辄十几亿的数据量如果处理不完善的话有可能导致一个作业运行几个小时,更严重的还有可能因占用过多资源而引发生产问题,所以HQL优化就变得非常重要。
本文我们就深入HQL的原理中,探索HQL优化的方法和逻辑。
1 group by的计算原理
SELECT uid, SUM(COUNT) FROM logs GROUP BY uid;
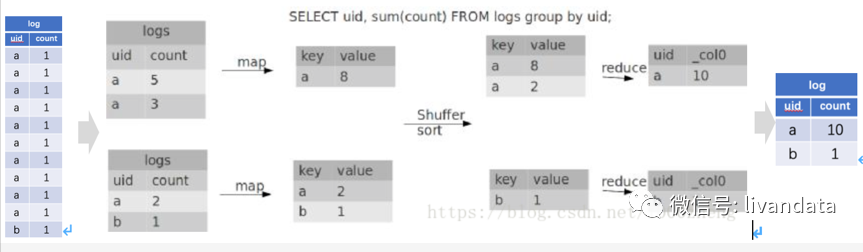
可以看到,group by本身不是全局变量,任务会被分到各个map中进行分组,然后再在reduce中聚合。
默认设置了hive.map.aggr=true,所以会在mapper端先group by一次,最后再把结果merge起来,为了减少reducer处理的数据量。注意看explain的mode是不一样的。
mapper是hash,reducer是mergepartial。如果把hive.map.aggr=false,那将groupby放到reducer才做,他的mode是complete。
优化点:
Group by主要是面对数据倾斜的问题。
很多聚合操作可以现在map端进行,最后在Reduce端完成结果输出:
Set hive.map.aggr = true;# 是否在Map端进行聚合,默认为true; Set hive.groupby.mapaggr.checkinterval = 1000000;# 在Map端进行聚合操作的条目数目;
当使用Group by有数据倾斜的时候进行负载均衡:
Set hive.groupby.skewindata = true;# hive自动进行负载均衡;
策略就是把MR任务拆分成两个MR Job:第一个先做预汇总,第二个再做最终汇总;
第一个Job:
Map输出结果集中缓存到maptask中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同Group by Key有可能被分到不同的reduce中,从而达到负载均衡的目的;
第二个Job:
根据第一阶段处理的数据结果按照group by key分布到reduce中,保证相同的group by key分布到同一个reduce中,最后完成最终的聚合操作。
2 join的优化原理
SELECT a.id,a.dept,b.age FROM a join b ON (a.id = b.id);

1)Map阶段:
读取源表的数据,Map输出时候以Join on条件中的列为key,如果Join有多个关联键,则以这些关联键的组合作为key;
Map输出的value为join之后所关心的(select或者where中需要用到的)列;同时在value中还会包含表的Tag信息,用于标明此value对应哪个表;
按照key进行排序;
2)Shuffle阶段:
根据key的值进行hash,并将key/value按照hash值推送至不同的reduce中,这样确保两个表中相同的key位于同一个reduce中。
3)Reduce阶段:
根据key的值完成join操作,期间通过Tag来识别不同表中的数据。
在多表join关联时:
如果 Join 的 key 相同,不管有多少个表,都会合并为一个Map-Reduce,例如:
SELECT pv.pageid, u.age FROM page_view p JOIN user u ON (pv.userid = u.userid) JOIN newuser x ON (u.userid = x.userid);
如果 Join 的 key不同,Map-Reduce 的任务数目和 Join 操作的数目是对应的,例如:
SELECT pv.pageid, u.age FROM page_view p JOIN user u ON (pv.userid = u.userid) JOIN newuser x on (u.age = x.age);
优化点:
1)应该将条目少的表/子查询放在 Join 操作符的左边。
2)我们知道文件数目大小,容易在文件存储端造成瓶颈,给HDFS 带来压力,影响处理效率。对此,可以通过合并Map和Reduce的结果文件来消除这样的影响。用于设置合并属性的参数有
合并Map输出文件:hive.merge.mapfiles=true(默认值为真) 合并Reduce端输出文件:hive.merge.mapredfiles=false(默认值为假) 合并文件的大小:hive.merge.size.per.task=256*1000*1000(默认值为 256000000)
3)Common join即普通的join,性能较差,因为涉及到了shuffle的过程(Hadoop/spark开发的过程中,有一个原则:能避免不使用shuffle就不使用shuffle),可以转化成map join。
hive.auto.convert.join=true;# 表示将运算转化成map join方式
使用的前提条件是需要的数据在 Map 的过程中可以访问到。
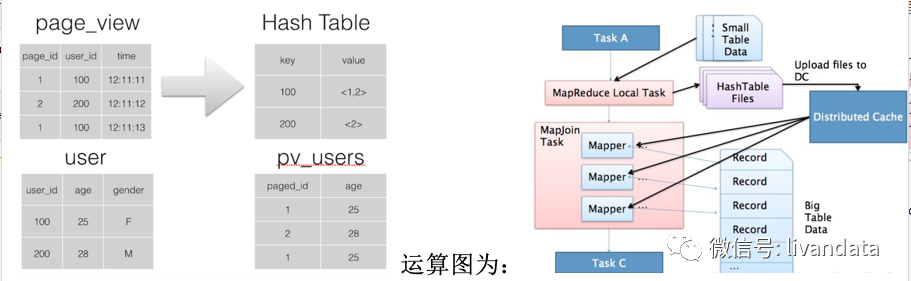
1)启动Task A:Task A去启动一个MapReduce的local task;通过该local task把small table data的数据读取进来;之后会生成一个HashTable Files;之后将该文件加载到分布式缓存(Distributed Cache)中来;
2)启动MapJoin Task:去读大表的数据,每读一个就会去和Distributed Cache中的数据去关联一次,关联上后进行输出。
整个阶段,没有reduce 和 shuffle,问题在于如果小表过大,可能会出现OOM。
3 Union与union all优化原理
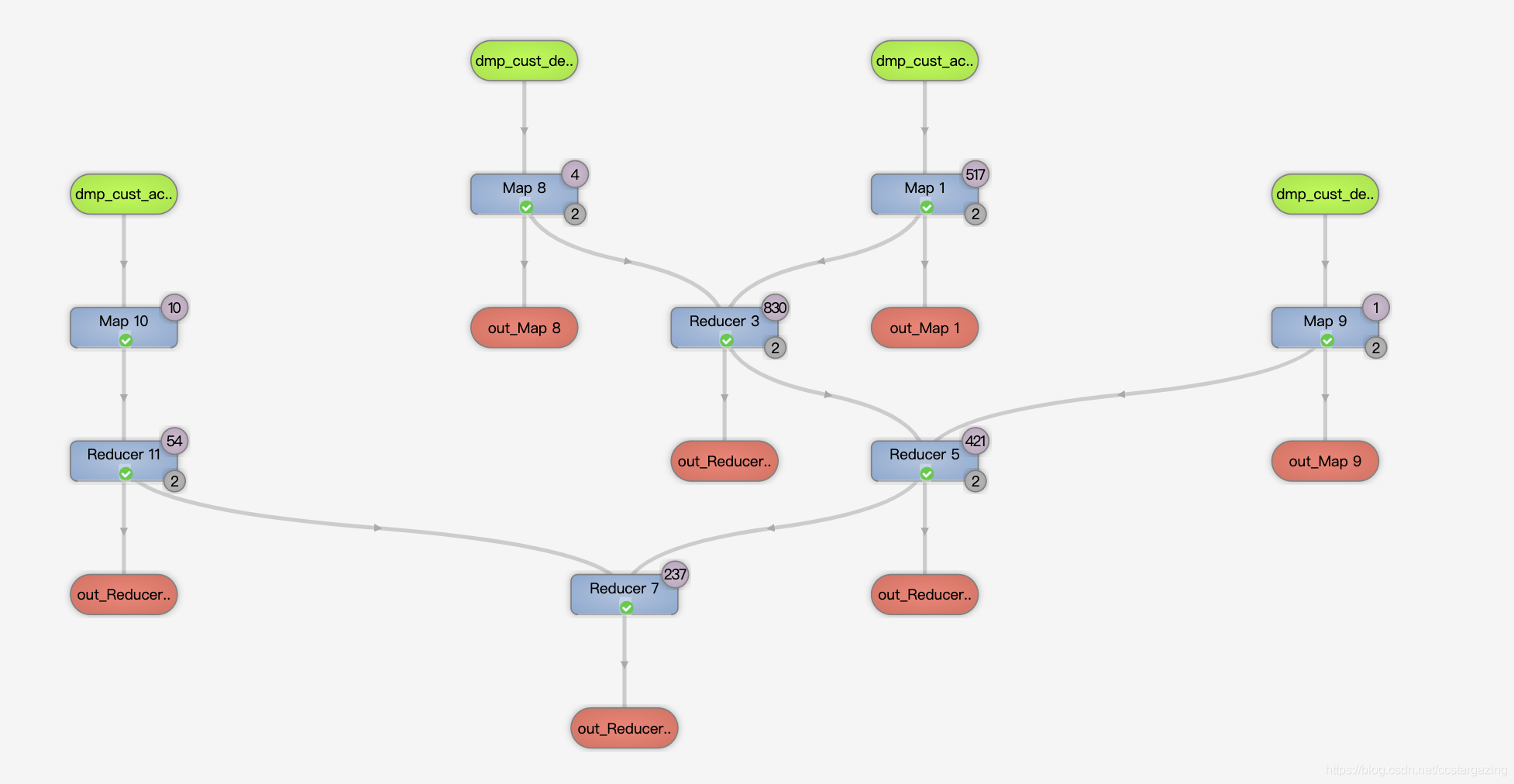
union将多个结果集合并为一个结果集,结果集去重。代码为:
select id,name from t1 union select id,name from t2 union select id,name from t3
对应的运行逻辑为:

union all将多个结果集合并为一个结果集,结果集不去重。使用时多与group by结合使用,代码为:
select all.id, all.name from( select id,name from t1 union all select id,name from t2 union all select id,name from t3 )all group by all.id ,all.name
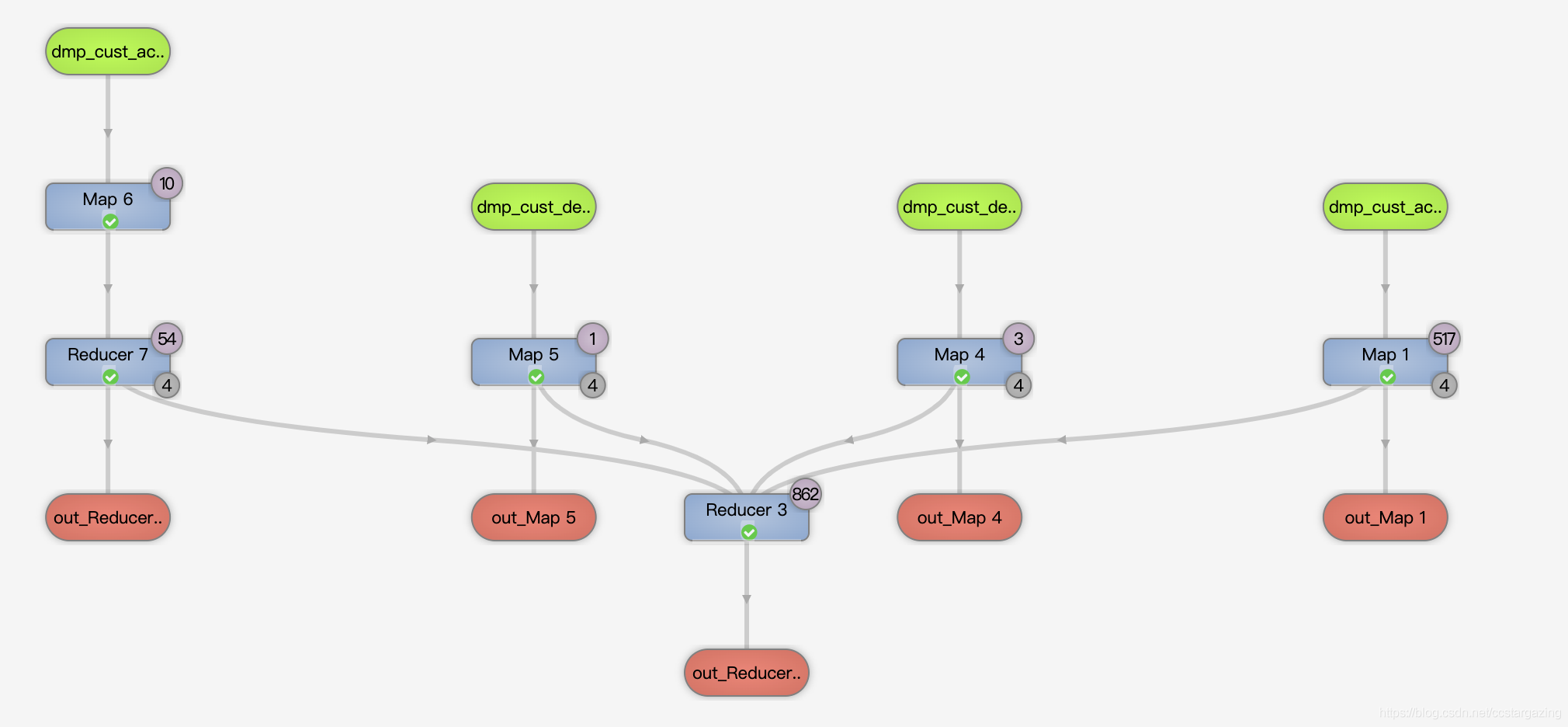
从上面的两个逻辑图可以看到,第二种写法性能要好。union写法每两份数据都要先合并去重一次,再和另一份数据合并去重,会产生较多次的reduce。第二种写法直接将所有数据合并再一次性去重。
对union all的操作除了与group by结合使用还有一些细节需要注意:
1)对 union all 优化只局限于非嵌套查询。
原代码:job有3个:
SELECT * FROM ( SELECT * FROM t1 GROUP BY c1,c2,c3 UNION ALL SELECT * FROM t2 GROUP BY c1,c2,c3 )t3 GROUP BY c1,c2,c3
这样的结构是不对的,应该修改为:job有1个:
这样的修改可以减少job数量,进而提高效率。
2)语句中出现count(distinct …)结构时:
原代码为:
SELECT * FROM ( SELECT * FROM t1 UNION ALL SELECT c1,c2,c3,COUNT(DISTINCT c4) FROM t2 GROUP BY c1,c2,c3 ) t3 GROUP BY c1,c2,c3;
修改为:(采用临时表消灭 COUNT(DISTINCT)作业不但能解决倾斜问题,还能有效减少jobs)。
INSERT t4 SELECT c1,c2,c3,c4 FROM t2 GROUP BY c1,c2,c3; SELECT c1,c2,c3,SUM(income),SUM(uv) FROM ( SELECT c1,c2,c3,income,0 AS uv FROM t1 UNION ALL SELECT c1,c2,c3,0 AS income,1 AS uv FROM t2 ) t3 GROUP BY c1,c2,c3;