

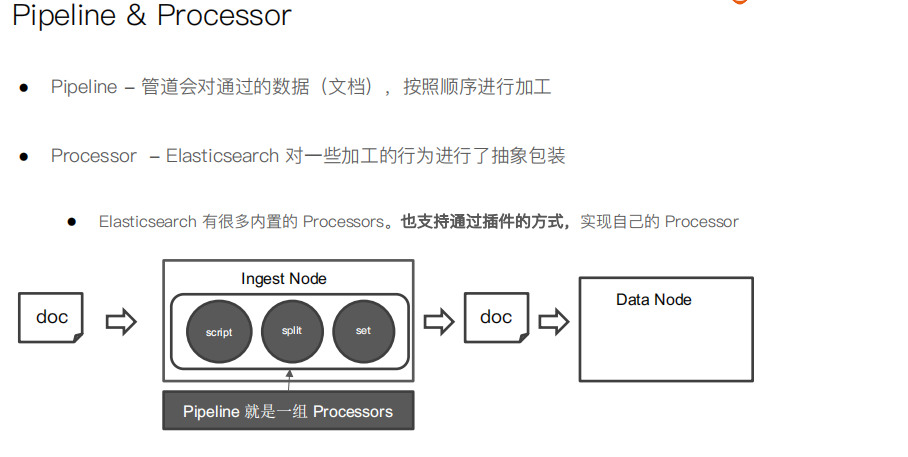



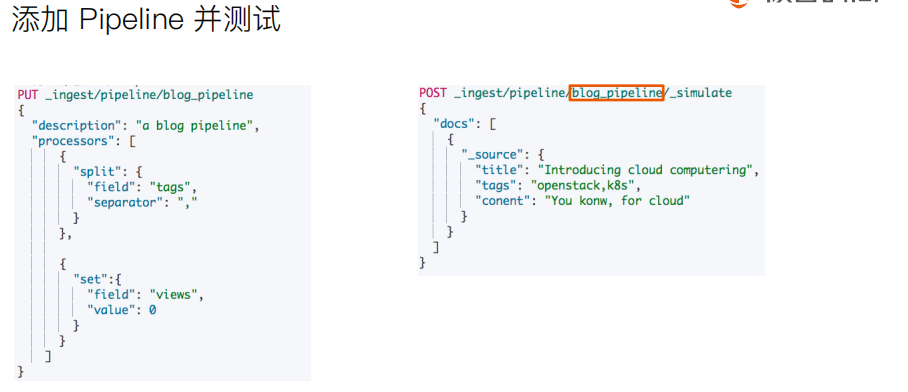







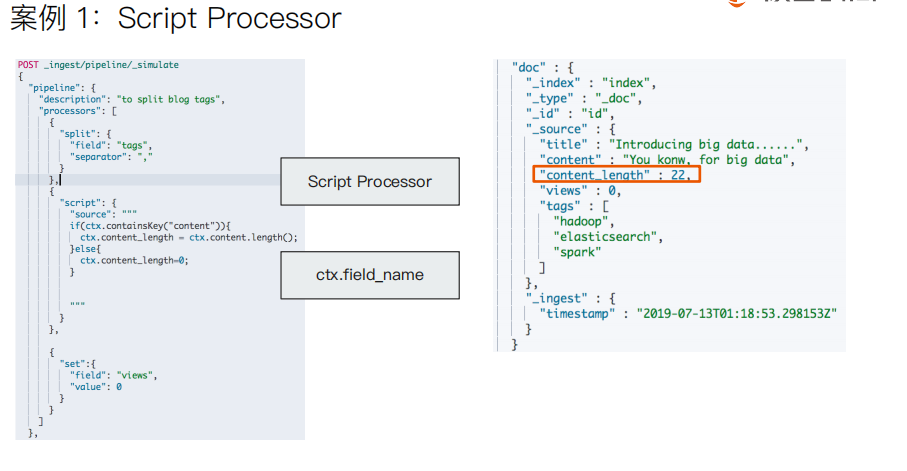


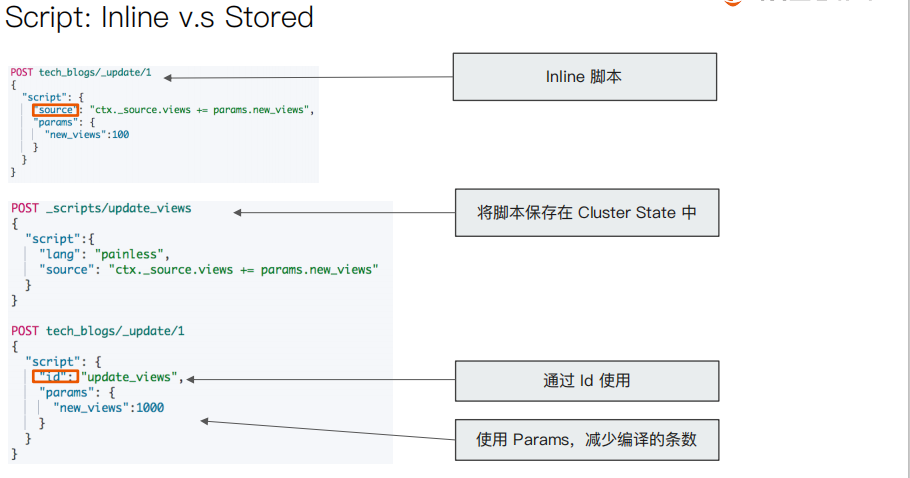
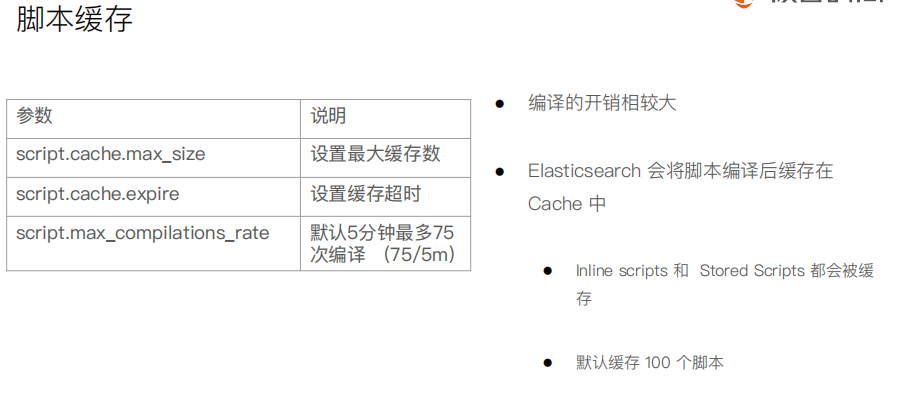

#########Demo for Pipeline############### DELETE tech_blogs #Blog数据,包含3个字段,tags用逗号间隔 PUT tech_blogs/_doc/1 { "title":"Introducing big data......", "tags":"hadoop,elasticsearch,spark", "content":"You konw, for big data" } # 测试split tags POST _ingest/pipeline/_simulate { "pipeline": { "description": "to split blog tags", "processors": [ { "split": { "field": "tags", "separator": "," } } ] }, "docs": [ { "_index": "index", "_id": "id", "_source": { "title": "Introducing big data......", "tags": "hadoop,elasticsearch,spark", "content": "You konw, for big data" } }, { "_index": "index", "_id": "idxx", "_source": { "title": "Introducing cloud computering", "tags": "openstack,k8s", "content": "You konw, for cloud" } } ] } #同时为文档,增加一个字段。blog查看量 POST _ingest/pipeline/_simulate { "pipeline": { "description": "to split blog tags", "processors": [ { "split": { "field": "tags", "separator": "," } }, { "set":{ "field": "views", "value": 0 } } ] }, "docs": [ { "_index":"index", "_id":"id", "_source":{ "title":"Introducing big data......", "tags":"hadoop,elasticsearch,spark", "content":"You konw, for big data" } }, { "_index":"index", "_id":"idxx", "_source":{ "title":"Introducing cloud computering", "tags":"openstack,k8s", "content":"You konw, for cloud" } } ] } # 为ES添加一个 Pipeline PUT _ingest/pipeline/blog_pipeline { "description": "a blog pipeline", "processors": [ { "split": { "field": "tags", "separator": "," } }, { "set":{ "field": "views", "value": 0 } } ] } #查看Pipleline GET _ingest/pipeline/blog_pipeline #测试pipeline POST _ingest/pipeline/blog_pipeline/_simulate { "docs": [ { "_source": { "title": "Introducing cloud computering", "tags": "openstack,k8s", "content": "You konw, for cloud" } } ] } #不使用pipeline更新数据 PUT tech_blogs/_doc/1 { "title":"Introducing big data......", "tags":"hadoop,elasticsearch,spark", "content":"You konw, for big data" } #使用pipeline更新数据 PUT tech_blogs/_doc/2?pipeline=blog_pipeline { "title": "Introducing cloud computering", "tags": "openstack,k8s", "content": "You konw, for cloud" } #查看两条数据,一条被处理,一条未被处理 POST tech_blogs/_search {} #update_by_query 会导致错误 POST tech_blogs/_update_by_query?pipeline=blog_pipeline { } #增加update_by_query的条件 POST tech_blogs/_update_by_query?pipeline=blog_pipeline { "query": { "bool": { "must_not": { "exists": { "field": "views" } } } } } #########Demo for Painless############### # 增加一个 Script Prcessor POST _ingest/pipeline/_simulate { "pipeline": { "description": "to split blog tags", "processors": [ { "split": { "field": "tags", "separator": "," } }, { "script": { "source": """ if(ctx.containsKey("content")){ ctx.content_length = ctx.content.length(); }else{ ctx.content_length=0; } """ } }, { "set":{ "field": "views", "value": 0 } } ] }, "docs": [ { "_index":"index", "_id":"id", "_source":{ "title":"Introducing big data......", "tags":"hadoop,elasticsearch,spark", "content":"You konw, for big data" } }, { "_index":"index", "_id":"idxx", "_source":{ "title":"Introducing cloud computering", "tags":"openstack,k8s", "content":"You konw, for cloud" } } ] } DELETE tech_blogs PUT tech_blogs/_doc/1 { "title":"Introducing big data......", "tags":"hadoop,elasticsearch,spark", "content":"You konw, for big data", "views":0 } POST tech_blogs/_update/1 { "script": { "source": "ctx._source.views += params.new_views", "params": { "new_views":100 } } } # 查看views计数 POST tech_blogs/_search { } #保存脚本在 Cluster State POST _scripts/update_views { "script":{ "lang": "painless", "source": "ctx._source.views += params.new_views" } } POST tech_blogs/_update/1 { "script": { "id": "update_views", "params": { "new_views":1000 } } } GET tech_blogs/_search { "script_fields": { "rnd_views": { "script": { "lang": "painless", "source": """ java.util.Random rnd = new Random(); doc['views'].value+rnd.nextInt(1000); """ } } }, "query": { "match_all": {} } }