原文:https://blog.csdn.net/rlnlo2pnefx9c/article/details/108288956
4.1 简单粗暴Sqoop
首先来回顾一下Sqoop架构图:
架构图
这里大家记住一个规则:大数据需要切分!如果不切分,这个亿级数据直接导入会崩溃!!!
★什么是Sqoop?
”
Sqoop是一个用来将Hadoop和关系型数据库中的数据相互转移的开源工具,可以将一个关系型数据库中的数据导进到Hadoop的HDFS或者HBase等。
sqoop核心参数与代码解释:
sqoop import
--connect jdbc:mysql://localhost:3306/loaddb
--username root
--password xxxx
--query "${sql}"
--hbase-row-key id
--hbase-create-table
--column-family info
--hbase-table mysql_data
--split-by id -m 4
--connect 指定连接的数据库,如果你的数据库不是本地的,记得修改地址!--username 用户名 --password 密码 --query sql语句 --hbase-row-key 指定rowkey,如果存在则修改为该值 --hbase-create-table 创建Hbase表 --column-family 列簇 --hbase-table hbase表名
注意:当-m 设置的值大于1时,split-by必须设置字段!
由于数据太大,需要分片导入,具体导入代码见仓库:
up=185941000 for((i=1; i>0; i++)) do start=$(((${i} - 1) * 40000 + 1)) end=$((${i} * 40000)) if [ $end -ge $up ] then end=185941000 fi sql="select id,carflag, touchevent, opstatus,gpstime,gpslongitude,gpslatitude,gpsspeed,gpsorientation,gpsstatus from loaddb.loadTable1 where id>=${start} and id<=${end} and $CONDITIONS"; sqoop import --connect jdbc:mysql://localhost:3306/loaddb --username root --password xxxx --query "${sql}" --hbase-row-key id --hbase-create-table --column-family info --hbase-table mysql_data --split-by id -m 4 echo Sqoop import from: ${start} to: ${end} success.................................... if [ $end -eq $up ] then break fi done
思路是每隔4万导入一次,当然您也可以修改。
耗时:(使用linux的time统计bash脚本运行时间)

enter image description here
导入结果:
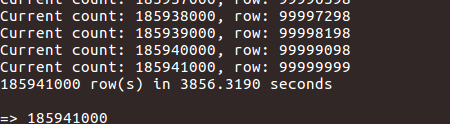
enter image description here
如果遇到问题,显示虚拟内存溢出,不断新开进程,杀死之前的进程,解决方案:关闭虚拟内存。

enter image description here
修改yarn-site.xml
<property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property>
以上就是MySQL同步Hbase方案1。
4.2 Kafka-thrift同步
enter image description here
4.2.1 binlog
binlog是sever层维护的一种二进制日志,与innodb引擎中的redo/undo log是完全不同的日志。
可以简单的理解该log记录了sql标中的更新删除插入等操作记录。通常应用在数据恢复、备份等场景。
★开启binlog
”
对于我的mysql的配置文件在下面这个文件夹,当然直接编辑my.cnf也是可以的。
-
vi /etc/mysql/mysql.conf.d/mysqld.cnf
-
对配置文件设置如下:
openbinlog
★查看是否启用
”
进入mysql客户端输入:
-
show variables like '%log_bin%';
-
binlog
★binlog介绍
”
我的log存放在var下面的log的mysql下面:
loglook
在mysql-bin.index中包含了所有的log文件,比如上述图就是包含了1与2文件,文件长度超过相应大小就会新开一个log文件,索引递增,如上面的000001,000002。
★binlog实战
”
首先创建一个表:
-
create table house(id int not null primary key,house int,price int);
-
向表中插入数据:
-
insert into loaddb.house(id,house,price) values(1,2,3);
-
上面提到插入数据后,binlog会更新,那么我们去查看上面log文件,应该会看到插入操作。
Mysql binlog日志有ROW,Statement,MiXED三种格式;
-
set global binlog_format='ROW/STATEMENT/MIXED'
-
命令行:
-
show variables like 'binlog_format'
-
row
对于mysql5.7的,binlog格式默认为ROW,所以不用修改。
那么为何要了解binlog格式呢,原因很简单,我要查看我的binlog日志,而该日志为二进制文件,打开后是乱码的。对于不同的格式,查看方式不一样!
对于ROW模式生成的sql编码需要解码,不能用常规的办法去生成,需要加上相应的参数,如下代码:
-
sudo /usr/bin/mysqlbinlog mysql-bin.000002 --base64-output=decode-rows -v
-
使用mysqlbinlog工具查看日志文件:
binlog
4.2.2 启动thrift接口
thrift为其他语言与hbase操纵接口。启动目的为后面数据插入做准备。
enter image description here
4.2.3 kafka-thrift流程小结
使用github仓库代码将原始数据进行每2w一个文件切分!
切分输出:
split
上述切分速度非常快,2分钟左右即可切完,可以自定义文件大小。
编写Kafka数据入Hbase,完整代码见github仓库代码:
def batchTokafka(self,start_time,table_name): table = self.conn.table(table_name) i = 1 with table.batch(batch_size=1024*1024) as bat: for m in self.consumer: t = time.time() database = json.loads(m.value.decode('utf-8'))["database"] name = json.loads(m.value.decode('utf-8'))["table"] row_data = json.loads(m.value.decode('utf-8'))["data"] if database=='loaddb' and name == 'sqlbase1': row_id = row_data["id"] row = str(row_id) print(row_data) del row_data["id"] data = {} for each in row_data: neweach = 'info:' + each data[neweach] = row_data[each] data['info:gpslongitude'] = str(data['info:gpslongitude']) data['info:gpslatitude'] = str(data['info:gpslatitude']) data['info:gpsspeed'] = str(data['info:gpsspeed']) data['info:gpsorientation'] = str(data['info:gpsorientation']) # self.insertData(table_name, row, data) print(data) bat.put(row,data) if i%1000==0: print("===========插入了" + str(i) + "数据!============") print("===========累计耗时:" + str(time.time() - start_time) + "s=============") print("===========距离上次耗时"+ str(time.time() - t) +"=========") i+=1
上述运行后,开始MySQL数据插入,这里插入采用4个多进程进行程序插入,速度非常快。
当MySQL数据在插入的同时,数据流向如下:
mysql插入->入库mysql->记录binlog->maxwell提取binlog->返回json给kafka->kafka消费端通过thrift接口->写入hbase。
上述同步的结果如下,为了明确是否真正数据同步,只看了一条数据,作为验证。
★
多个进程插入图
”

mutprocess
★kafka消费入hbase图
”
enter image description here
★MySQL数据图
”
enter image description here
★Hbase数据图
”
enter image description here
以上就是从Mysql到Hbase的同步方案2。
4.3 Kafka-Flink
enter image description here
4.3.1 实时同步Flink
方案3为方案2的改进,上述是通过Python写入Hbase,这里改成java,并使用最新的流处理技术:Flink。
Flink在ETL场景中使用频繁,非常适合数据同步,于是在这个方案中采用Flink进行同步。
核心代码实现,完整代码见github仓库地址:
SingleOutputStreamOperator<Student> student = env.addSource( new FlinkKafkaConsumer011<>( "test", //这个 kafka topic 需要和上面的工具类的 topic 一致 new SimpleStringSchema(), props)).setParallelism(9) .map(string -> JSON.parseObject(string, Student.class)) .setParallelism(9); long start =System.currentTimeMillis(); student.timeWindowAll(Time.seconds(3)).apply(new AllWindowFunction<Student, List<Student>, TimeWindow>() { @Override public void apply(TimeWindow window, Iterable<Student> values, Collector<List<Student>> out) throws Exception { ArrayList<Student> students = Lists.newArrayList(values); if (students.size() > 0) { System.out.println("1s内收集到 mysql表 的数据条数是:" + students.size()); long end =System.currentTimeMillis(); System.out.printf("已经用时time:%d ",end-start); out.collect(students); } } }).addSink(new SinkToHBase()).setParallelism(9);
使用Flink进行批量入Hbase。
4.3.2 Flink小结
首先启动maxwell与kafka,hbase也要启动,接着在数据写入端,可以采用load data infile或者python程序插入法进行数据插入,数据会通过maxwell到kafka再到Flink,然后sink到Hbase。
★插入端为load data infile的同步
”

flink_sink
★插入端为Python程序的同步
”
flink_load