本文主要介绍在流式场景中 join 的实战。大家都知道在使用 SQL 进行数据分析的过程中,join 是经常要使用的操作。在离线场景中,join 的数据集是有边界的,可以缓存数据有边界的数据集进行查询,有Nested Loop/Hash Join/Sort Merge Join 等多表 join;而在实时场景中,join 两侧的数据都是无边界的数据流,所以缓存数据集对长时间 job 来说,存储和查询压力很大,另外双流的到达时间可能不一致,造成 join 计算结果准确度不够;因此,Flink SQL 提供了多种 join 方法,来帮助用户应对各种 join 场景。
本文主要介绍 regular join/interval join/temproal table join 这种 3 种 join 的实战应用,主要包含如下几个部分:
- 数据准备
- Flink SQL join 之 regular join
- Flink SQL join 之 interval join
- Flink SQL join 之 temproal table join
- 总结
01 数据准备
一般来说大部分公司的实时的数据是保存在 kafka,物料数据保存在 MySQL 等类似的关系型数据库中,根据 Flink SQL 提供的 Kafka/JDBC connector,我们先注册两张 Flink Kafka Table 以及注册一张 Flink MySQL Table,明细建表语句如下所示:
- 注册 Flink Kafka Table, 作为两条需要 join 的数据流;对于点击流,我们定义Process time 时间属性,用来做 temproal table join,同时也定义 Event Time 和 watermark,用来做双流 join;对于曝光流,我们定义 Event Time 和watermark,用来做双流 join。
DROP TABLE IF EXISTS flink_rtdw.demo.adsdw_dwd_max_click_mobileapp; CREATE TABLE flink_rtdw.demo.adsdw_dwd_max_click_mobileapp ( ... publisher_adspace_adspaceId INT COMMENT '广告位唯一ID', ... audience_behavior_click_creative_impressionId BIGINT COMMENT '受众用户点击的广告创意的ImpressionId', audience_behavior_click_timestamp BIGINT COMMENT '受众用户点击广告的时间戳(毫秒)', ... procTime AS PROCTIME(), ets AS TO_TIMESTAMP(FROM_UNIXTIME(audience_behavior_click_timestamp / 1000)), WATERMARK FOR ets AS ets - INTERVAL '5' MINUTE ) WITH ( 'connector' = 'kafka', 'topic' = 'adsdw.dwd.max.click.mobileapp', 'properties.group.id' = 'adsdw.dwd.max.click.mobileapp_group', 'properties.bootstrap.servers' = 'broker1:9092,broker2:9092,broker3:9092', 'properties.sasl.jaas.config' = 'org.apache.kafka.common.security.scram.ScramLoginModule required username="kafka-administrator" password="kafka-administrator-password";', 'properties.security.protocol' = 'SASL_PLAINTEXT', 'properties.sasl.mechanism' = 'SCRAM-SHA-256', 'avro-confluent.schema-registry.url' = 'http://schema.registry.url:8081', 'avro-confluent.schema-registry.subject' = 'adsdw.dwd.max.click.mobileapp-value', 'format' = 'avro-confluent' );
注册 Flink Mysql Table, 作为维度表
DROP TABLE IF EXISTS flink_rtdw.demo.adsdw_dwd_max_show_mobileapp; CREATE TABLE flink_rtdw.demo.adsdw_dwd_max_show_mobileapp ( ... audience_behavior_watch_creative_impressionId BIGINT COMMENT '受众用户观看到的广告创意的ImpressionId', audience_behavior_watch_timestamp BIGINT COMMENT '受众用户观看到广告的时间(毫秒)', ... ets AS TO_TIMESTAMP(FROM_UNIXTIME(audience_behavior_watch_timestamp / 1000)), WATERMARK FOR ets AS ets - INTERVAL '5' MINUTE ) WITH ( 'connector' = 'kafka', 'topic' = 'adsdw.dwd.max.show.mobileapp', 'properties.group.id' = 'adsdw.dwd.max.show.mobileapp_group', 'properties.bootstrap.servers' = 'broker1:9092,broker2:9092,broker3:9092', 'properties.sasl.jaas.config' = 'org.apache.kafka.common.security.scram.ScramLoginModule required username="kafka-administrator" password="kafka-administrator-password";', 'properties.security.protocol' = 'SASL_PLAINTEXT', 'properties.sasl.mechanism' = 'SCRAM-SHA-256', 'avro-confluent.schema-registry.url' = 'http://schema.registry.url:8081', 'avro-confluent.schema-registry.subject' = 'adsdw.dwd.max.show.mobileapp-value', 'format' = 'avro-confluent' );
02 Flink SQL join 之 regular join
首先介绍 regular join, 因为 regular join 是最通用的 join 类型,不支持时间窗口以及时间属性,任何一侧数据流有更改都是可见的,直接影响整个 join 结果。如果有一侧数据流增加一个新纪录,那么它将会把另一侧的所有的过去和将来的数据合并在一起,因为 regular join 没有剔除策略,这就影响最新输出的结果; 正因为历史数据不会被清理,所以 regular join 支持数据流的任何更新操作。对于 regular join 来说,更适合用于离线场景和小数据量场景。
- 使用语法
SELECT columns FROM t1 [AS <alias1>] [LEFT/INNER/FULL OUTER] JOIN t2 ON t1.column1 = t2.key-name1
- 使用场景:离线场景和小数据量场景
- 根据小节 1 中的数据,我们来做一个简单的 regular join,将 click 流和曝光流根据 impressionId 进行 regualr join,输出广告位和 impressionId,具体 SQL语句如下所示:
select adsdw_dwd_max_click_mobileapp.publisher_adspace_adspaceId as publisher_adspace_adspaceId, adsdw_dwd_max_click_mobileapp.audience_behavior_click_creative_impressionId as click_impressionId, adsdw_dwd_max_show_mobileapp.audience_behavior_watch_creative_impressionId as show_impressionId from adsdw_dwd_max_click_mobileapp inner join adsdw_dwd_max_show_mobileapp on adsdw_dwd_max_click_mobileapp.audience_behavior_click_creative_impressionId = adsdw_dwd_max_show_mobileapp.audience_behavior_watch_creative_impressionId;
提交到 Flink 集群的 job 以及输出的结果如下所示:


03 Flink SQL join 之 interval join
相对于 regular join,interval Join 则利用窗口的给两个输入表设定一个 Join 的时间界限,超出时间范围的数据则对 join 不可见并可以被清理掉,这样就能修正 regular join 因为没有剔除数据策略带来 join 结果的误差以及需要大量的资源。但是使用interval join,需要定义好时间属性字段,可以是计算发生的 Processing Time,也可以是根据数据本身提取的 Event Time;如果是定义的是 Processing Time,则Flink 框架本身根据系统划分的时间窗口定时清理数据;如果定义的是 Event Time,Flink 框架分配 Event Time 窗口并根据设置的 watermark 来清理数据。而在前面的数据准备中,我们根据点击流和曝光流提取实践时间属性字段,并且设置了允许 5 分钟乱序的 watermark。目前 Interval join 已经支持 inner ,left outer, right outer , full outer 等类型的 join。因此,interval join 只需要缓存时间边界内的数据,存储空间占用小,计算更为准确的实时 join 结果。
- 使用语法
--写法1 SELECT columns FROM t1 [AS <alias1>] [LEFT/INNER/FULL OUTER] JOIN t2 ON t1.column1 = t2.key-name1 AND t1.timestamp BETWEEN t2.timestamp AND BETWEEN t2.timestamp + + INTERVAL '10' MINUTE;
--写法2 SELECT columns FROM t1 [AS <alias1>] [LEFT/INNER/FULL OUTER] JOIN t2 ON t1.column1 = t2.key-name1 AND t2.timestamp <= t1.timestamp and t1.timestamp <= t2.timestamp + + INTERVAL ’10' MINUTE ;
如何设置边界条件
right.timestamp ∈ [left.timestamp + lowerBound, left.timestamp + upperBound]
- 使用场景:双流join场景
- 根据小节1中的数据,我们来做一个inertval join(用between and 的方式),将click流和曝光流根据impressionId进行interval join, 边界条件是点击流介于曝光流发生到曝光流发生后的10分钟,输出广告位和impressionId,具体SQL语句如下所示:
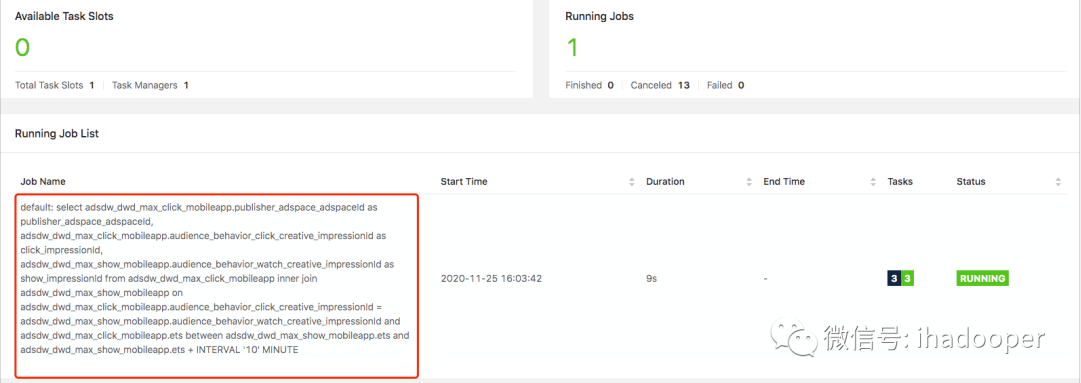
select adsdw_dwd_max_click_mobileapp.publisher_adspace_adspaceId as publisher_adspace_adspaceId, adsdw_dwd_max_click_mobileapp.audience_behavior_click_creative_impressionId as click_impressionId, adsdw_dwd_max_show_mobileapp.audience_behavior_watch_creative_impressionId as show_impressionId from adsdw_dwd_max_click_mobileapp inner join adsdw_dwd_max_show_mobileapp on adsdw_dwd_max_click_mobileapp.audience_behavior_click_creative_impressionId = adsdw_dwd_max_show_mobileapp.audience_behavior_watch_creative_impressionId and adsdw_dwd_max_click_mobileapp.ets between adsdw_dwd_max_show_mobileapp.ets and adsdw_dwd_max_show_mobileapp.ets + INTERVAL '10' MINUTE;
提交到 Flink 集群的job以及输出的结果如下所示:

Interval join 有多种写法来实现 interval join,根据小节1中的数据我们用 <= 的方式来实现,还是做同样的逻辑,将 click 流和曝光流根据 impressionId 进行 interval join, 边界条件是点击流介于曝光流发生到曝光流发生后的 10 分钟,输出广告位和 impressionId,具体 SQL 语句如下所示:
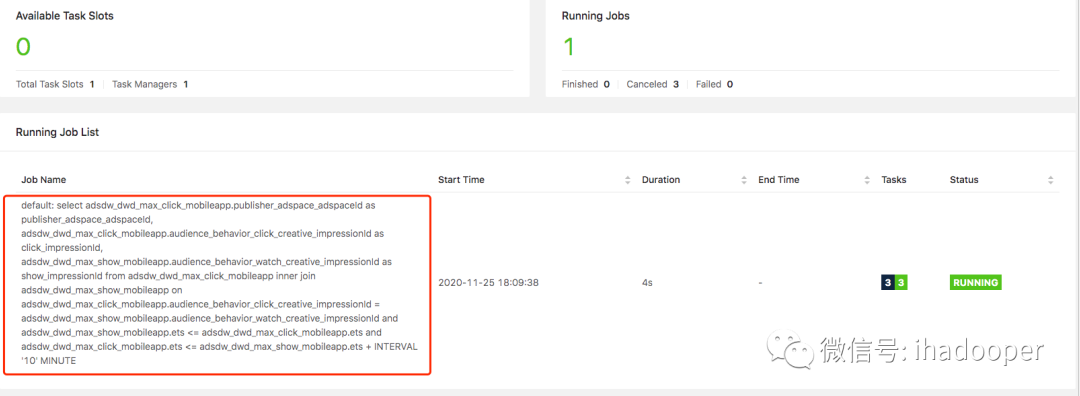
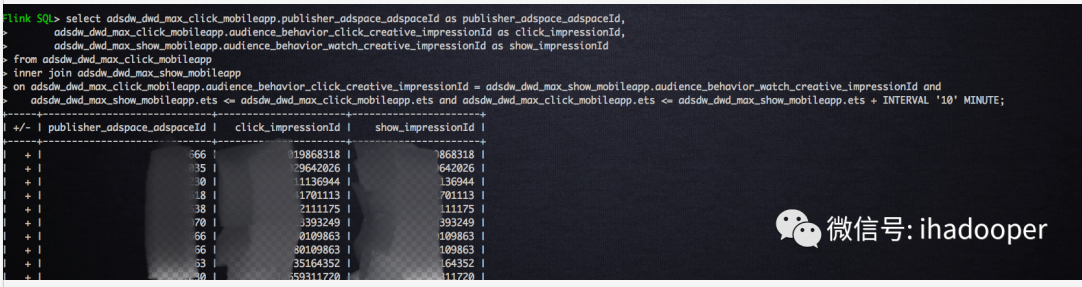
select adsdw_dwd_max_click_mobileapp.publisher_adspace_adspaceId as publisher_adspace_adspaceId, adsdw_dwd_max_click_mobileapp.audience_behavior_click_creative_impressionId as click_impressionId, adsdw_dwd_max_show_mobileapp.audience_behavior_watch_creative_impressionId as show_impressionId from adsdw_dwd_max_click_mobileapp inner join adsdw_dwd_max_show_mobileapp on adsdw_dwd_max_click_mobileapp.audience_behavior_click_creative_impressionId = adsdw_dwd_max_show_mobileapp.audience_behavior_watch_creative_impressionId and adsdw_dwd_max_show_mobileapp.ets <= adsdw_dwd_max_click_mobileapp.ets and adsdw_dwd_max_click_mobileapp.ets <= adsdw_dwd_max_show_mobileapp.ets + INTERVAL '10' MINUTE;
提交到 Flink 集群的 job 以及输出的结果如下所示:
04 Flink SQL join 之 temproal table join
上节中 interval Join 提供了剔除数据的策略,解决资源问题以及计算更加准确,这是有个前提:join 的两个流需要时间属性,需要明确时间的下界,来方便剔除数据;显然,这种场景不适合维度表的 join,因为维度表没有时间界限,对于这种场景,Flink 提供了 temproal table join 来覆盖此类场景。
在 regular join和interval join中,join 两侧的表是平等的,任意的一个表的更新,都会去和另外的历史纪录进行匹配,temproal table 的更新对另一表在该时间节点以前的记录是不可见的。而在temproal table join 中,比较明显的使用场景之一就是点击流去 join 广告位的维度表,引入广告位的中文名称。
使用语法
SELECT columns FROM t1 [AS <alias1>] [LEFT] JOIN t2 FOR SYSTEM_TIME AS OF t1.proctime [AS <alias2>] ON t1.column1 = t2.key-name1
- 使用场景:维度表 join 场景
- 根据小节1中的数据,我们来做一个 temproal table join,将 click 流和广告位维度表根据广告位 Id 进行 temproal rable join,输出广告位和广告位中文名字,具体 SQL 语句如下所示:
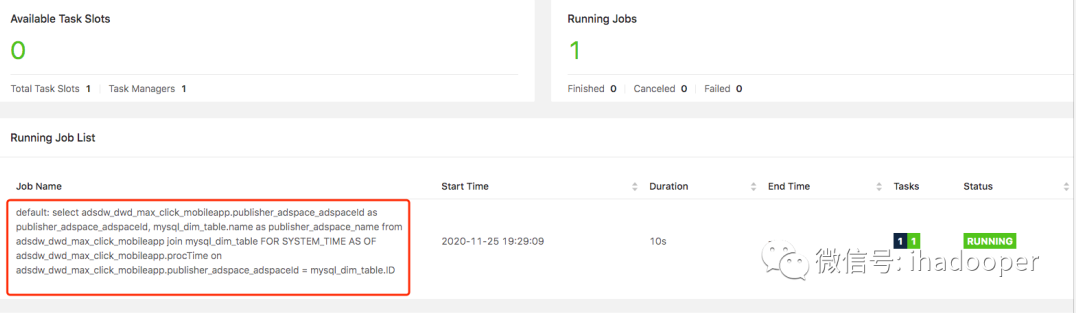
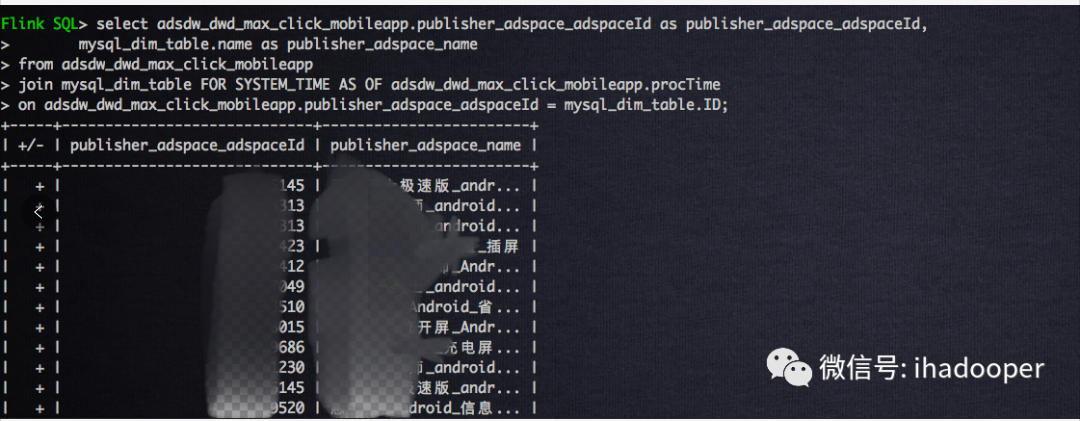
select adsdw_dwd_max_click_mobileapp.publisher_adspace_adspaceId as publisher_adspace_adspaceId, mysql_dim_table.name as publisher_adspace_name from adsdw_dwd_max_click_mobileapp join mysql_dim_table FOR SYSTEM_TIME AS OF adsdw_dwd_max_click_mobileapp.procTime on adsdw_dwd_max_click_mobileapp.publisher_adspace_adspaceId = mysql_dim_table.ID;
提交到 Flink 集群的 job 以及输出的结果如下所示:
05 总结
上面简单介绍 Flink SQL 三种 join 方式的使用,一般对于流式 join 来说,对于双流join 的场景,推荐使用 interval join,对于流和维度表 join 的场景推荐使用 temproal table join。
作者简介
余敖,360 数据开发高级工程师,目前专注于基于 Flink 的实时数仓建设与平台化工作。对 Flink、Kafka、Hive、Spark 等进行数据 ETL 和数仓开发有丰富的经验。