以下文章来源于数据架构那些事 ,作者余敖
本文主要介绍 HBase 和 Flink SQL 的结合使用。HBase 作为 Google 发表 Big Table 论文的开源实现版本,是一种分布式列式存储的数据库,构建在 HDFS 之上的 NoSQL 数据库,非常适合大规模实时查询,因此 HBase 在实时计算领域使用非常广泛。可以实时写 HBase,也可以利用 buckload 一把把离线 Job 生成 HFile Load 到HBase 表中。而当下 Flink SQL 的火热程度不用多说,Flink SQL 也为 HBase 提供了 connector,因此 HBase 与 Flink SQL 的结合非常有必要实践实践。
当然,本文假设用户有一定的 HBase 知识基础,不会详细去介绍 HBase 的架构和原理,本文着重介绍 HBase 和 Flink 在实际场景中的结合使用。主要分为两种场景,第一种场景:HBase 作为维表与 Flink Kafka table 做 temporal table join 的场景;第二种场景:Flink SQL 做计算之后的结果写到 HBase 表,供其他用户查询的场景。因此,本文介绍的内容如下所示:
- HBase 环境准备
- 数据准备
- HBase 作为维度表进行 temporal table join的场景
- Flink SQL 做计算写 HBase 的场景
- 总结
01 HBase 环境准备
由于没有测试的 HBase 环境以及为了避免污染线上 Hbase 环境。因此,自己 build一个 Hbase docker image(大家可以 docker pull guxinglei/myhbase 拉到本地),是基于官方干净的 ubuntu imgae 之上安装了 Hbase 2.2.0 版本以及 JDK1.8 版本。
- 启动容器,暴露 Hbase web UI 端口以及内置 zk 端口,方便我们从 web 页面看信息以及创建 Flink Hbase table 需要 zk 的链接信息。
docker run -it --network=host -p 2181:2181 -p 60011:60011 docker.io/guxinglei/myhbase:latest bash

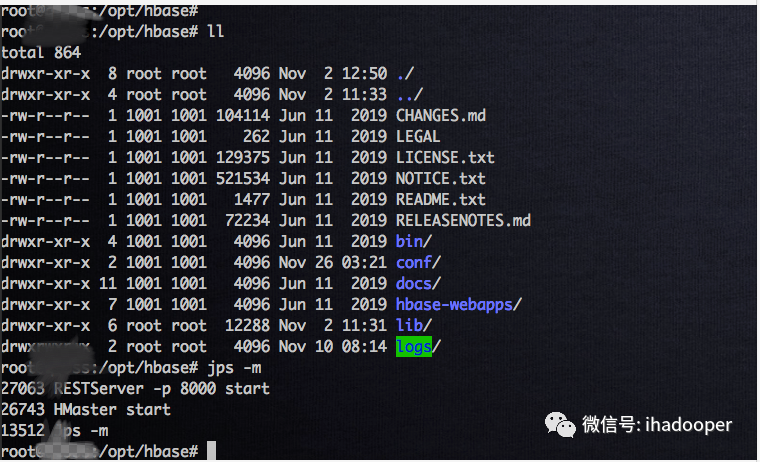
进入容器,启动 HBase 集群,以及启动 rest server,后续方便我们用 REST API 来读取 Flink SQL 写进 HBase 的数据。
# 启动hbase 集群bin/start-hbase.sh# 后台启动restServerbin/hbase-daemon.sh start rest -p 8000
02 数据准备
由于 HBase 环境是自己临时搞的单机服务,里面没有数据,需要往里面写点数据供后续示例用。在 Flink SQL 实战系列第二篇中介绍了如何注册 Flink Mysql table,我们可以将广告位表抽取到 HBase 表中,用来做维度表,进行 temporal table join。因此,我们需要在 HBase 中创建一张表,同时还需要创建 Flink HBase table, 这两张表通过 Flink SQL 的 HBase connector 关联起来。
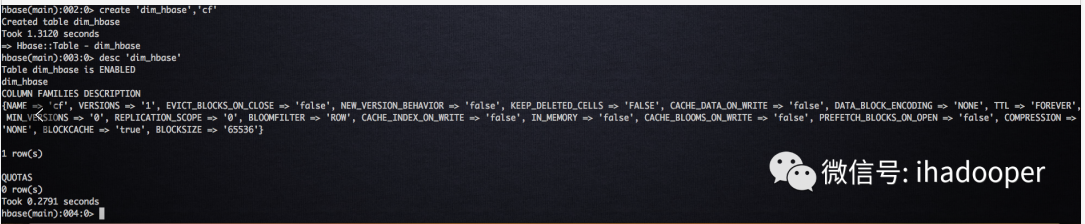
- 在容器中启动 HBase shell,创建一张名为 dim_hbase 的 HBase 表,建表语句如下所示:
# 在hbase shell创建 hbase表 hbase(main):002:0> create 'dim_hbase','cf' Created table dim_hbase Took 1.3120 seconds => Hbase::Table - dim_hbase
在 Flink 中创建 Flink HBase table,建表语句如下所示:
# 注册 Flink Hbase table DROP TABLE IF EXISTS flink_rtdw.demo.hbase_dim_table; CREATE TABLE flink_rtdw.demo.hbase_dim_table ( rowkey STRING, cf ROW < adspace_name STRING >, PRIMARY KEY (rowkey) NOT ENFORCED ) WITH ( 'connector' = 'hbase-1.4', 'table-name' = 'dim_hbase', 'sink.buffer-flush.max-rows' = '1000', 'zookeeper.quorum' = 'localhost:2181' );
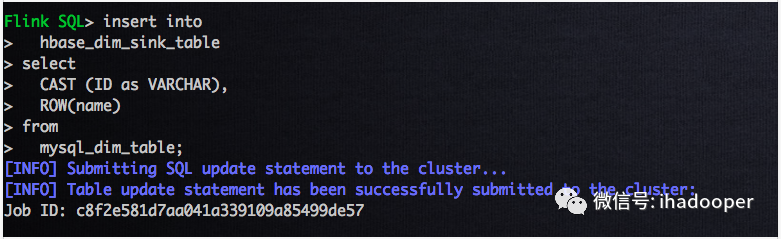
Flink MySQL table 和 Flink HBase table 已经创建好了,就可以写抽取数据到HBase 的 SQL job 了,SQL 语句以及 job 状态如下所示:
# 抽取Mysql数据到Hbase表中 insert into hbase_dim_table select CAST (ID as VARCHAR), ROW(name) from mysql_dim_table;


03 HBase 作为维表与 Kafka 做 temporal join 的场景
在 Flink SQL join 中,维度表的 join 一定绕不开的,比如订单金额 join 汇率表,点击流 join 广告位的明细表等等,使用场景非常广泛。那么作为分布式数据库的 HBase 比 MySQL 作为维度表用作维度表 join 更有优势。在 Flink SQL 实战系列第二篇中,我们注册了广告的点击流,将 Kafka topic 注册 Flink Kafka Table,同时也介绍了 temporal table join 在 Flink SQL 中的使用;那么本节中将会介绍 HBase 作为维度表来使用,上面小节中已经将数据抽取到 Hbase 中了,我们直接写 temporal table join 计算逻辑即可。
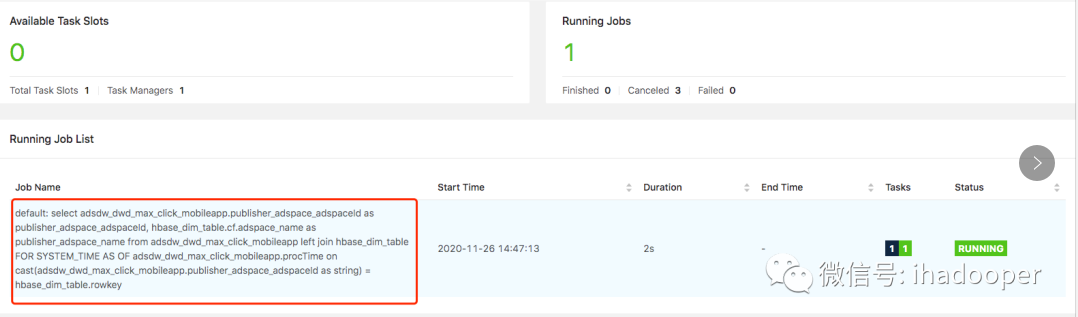
- 作为广告点击流的 Flink Kafa table 与 作为广告位的 Flink HBase table 通过广告位 Id 进行 temporal table join,输出广告位 ID 和广告位中文名字,SQL join 逻辑如下所示:
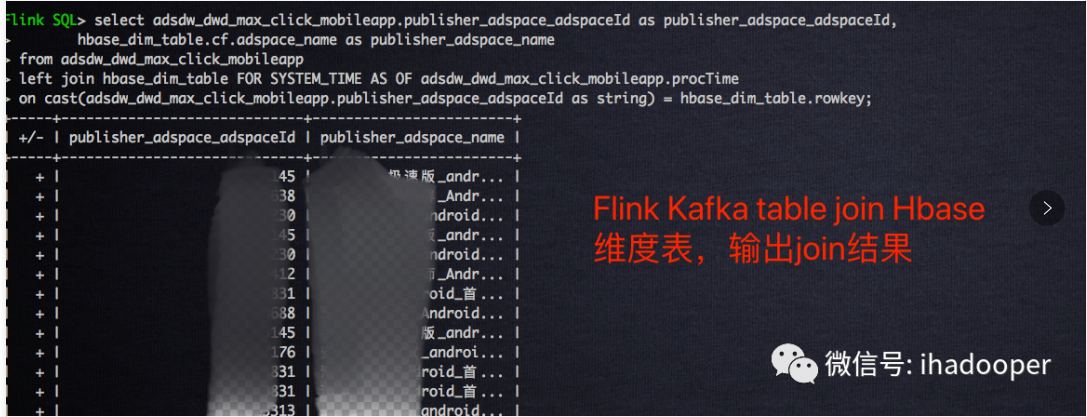
select adsdw_dwd_max_click_mobileapp.publisher_adspace_adspaceId as publisher_adspace_adspaceId, hbase_dim_table.cf.adspace_name as publisher_adspace_name from adsdw_dwd_max_click_mobileapp left join hbase_dim_table FOR SYSTEM_TIME AS OF adsdw_dwd_max_click_mobileapp.procTime on cast(adsdw_dwd_max_click_mobileapp.publisher_adspace_adspaceId as string) = hbase_dim_table.rowkey;
temporal table join job 提交 Flink 集群上的状态以及 join 结果如下所示:
04 计算结果 sink 到 HBase 作为结果的场景
上面小节中,HBase 作为维度表用作 temporal table join 是非常常见的场景,实际上 HBase 作为存储计算结果也是非常常见的场景,毕竟 Hbase 作为分布式数据库,底层存储是拥有多副本机制的 HDFS,维护简单,扩容方便, 实时查询快,而且提供各种客户端方便下游使用存储在 HBase 中的数据。那么本小节就介绍 Flink SQL 将计算结果写到 HBase,并且通过 REST API 查询计算结果的场景。
- 进入容器中,在 HBase 中新建一张 HBase 表,一个 column family 就满足需求,建表语句如下所示:
# 注册hbase sink table create 'dwa_hbase_click_report','cf'

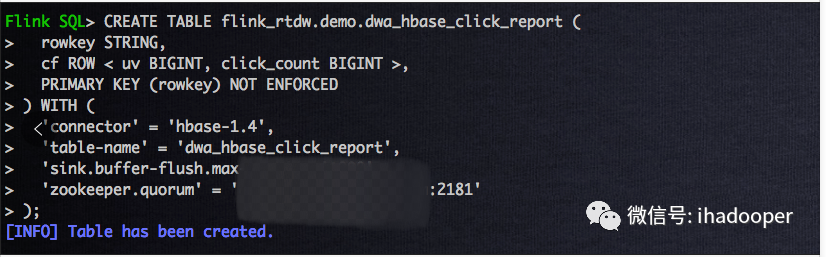
建立好 HBase 表之后,我们需要在 Flink SQL 创建一张 Flink HBase table,这个时候我们需要明确 cf 这个 column famaly 下面 column 字段,在 Flink SQL实战第二篇中,已经注册好了作为点击流的 Flink Kafka table,因此本节中,将会计算点击流的 uv 和点击数,因此两个 column 分别为 uv 和 click_count,建表语句如下所示:
# 注册 Flink Hbase table DROP TABLE IF EXISTS flink_rtdw.demo.dwa_hbase_click_report; CREATE TABLE flink_rtdw.demo.dwa_hbase_click_report ( rowkey STRING, cf ROW < uv BIGINT, click_count BIGINT >, PRIMARY KEY (rowkey) NOT ENFORCED ) WITH ( 'connector' = 'hbase-1.4', 'table-name' = 'dwa_hbase_click_report', 'sink.buffer-flush.max-rows' = '1000', 'zookeeper.quorum' = 'hostname:2181' );
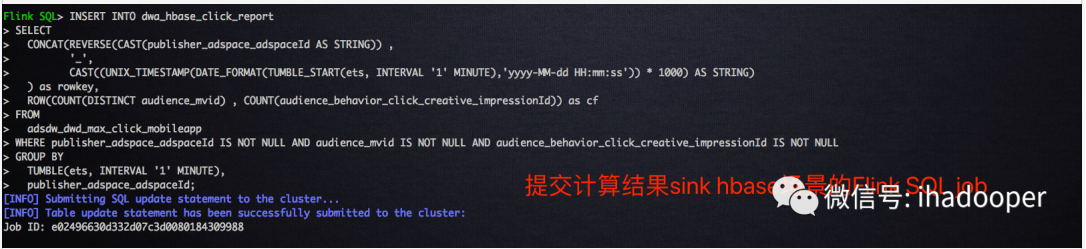
- 前面点击流的 Flink Kafka table 和存储计算结果的 HBase table 和 Flink HBase table 已经准备了,我们将做一个1分钟的翻转窗口计算 uv 和点击数,并且将计算结果写到 HBase 中。对 HBase 了解的人应该知道,rowkey 的设计对 hbase regoin 的分布有着非常重要的影响,基于此我们的 rowkey 是使用 Flink SQL 内置的 reverse 函数进行广告位 Id 进行反转和窗口启始时间做 concat,因此,SQL 逻辑语句如下所示:
INSERT INTO dwa_hbase_click_report SELECT CONCAT(REVERSE(CAST(publisher_adspace_adspaceId AS STRING)) , '_', CAST((UNIX_TIMESTAMP(DATE_FORMAT(TUMBLE_START(ets, INTERVAL '1' MINUTE),'yyyy-MM-dd HH:mm:ss')) * 1000) AS STRING) ) as rowkey, ROW(COUNT(DISTINCT audience_mvid) , COUNT(audience_behavior_click_creative_impressionId)) as cf FROM adsdw_dwd_max_click_mobileapp WHERE publisher_adspace_adspaceId IS NOT NULL AND audience_mvid IS NOT NULL AND audience_behavior_click_creative_impressionId IS NOT NULL GROUP BY TUMBLE(ets, INTERVAL '1' MINUTE), publisher_adspace_adspaceId;
SQL job 提交之后的状态以及结果 check 如下所示:
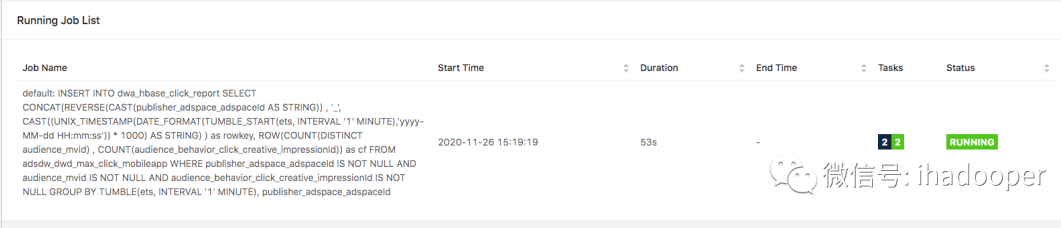
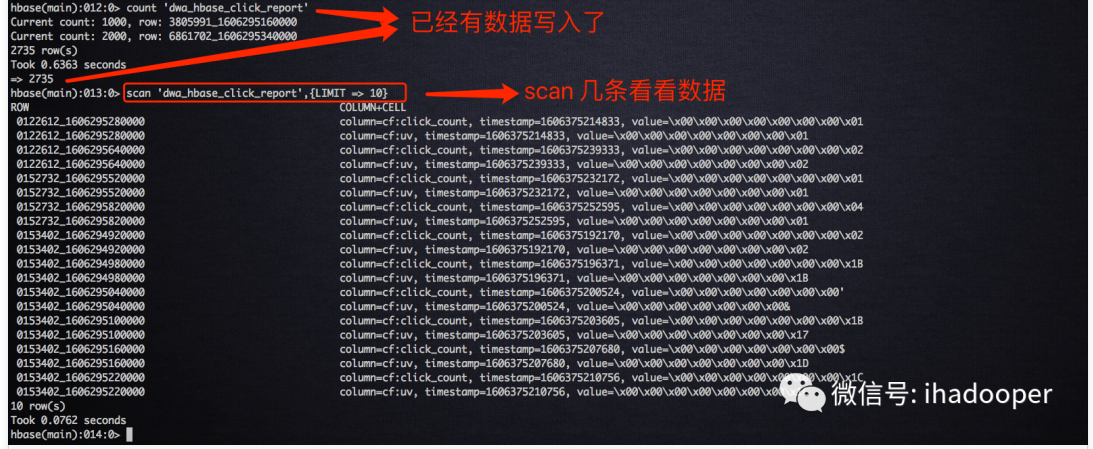
上述 SQL job 已经成功的将结算结果写到 HBase 中了。对于线上的 HBase 服务来讲,很多同事不一定有 HBase 客户端的权限,从而也不能通过 HBase shell 读取数据;另外作为线上报表服务显然不可能通过 HBase shell 来通过查询数据。因此,在实时报表场景中,数据开发工程师将数据写入 HBase, 前端工程师通过 REST API 来读取数据。前面我们已经启动了 HBase rest server 进程,我们可以通 rest 服务提供读取 HBase 里面的数据。
- 我们先 get 一条刚刚写到 HBase 中的数据看看,如下所示:

- 下面我们开始通过 REST API 来查询 HBase 中的数据,第一步,执行如下语句拿到 scannerId;首先需要将要查询的 rowkey 进行 base64 编码才能使用,后面需要将结果进行 base64 解码
rowkey base64 编码前:0122612_1606295280000 base64 编码之后:MDEyMjYxMl8xNjA2Mjk1MjgwMDAw
curl -vi -X PUT -H "Accept: text/xml" -H "Content-Type: text/xml" -d '<Scanner startRow="MDEyMjYxMl8xNjA2Mjk1MjgwMDAw" endRow="MDEyMjYxMl8xNjA2Mjk1MjgwMDAw"></Scanner>' "http://hostname:8000/dwa_hbase_click_report/scanner"
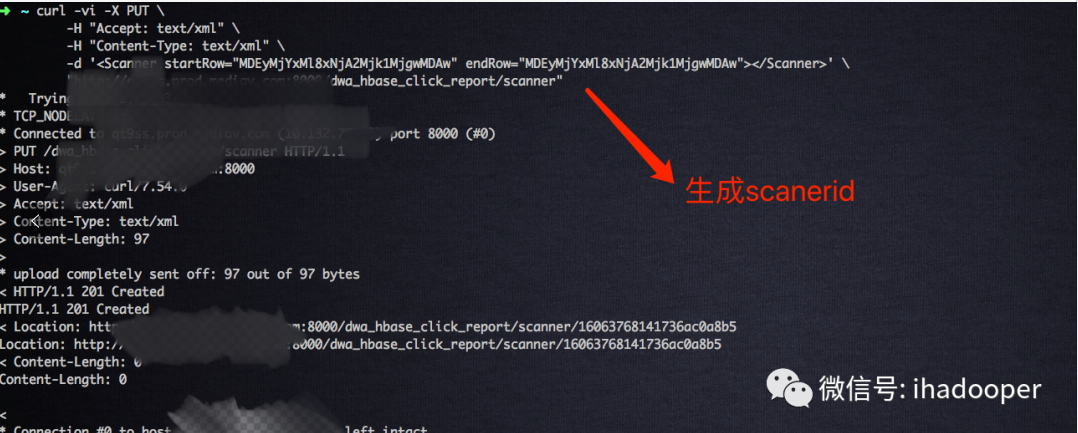
- 第二步,执行如下语句根据上条语句返回的 scannerID 查询数据,可以看到返回的结果:
curl -vi -X GET -H "Accept: application/json" "http://hostname:8000/dwa_hbase_click_report/scanner/16063768141736ac0a8b5"

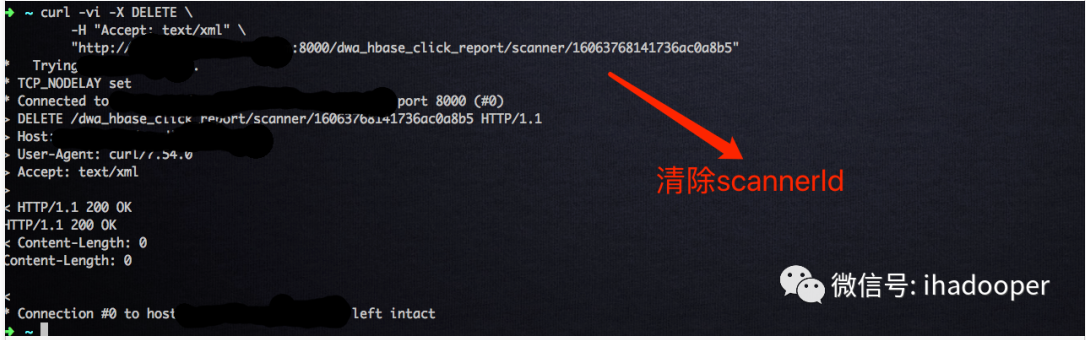
第三步,查询完毕之后,执行如下语句删除该 scannerId:
curl -vi -X DELETE -H "Accept: text/xml" "http://hostname:8000/dwa_hbase_click_report/scanner/16063768141736ac0a8b5"
05. 总结
在本篇文章中,我们介绍了 HBase 和 Flink SQL 的结合使用比较广泛两种的场景:作为维度表用以及存储计算结果;同时使用 REST API 对 HBase 中的数据进行查询,对于查询用户来说,避免直接暴露 HBase 的 zk,同时将 rest server 和 HBase 集群解耦。
作者简介
余敖,360 数据开发高级工程师,目前专注于基于 Flink 的实时数仓建设与平台化工作。对 Flink、Kafka、Hive、Spark 等进行数据 ETL 和数仓开发有丰富的经验。