4 Java操作任务
使用Azkaban调度java程序
1)编写java程序
import java.io.IOException; public class AzkabanTest { public void run() throws IOException { // 根据需求编写具体代码 FileOutputStream fos = new FileOutputStream("/opt/module/azkaban/output.txt"); fos.write("this is a java progress".getBytes()); fos.close(); } public static void main(String[] args) throws IOException { AzkabanTest azkabanTest = new AzkabanTest(); azkabanTest.run(); } }
2)将java程序打成jar包,创建lib目录,将jar放入lib内
[atguigu@hadoop102 azkaban]$ mkdir lib [atguigu@hadoop102 azkaban]$ cd lib/ [atguigu@hadoop102 lib]$ ll 总用量 4 -rw-rw-r--. 1 atguigu atguigu 3355 10月 18 20:55 azkaban-0.0.1-SNAPSHOT.jar
3)编写job文件
[atguigu@hadoop102 jobs]$ vim azkabanJava.job #azkabanJava.job type=javaprocess java.class=com.atguigu.azkaban.AzkabanTest classpath=/opt/module/azkaban/lib/*
4)将job文件打成zip包
[atguigu@hadoop102 jobs]$ zip azkabanJava.zip azkabanJava.job
adding: azkabanJava.job (deflated 19%)
5)通过azkaban的web管理平台创建project并上传job压缩包,启动执行该job

[atguigu@hadoop102 azkaban]$ pwd
/opt/module/azkaban
[atguigu@hadoop102 azkaban]$ ll
总用量 24
drwxrwxr-x. 2 atguigu atguigu 4096 10月 17 17:14 azkaban-2.5.0
drwxrwxr-x. 10 atguigu atguigu 4096 10月 18 17:17 executor
drwxrwxr-x. 2 atguigu atguigu 4096 10月 18 20:35 jobs
drwxrwxr-x. 2 atguigu atguigu 4096 10月 18 20:54 lib
-rw-rw-r--. 1 atguigu atguigu 23 10月 18 20:55 output
drwxrwxr-x. 9 atguigu atguigu 4096 10月 18 17:17 server
[atguigu@hadoop102 azkaban]$ cat output
this is a java progress
5 HDFS操作任务
1)创建job描述文件
[atguigu@hadoop102 jobs]$ vim fs.job #hdfs job type=command command=/opt/module/hadoop-2.7.2/bin/hadoop fs -mkdir /azkaban
2)将job资源文件打包成zip文件
[atguigu@hadoop102 jobs]$ zip fs.zip fs.job
adding: fs.job (deflated 12%)
3)通过azkaban的web管理平台创建project并上传job压缩包
4)启动执行该job
5)查看结果

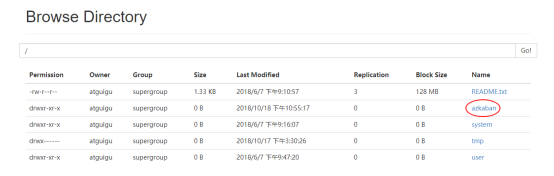
6 MapReduce任务
MapReduce任务依然可以使用Azkaban进行调度
1) 创建job描述文件,及mr程序jar包
[atguigu@hadoop102 jobs]$ vim mapreduce.job #mapreduce job type=command command=/opt/module/hadoop-2.7.2/bin/hadoop jar /opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /wordcount/input /wordcount/output
2) 将所有job资源文件打到一个zip包中
[atguigu@hadoop102 jobs]$ zip mapreduce.zip mapreduce.job
adding: mapreduce.job (deflated 43%)
3)在azkaban的web管理界面创建工程并上传zip包
4)启动job
5)查看结果

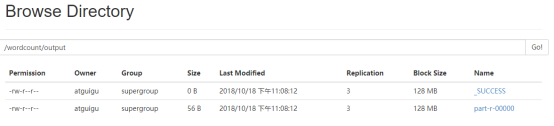
7 Hive脚本任务
1)创建job描述文件和hive脚本
(1)Hive脚本:student.sql
[atguigu@hadoop102 jobs]$ vim student.sql use default; drop table student; create table student(id int, name string) row format delimited fields terminated by ' '; load data local inpath '/opt/module/datas/student.txt' into table student; insert overwrite local directory '/opt/module/datas/student' row format delimited fields terminated by ' ' select * from student;
(2)Job描述文件:hive.job
[atguigu@hadoop102 jobs]$ vim hive.job #hive job type=command command=/opt/module/hive/bin/hive -f /opt/module/azkaban/jobs/student.sql
1) 将所有job资源文件打到一个zip包中
[atguigu@hadoop102 jobs]$ zip hive.zip hive.job
adding: hive.job (deflated 21%)
3)在azkaban的web管理界面创建工程并上传zip包
4)启动job
5)查看结果
[atguigu@hadoop102 student]$ cat /opt/module/datas/student/000000_0 1001 yangyang 1002 huihui 1003 banzhang 1004 pengpeng
