CoGroup
该操作是将两个数据流/集合按照key进行group,然后将相同key的数据进行处理,但是它和join操作稍有区别,它在一个流/数据集中没有找到与另一个匹配的数据还是会输出。
1.在DataStream中
- 侧重与group,对同一个key上的两组集合进行操作。
- 如果在一个流中没有找到与另一个流的window中匹配的数据,任何输出结果,即只输出一个流的数据。
- 仅能使用在window中。
实例一:
下面看一个简单的例子,这个例子中从两个不同的端口来读取数据,模拟两个流,我们使用CoGroup来处理这两个数据流,观察输出结果:
public class CogroupFunctionDemo02 { public static void main(String[] args) throws Exception { final StreamExecutionEnvironment env=StreamExecutionEnvironment.getExecutionEnvironment(); DataStream<Tuple2<String,String>> input1=env.socketTextStream("192.168.217.110",9002) .map(new MapFunction<String, Tuple2<String,String>>() { @Override public Tuple2<String,String> map(String s) throws Exception { return Tuple2.of(s.split(" ")[0],s.split(" ")[1]); } }); DataStream<Tuple2<String,String>> input2=env.socketTextStream("192.168.217.110",9001) .map(new MapFunction<String, Tuple2<String,String>>() { @Override public Tuple2<String,String> map(String s) throws Exception { return Tuple2.of(s.split(" ")[0],s.split(" ")[1]); } }); input1.coGroup(input2) .where(new KeySelector<Tuple2<String,String>, Object>() { @Override public Object getKey(Tuple2<String, String> value) throws Exception { return value.f0; } }).equalTo(new KeySelector<Tuple2<String,String>, Object>() { @Override public Object getKey(Tuple2<String, String> value) throws Exception { return value.f0; } }).window(ProcessingTimeSessionWindows.withGap(Time.seconds(3))) .trigger(CountTrigger.of(1)) .apply(new CoGroupFunction<Tuple2<String,String>, Tuple2<String,String>, Object>() { @Override public void coGroup(Iterable<Tuple2<String, String>> iterable, Iterable<Tuple2<String, String>> iterable1, Collector<Object> collector) throws Exception { StringBuffer buffer=new StringBuffer(); buffer.append("DataStream frist: "); for(Tuple2<String,String> value:iterable){ buffer.append(value.f0+"=>"+value.f1+" "); } buffer.append("DataStream second: "); for(Tuple2<String,String> value:iterable1){ buffer.append(value.f0+"=>"+value.f1+" "); } collector.collect(buffer.toString()); } }).print(); env.execute(); } }
首先启动两个终端窗口,然后使用nc工具打开两个端口,然后运行上面程序:
[shinelon@hadoop-senior Desktop]$ nc -lk 9001 1 lj 1 al 2 af
[shinelon@hadoop-senior Desktop]$ nc -lk 9002 2 ac 1 ao 2 14
运行 结果如下所示:
2> DataStream frist: 2=>ac DataStream second: 4> DataStream frist: DataStream second: 1=>lj 4> DataStream frist: 1=>ao DataStream second: 4> DataStream frist: DataStream second: 1=>al 2> DataStream frist: 2=>14 DataStream second: 2> DataStream frist: 2=>14 DataStream second: 2=>af
2.在DataSet中
下面的例子中,key代表学生班级ID,value为学生name,使用cogroup操作将两个集合中key相同数据合并:
public class CoGourpDemo { public static void main(String[] args) throws Exception { ExecutionEnvironment env=ExecutionEnvironment.getExecutionEnvironment(); DataSet<Tuple2<Long, String>> source1=env.fromElements( Tuple2.of(1L,"xiaoming"), Tuple2.of(2L,"xiaowang")); DataSet<Tuple2<Long, String>> source2=env.fromElements( Tuple2.of(2L,"xiaoli"), Tuple2.of(1L,"shinelon"), Tuple2.of(3L,"hhhhhh")); source1.coGroup(source2) .where(0).equalTo(0) .with(new CoGroupFunction<Tuple2<Long,String>, Tuple2<Long,String>, Object>() { @Override public void coGroup(Iterable<Tuple2<Long, String>> iterable, Iterable<Tuple2<Long, String>> iterable1, Collector<Object> collector) throws Exception { Map<Long,String> map=new HashMap<Long,String>(); for(Tuple2<Long,String> tuple:iterable){ String str=map.get(tuple.f0); if(str==null){ map.put(tuple.f0,tuple.f1); }else{ if(!str.equals(tuple.f1)) map.put(tuple.f0,str+" "+tuple.f1); } } for(Tuple2<Long,String> tuple:iterable1){ String str=map.get(tuple.f0); if(str==null){ map.put(tuple.f0,tuple.f1); }else{ if(!str.equals(tuple.f1)) map.put(tuple.f0,str+" "+tuple.f1); } } collector.collect(map); } }).print(); } }
运行结果如下所示:
{3=hhhhhh}
{1=xiaoming shinelon}
{2=xiaowang xiaoli}
实例二:
case class Order(id:String, gdsId:String, amount:Double) case class Gds(id:String, name:String) case class RsInfo(orderId:String, gdsId:String, amount:Double, gdsName:String) object CoGroupDemo{ def main(args:Array[String]):Unit={ val env =StreamExecutionEnvironment.getExecutionEnvironment env.setParallelism(1) val kafkaConfig =newProperties(); kafkaConfig.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"localhost:9092"); kafkaConfig.put(ConsumerConfig.GROUP_ID_CONFIG,"test1"); val orderConsumer =newFlinkKafkaConsumer011[String]("topic1",newSimpleStringSchema, kafkaConfig) val gdsConsumer =newFlinkKafkaConsumer011[String]("topic2",newSimpleStringSchema, kafkaConfig) val orderDs = env.addSource(orderConsumer) .map(x =>{ val a = x.split(",") Order(a(0), a(1), a(2).toDouble) }) val gdsDs = env.addSource(gdsConsumer) .map(x =>{ val a = x.split(",") Gds(a(0), a(1)) }) orderDs.coGroup(gdsDs) .where(_.gdsId)// orderDs 中选择key .equalTo(_.id)//gdsDs中选择key .window(TumblingProcessingTimeWindows.of(Time.minutes(1))) .apply(newCoGroupFunction[Order,Gds,RsInfo]{ overridedef coGroup(first: lang.Iterable[Order], second: lang.Iterable[Gds],out:Collector[RsInfo]):Unit={ //得到两个流中相同key的集合 } }) env.execute() }}
从源码角度分析CoGrop的实现
-
两个DataStream进行CoGroup得到的是一个CoGroupedStreams类型,后面的where、equalTo、window、apply之间的一些转换,最终得到一个WithWindow类型,包含两个dataStream、key选择、where条件、window等属性
-
重点:WithWindow 的apply方法
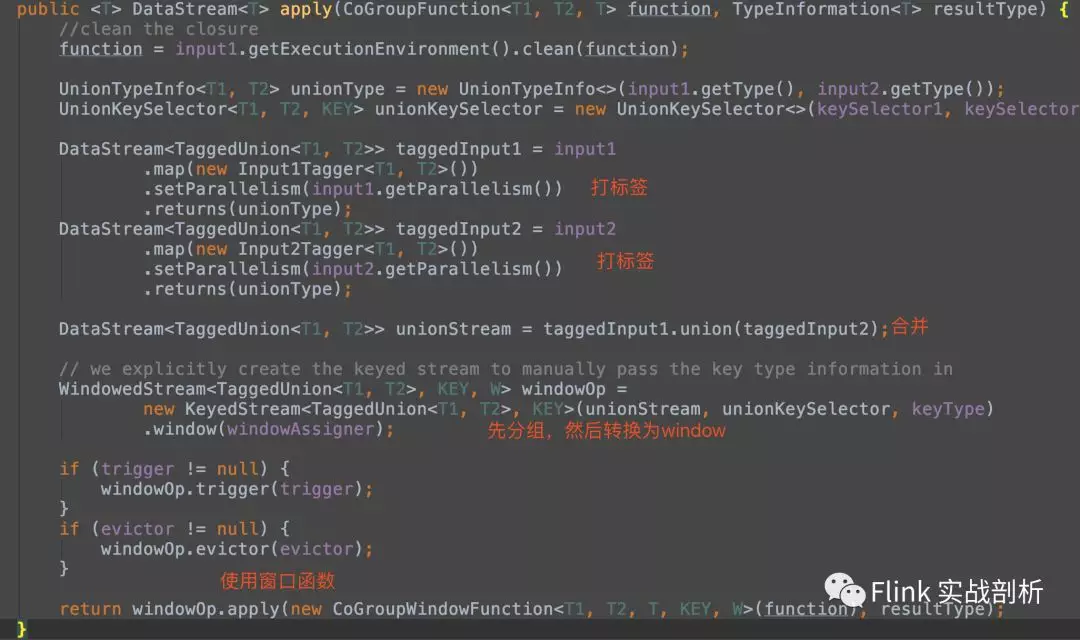
-
对两个DataStream打标签进行区分,得到TaggedUnion,TaggedUnion包含one、two两个属性,分别对应两个流
-
将两个打标签后的流TaggedUnion 进行union操作合并为一个DataStream类型流unionStream
-
unionStream根据不同的流选择对应where/equalTo条件进行keyBy 得到KeyedStream流
-
通过指定的window方式得到一个WindowedStream,然后apply一个被CoGroupWindowFunction包装之后的function,后续就是window的操作
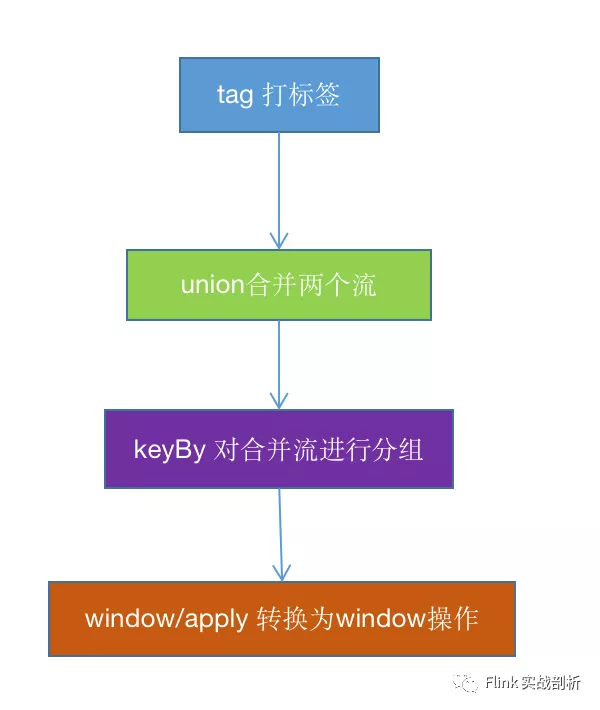
到这里已经将一个CoGroup操作转换为window操作,接着看后续是如何将相同的key的两个流的数据如何组合在一起的
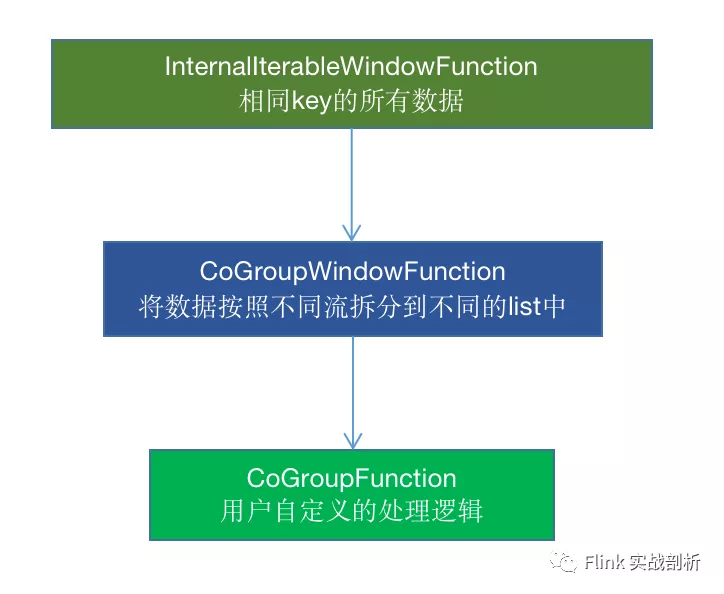
1. 在用户定义CoGroupFunction 被CoGroupWindowFunction包装之后,会接着被InternalIterableWindowFunction包装,一个窗口相同key的所有数据都会在一个Iterable中, 会将其传给CoGroupWindowFunction
2. 在CoGroupWindowFunction中,会将不同流的数据区分开来得到两个list,传给用户自定义的CoGroupFunction中