checkPoint简介
-
为了保证state的容错性,Flink需要对state进行checkpoint。
-
Checkpoint是Flink实现容错机制最核心的功能,它能够根据配置周期性地基于Stream中各个Operator/task的状态来生成快照,从而将这些状态数据定期持久化存储下来,当Flink程序一旦意外崩溃时,重新运行程序时可以有选择地从这些快照进行恢复,从而修正因为故障带来的程序数据异常
-
Flink的checkpoint机制可以与(stream和state)的持久化存储交互的前提:
-
持久化的source,它需要支持在一定时间内重放事件。这种sources的典型例子是持久化的消息队列(比如Apache Kafka,RabbitMQ等)或文件系统(比如HDFS,S3,GFS等)
-
用于state的持久化存储,例如分布式文件系统(比如HDFS,S3,GFS等)
-
checkPoint配置
-
默认checkpoint功能是disabled的,想要使用的时候需要先启用
-
checkpoint开启之后,默认的checkPointMode是Exactly-once
-
checkpoint的checkPointMode有两种,Exactly-once和At-least-once
-
Exactly-once对于大多数应用来说是最合适的。At-least-once可能用在某些延迟超低的应用程序(始终延迟为几毫秒)
-
默认checkpoint功能是disabled的,想要使用的时候需要先启用
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 每隔1000 ms进行启动一个检查点【设置checkpoint的周期】 env.enableCheckpointing(1000); // 高级选项: // 设置模式为exactly-once (这是默认值) env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); // 确保检查点之间有至少500 ms的间隔【checkpoint最小间隔】 env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500); // 检查点必须在一分钟内完成,或者被丢弃【checkpoint的超时时间】 env.getCheckpointConfig().setCheckpointTimeout(60000); // 同一时间只允许进行一个检查点 env.getCheckpointConfig().setMaxConcurrentCheckpoints(1); // 表示一旦Flink处理程序被cancel后,会保留Checkpoint数据,以便根据实际需要恢复到指定的Checkpoint【详细解释见备注】 env.getCheckpointConfig().enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION:表示一旦Flink处理程序被cancel后,会保留Checkpoint数据,以便根据实际需要恢复到指定的Checkpoint ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION: 表示一旦Flink处理程序被cancel后,会删除Checkpoint数据,只有job执行失败的时候才会保存checkpoint
State Backend(状态的后端存储)
-
默认情况下,state会保存在taskmanager的内存中,checkpoint会存储在JobManager的内存中。
-
state 的store和checkpoint的位置取决于State Backend的配置
- env.setStateBackend(…)
-
一共有三种State Backend
-
MemoryStateBackend
-
FsStateBackend
-
RocksDBStateBackend
-
-
MemoryStateBackend
-
state数据保存在java堆内存中,执行checkpoint的时候,会把state的快照数据保存到jobmanager的内存中
-
基于内存的Memory state backend在生产环境下不建议使用
-
-
FsStateBackend
-
state数据保存在taskmanager的内存中,执行checkpoint的时候,会把state的快照数据保存到配置的文件系统中
-
可以使用hdfs等分布式文件系统
-
-
RocksDBStateBackend
-
RocksDB跟上面的都略有不同,它会在本地文件系统中维护状态,state会直接写入本地rocksdb中。同时它需要配置一个远端的filesystem uri(一般是HDFS),在做checkpoint的时候,会把本地的数据直接复制到filesystem中。fail over的时候从filesystem中恢复到本地
-
RocksDB克服了state受内存限制的缺点,同时又能够持久化到远端文件系统中,比较适合在生产中使用
-
State Backend使用方式
修改State Backend的两种方式
-
第一种:单任务调整
-
修改当前任务代码
-
env.setStateBackend(new FsStateBackend("hdfs://namenode:9000/flink/checkpoints"));
-
或者new MemoryStateBackend()
-
或者new RocksDBStateBackend(filebackend, true);【需要添加第三方依赖】
-
-
第二种:全局调整
- 修改flink-conf.yaml
state.backend: filesystem state.checkpoints.dir: hdfs://namenode:9000/flink/checkpoints
-
-
注意:state.backend的值可以是下面几种:
-
jobmanager(MemoryStateBackend)
-
filesystem(FsStateBackend)
-
rocksdb(RocksDBStateBackend)
-
-
State backend演示
第一种:单任务调整
启动连接socket zzy:9001的程序
./bin/flink run -m yarn-cluster -yn 1 -yjm 1024 -ytm 1024 -c com.zzy.bigdata.flink.SocketWindowWordCountJavaCheckPoint zzy_flink_learn.jar --port 9001
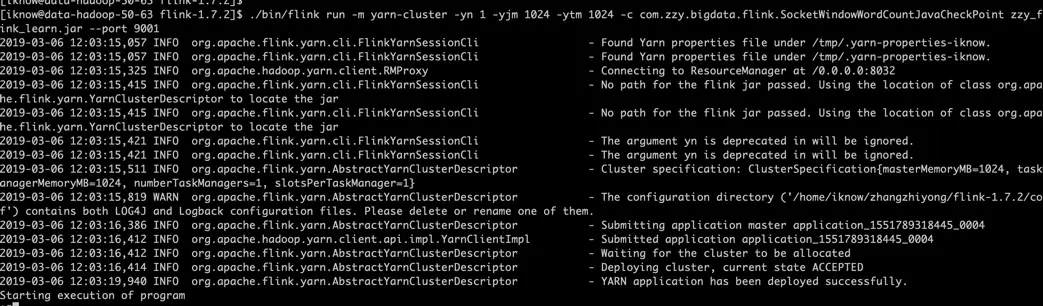
[iknow@data-5-63 flink-1.7.2]$ ./bin/flink run -m yarn-cluster -yn 1 -yjm 1024 -ytm 1024 -c com.zzy.bigdata.flink.SocketWindowWordCountJavaCheckPoint zzy_flink_learn.jar --port 9001 2019-03-06 12:03:15,057 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - Found Yarn properties file under /tmp/.yarn-properties-iknow. 2019-03-06 12:03:15,057 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - Found Yarn properties file under /tmp/.yarn-properties-iknow. 2019-03-06 12:03:15,325 INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at /0.0.0.0:8032 2019-03-06 12:03:15,415 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar 2019-03-06 12:03:15,415 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar 2019-03-06 12:03:15,421 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - The argument yn is deprecated in will be ignored. 2019-03-06 12:03:15,421 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - The argument yn is deprecated in will be ignored. 2019-03-06 12:03:15,511 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Cluster specification: ClusterSpecification{masterMemoryMB=1024, taskManagerMemoryMB=1024, numberTaskManagers=1, slotsPerTaskManager=1} 2019-03-06 12:03:15,819 WARN org.apache.flink.yarn.AbstractYarnClusterDescriptor - The configuration directory ('/home/iknow/zhangzhiyong/flink-1.7.2/conf') contains both LOG4J and Logback configuration files. Please delete or rename one of them. 2019-03-06 12:03:16,386 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Submitting application master application_1551789318445_0004 2019-03-06 12:03:16,412 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl - Submitted application application_1551789318445_0004 2019-03-06 12:03:16,412 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Waiting for the cluster to be allocated 2019-03-06 12:03:16,414 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Deploying cluster, current state ACCEPTED 2019-03-06 12:03:19,940 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - YARN application has been deployed successfully. Starting execution of program
如果zzy上未开启9001端口,到jobManager的web ui上看到会报下面的错
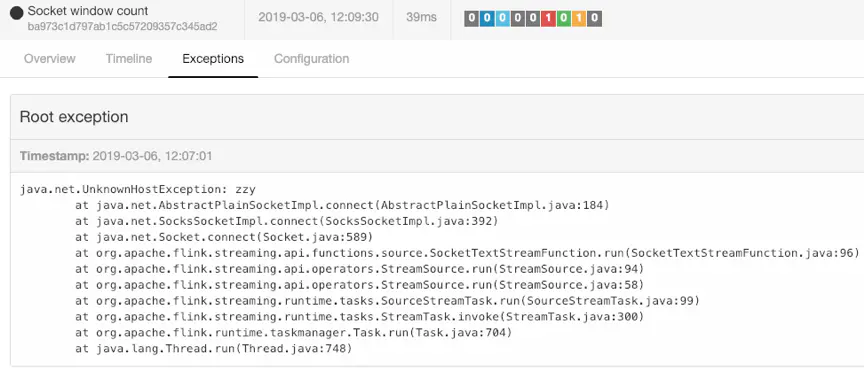
代码里设置了checkpoint
//获取flink的运行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //默认checkpoint功能是disabled的,想要使用的时候需要先启用;每隔10000ms进行启动一个检查点【设置checkpoint的周期】 env.enableCheckpointing(10000); // 高级选项: // 设置模式为exactly-once (这是默认值) env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); // 确保检查点之间有至少500ms的间隔【checkpoint最小间隔】 env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500); // 检查点必须在一分钟内完成,或者被丢弃【checkpoint的超时时间】 env.getCheckpointConfig().setCheckpointTimeout(60000); // 同一时间只允许进行一个检查点 env.getCheckpointConfig().setMaxConcurrentCheckpoints(1); // 表示一旦Flink处理程序被cancel后,会保留Checkpoint数据,以便根据实际需要恢复到指定的Checkpoint【详细解释见备注】 env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); //ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION:表示一旦Flink处理程序被cancel后,会保留Checkpoint数据,以便根据实际需要恢复到指定的Checkpoint //ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION: 表示一旦Flink处理程序被cancel后,会删除Checkpoint数据,只有job执行失败的时候才会保存checkpoint //设置statebackend //env.setStateBackend(new MemoryStateBackend()); //env.setStateBackend(new FsStateBackend("hdfs://zzy:9000/flink/checkpoints")); //rocksDB需要引入依赖flink-statebackend-rocksdb_2.11 //env.setStateBackend(new RocksDBStateBackend("hdfs://zzy:9000/flink/checkpoints",true)); env.setStateBackend(new FsStateBackend("hdfs://192.168.5.63:9000/flink/checkpoints"));
但是JobManager的web ui上checkpoint并未触发

报错如下,应该是连接不到zzy 9001,识别不了zzy
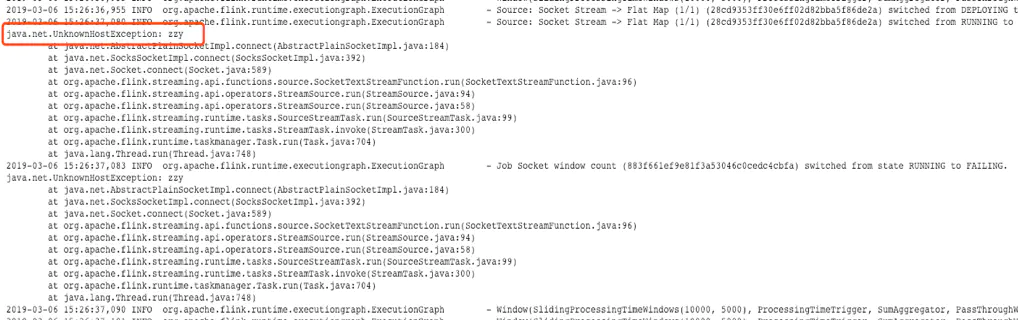
选择监听50.63上的9001端口,如果没有nc命令,用
yum install -y nc
安装下,用下面的命令启动flink程序,采用flink on yarn的方式
./bin/flink run -m yarn-cluster -yn 1 -yjm 1024 -ytm 1024 -c com.zzy.bigdata.flink.SocketWindowWordCountJavaCheckPoint zzy_flink_learn.jar --port 9001
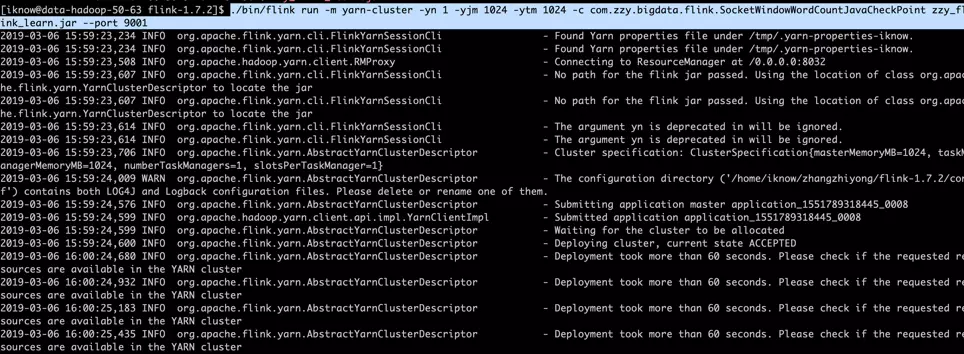
2019-03-06 16:00:24,680 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Deployment took more than 60 seconds. Please check if the requested resources are available in the YARN cluster
这里杀掉application_1551789318445_0007和application_1551789318445_0008(这两台是测试机器,资源很紧张)

然后再次重启程序
注意yarn是不是successfully.的状态

Yarn上启动了应用application_1551789318445_0009
点击AM进去jobManager的web ui界面

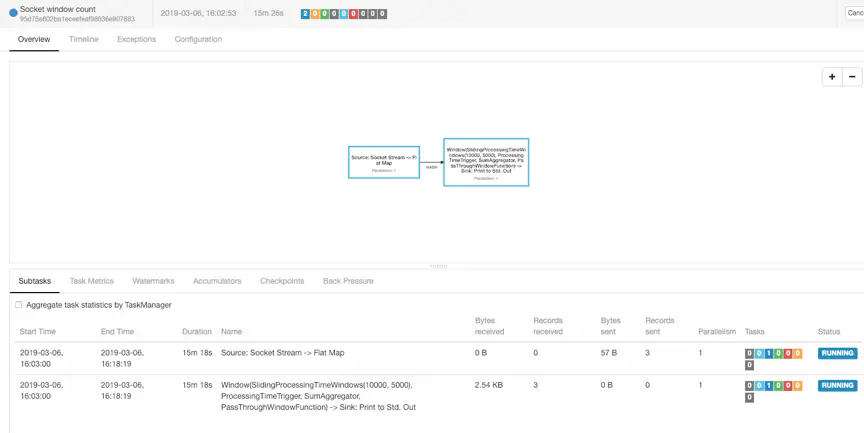


Checkpoint的UI


可以看到每隔10s进行一次checkpoint



Hdfs上查看checkpoint数据,看到保存了最近10次的checkpoint数据

参考链接:
https://www.jianshu.com/p/e950cfbcd782?from=singlemessage
https://gatsbynewton.blog.csdn.net/article/details/105905925
https://www.cnblogs.com/lovellll/p/10093858.html
https://www.pianshen.com/article/8090948392/
链接:https://www.jianshu.com/p/3cd2ab1dd311
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。