1 基于时间的双流Join
数据流操作的另一个常见需求是对两条数据流中的事件进行联结(connect)或Join。Flink DataStream API中内置有两个可以根据时间条件对数据流进行Join的算子:基于间隔的Join和基于窗口的Join。本节我们会对它们进行介绍。
如果Flink内置的Join算子无法表达所需的Join语义,那么你可以通过CoProcessFunction、BroadcastProcessFunction或KeyedBroadcastProcessFunction实现自定义的Join逻辑。
注意,你要设计的Join算子需要具备高效的状态访问模式及有效的状态清理策略。
1.1 基于间隔的Join
基于间隔的Join会对两条流中拥有相同键值以及彼此之间时间戳不超过某一指定间隔的事件进行Join。
下图展示了两条流(A和B)上基于间隔的Join,如果B中事件的时间戳相较于A中事件的时间戳不早于1小时且不晚于15分钟,则会将两个事件Join起来。Join间隔具有对称性,因此上面的条件也可以表示为A中事件的时间戳相较B中事件的时间戳不早于15分钟且不晚于1小时。
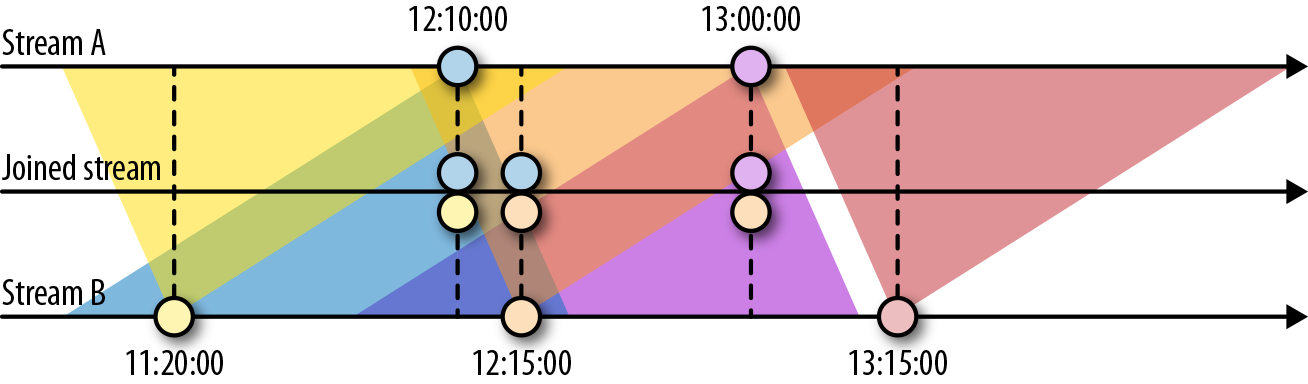
基于间隔的Join目前只支持事件时间以及INNER JOIN语义(无法发出未匹配成功的事件)。下面的例子定义了一个基于间隔的Join。
input1 .intervalJoin(input2) .between(<lower-bound>, <upper-bound>) // 相对于input1的上下界 .process(ProcessJoinFunction) // 处理匹配的事件对
Join成功的事件对会发送给ProcessJoinFunction。下界和上界分别由负时间间隔和正时间间隔来定义,例如between(Time.hour(-1), Time.minute(15))。在满足下界值小于上界值的前提下,你可以任意对它们赋值。例如,允许出现B中事件的时间戳相较A中事件的时间戳早1~2小时这样的条件。
基于间隔的Join需要同时对双流的记录进行缓冲。对第一个输入而言,所有时间戳大于当前水位线减去间隔上界的数据都会被缓冲起来;对第二个输入而言,所有时间戳大于当前水位线加上间隔下界的数据都会被缓冲起来。注意,两侧边界值都有可能为负。上图中的Join需要存储数据流A中所有时间戳大于当前水位线减去15分钟的记录,以及数据流B中所有时间戳大于当前水位线减去1小时的记录。不难想象,如果两条流的事件时间不同步,那么Join所需的存储就会显著增加,因为水位线总是由“较慢”的那条流来决定。
例子:每个用户的点击Join这个用户最近10分钟内的浏览
scala version
object IntervalJoinExample { def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment env.setParallelism(1) env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) /* A.intervalJoin(B).between(lowerBound, upperBound) B.intervalJoin(A).between(-upperBound, -lowerBound) */ val stream1 = env .fromElements( ("user_1", 10 * 60 * 1000L, "click"), ("user_1", 16 * 60 * 1000L, "click") ) .assignAscendingTimestamps(_._2) .keyBy(r => r._1) val stream2 = env .fromElements( ("user_1", 5 * 60 * 1000L, "browse"), ("user_1", 6 * 60 * 1000L, "browse") ) .assignAscendingTimestamps(_._2) .keyBy(r => r._1) stream1 .intervalJoin(stream2) .between(Time.minutes(-10), Time.minutes(0)) .process(new ProcessJoinFunction[(String, Long, String), (String, Long, String), String] { override def processElement(in1: (String, Long, String), in2: (String, Long, String), context: ProcessJoinFunction[(String, Long, String), (String, Long, String), String]#Context, collector: Collector[String]): Unit = { collector.collect(in1 + " => " + in2) } }) .print() stream2 .intervalJoin(stream1) .between(Time.minutes(0), Time.minutes(10)) .process(new ProcessJoinFunction[(String, Long, String), (String, Long, String), String] { override def processElement(in1: (String, Long, String), in2: (String, Long, String), context: ProcessJoinFunction[(String, Long, String), (String, Long, String), String]#Context, collector: Collector[String]): Unit = { collector.collect(in1 + " => " + in2) } }) .print() env.execute() } }
java version
public class IntervalJoinExample { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); env.setParallelism(1); KeyedStream<Tuple3<String, Long, String>, String> stream1 = env .fromElements( Tuple3.of("user_1", 10 * 60 * 1000L, "click") ) .assignTimestampsAndWatermarks( WatermarkStrategy .<Tuple3<String, Long, String>>forMonotonousTimestamps() .withTimestampAssigner(new SerializableTimestampAssigner<Tuple3<String, Long, String>>() { @Override public long extractTimestamp(Tuple3<String, Long, String> stringLongStringTuple3, long l) { return stringLongStringTuple3.f1; } }) ) .keyBy(r -> r.f0); KeyedStream<Tuple3<String, Long, String>, String> stream2 = env .fromElements( Tuple3.of("user_1", 5 * 60 * 1000L, "browse"), Tuple3.of("user_1", 6 * 60 * 1000L, "browse") ) .assignTimestampsAndWatermarks( WatermarkStrategy .<Tuple3<String, Long, String>>forMonotonousTimestamps() .withTimestampAssigner(new SerializableTimestampAssigner<Tuple3<String, Long, String>>() { @Override public long extractTimestamp(Tuple3<String, Long, String> stringLongStringTuple3, long l) { return stringLongStringTuple3.f1; } }) ) .keyBy(r -> r.f0); stream1 .intervalJoin(stream2) .between(Time.minutes(-10), Time.minutes(0)) .process(new ProcessJoinFunction<Tuple3<String, Long, String>, Tuple3<String, Long, String>, String>() { @Override public void processElement(Tuple3<String, Long, String> stringLongStringTuple3, Tuple3<String, Long, String> stringLongStringTuple32, Context context, Collector<String> collector) throws Exception { collector.collect(stringLongStringTuple3 + " => " + stringLongStringTuple32); } }) .print(); env.execute(); } }
1.2 基于窗口的Join
顾名思义,基于窗口的Join需要用到Flink中的窗口机制。其原理是将两条输入流中的元素分配到公共窗口中并在窗口完成时进行Join(或Cogroup)。
下面的例子展示了如何定义基于窗口的Join。
input1.join(input2) .where(...) // 为input1指定键值属性 .equalTo(...) // 为input2指定键值属性 .window(...) // 指定WindowAssigner [.trigger(...)] // 选择性的指定Trigger [.evictor(...)] // 选择性的指定Evictor .apply(...) // 指定JoinFunction
下图展示了DataStream API中基于窗口的Join是如何工作的。
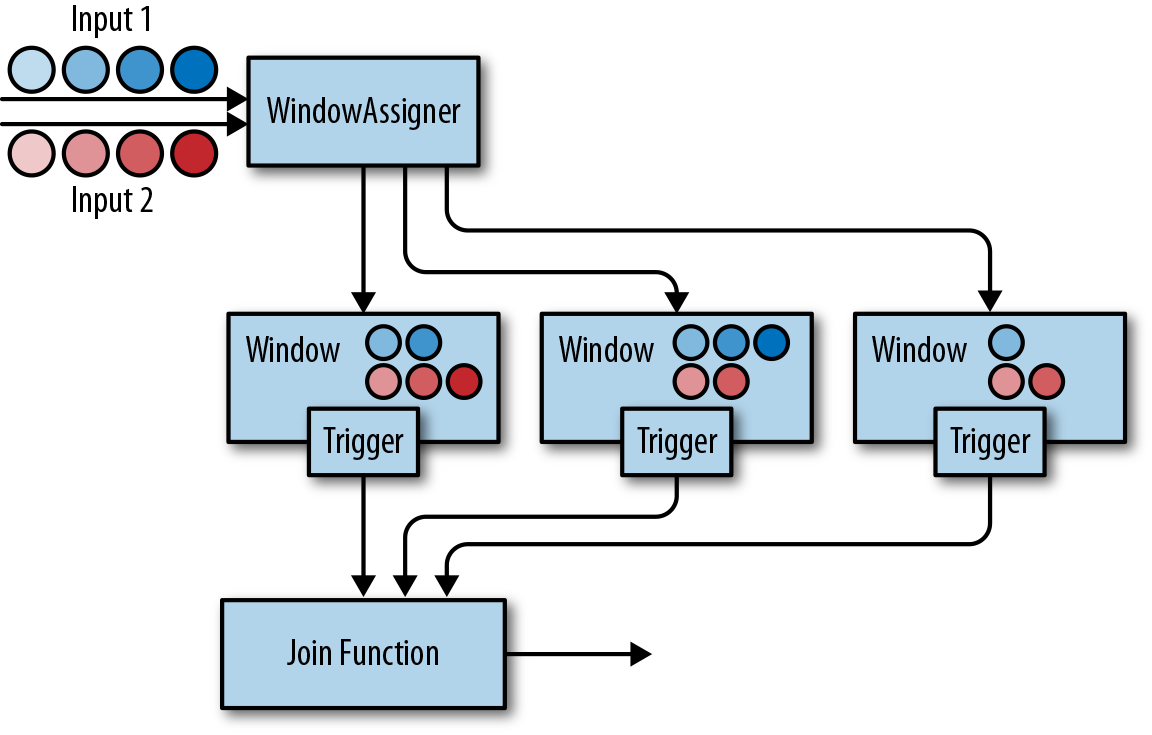
两条输入流都会根据各自的键值属性进行分区,公共窗口分配器会将二者的事件映射到公共窗口内(其中同时存储了两条流中的数据)。当窗口的计时器触发时,算子会遍历两个输入中元素的每个组合(叉乘积)去调用JoinFunction。同时你也可以自定义触发器或移除器。由于两条流中的事件会被映射到同一个窗口中,因此该过程中的触发器和移除器与常规窗口算子中的完全相同。
除了对窗口中的两条流进行Join,你还可以对它们进行Cogroup,只需将算子定义开始位置的join改为coGroup()即可。Join和Cogroup的总体逻辑相同,二者的唯一区别是:Join会为两侧输入中的每个事件对调用JoinFunction;而Cogroup中用到的CoGroupFunction会以两个输入的元素遍历器为参数,只在每个窗口中被调用一次。
注意,对划分窗口后的数据流进行Join可能会产生意想不到的语义。例如,假设你为执行Join操作的算子配置了1小时的滚动窗口,那么一旦来自两个输入的元素没有被划分到同一窗口,它们就无法Join在一起,即使二者彼此仅相差1秒钟。
scala version
object TwoWindowJoinExample { def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) env.setParallelism(1) val stream1 = env .fromElements( ("a", 1000L), ("a", 2000L) ) .assignAscendingTimestamps(_._2) val stream2 = env .fromElements( ("a", 3000L), ("a", 4000L) ) .assignAscendingTimestamps(_._2) stream1 .join(stream2) // on A.id = B.id .where(_._1) .equalTo(_._1) .window(TumblingEventTimeWindows.of(Time.seconds(5))) .apply(new JoinFunction[(String, Long), (String, Long), String] { override def join(in1: (String, Long), in2: (String, Long)): String = { in1 + " => " + in2 } }) .print() env.execute() } }
java version
public class TwoWindowJoinExample { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); DataStream<Tuple2<String, Long>> stream1 = env .fromElements( Tuple2.of("a", 1000L), Tuple2.of("b", 1000L), Tuple2.of("a", 2000L), Tuple2.of("b", 2000L) ) .assignTimestampsAndWatermarks( WatermarkStrategy .<Tuple2<String, Long>>forMonotonousTimestamps() .withTimestampAssigner( new SerializableTimestampAssigner<Tuple2<String, Long>>() { @Override public long extractTimestamp(Tuple2<String, Long> stringLongTuple2, long l) { return stringLongTuple2.f1; } } ) ); DataStream<Tuple2<String, Long>> stream2 = env .fromElements( Tuple2.of("a", 3000L), Tuple2.of("b", 3000L), Tuple2.of("a", 4000L), Tuple2.of("b", 4000L) ) .assignTimestampsAndWatermarks( WatermarkStrategy .<Tuple2<String, Long>>forMonotonousTimestamps() .withTimestampAssigner( new SerializableTimestampAssigner<Tuple2<String, Long>>() { @Override public long extractTimestamp(Tuple2<String, Long> stringLongTuple2, long l) { return stringLongTuple2.f1; } } ) ); stream1 .join(stream2) .where(r -> r.f0) .equalTo(r -> r.f0) .window(TumblingEventTimeWindows.of(Time.seconds(5))) .apply(new JoinFunction<Tuple2<String, Long>, Tuple2<String, Long>, String>() { @Override public String join(Tuple2<String, Long> stringLongTuple2, Tuple2<String, Long> stringLongTuple22) throws Exception { return stringLongTuple2 + " => " + stringLongTuple22; } }) .print(); env.execute(); } }
2 处理迟到的元素
水位线可以用来平衡计算的完整性和延迟两方面。除非我们选择一种非常保守的水位线策略(最大延时设置的非常大,以至于包含了所有的元素,但结果是非常大的延迟),否则我们总需要处理迟到的元素。
迟到的元素是指当这个元素来到时,这个元素所对应的窗口已经计算完毕了(也就是说水位线已经没过窗口结束时间了)。这说明迟到这个特性只针对事件时间。
DataStream API提供了三种策略来处理迟到元素
- 直接抛弃迟到的元素
- 将迟到的元素发送到另一条流中去
- 可以更新窗口已经计算完的结果,并发出计算结果。
2.1 抛弃迟到元素
抛弃迟到的元素是event time window operator的默认行为。也就是说一个迟到的元素不会创建一个新的窗口。
process function可以通过比较迟到元素的时间戳和当前水位线的大小来很轻易的过滤掉迟到元素。
2.2 重定向迟到元素
迟到的元素也可以使用侧输出(side output)特性被重定向到另外的一条流中去。迟到元素所组成的侧输出流可以继续处理或者sink到持久化设施中去。
例子
scala version
val readings = env .socketTextStream("localhost", 9999, ' ') .map(line => { val arr = line.split(" ") (arr(0), arr(1).toLong * 1000) }) .assignAscendingTimestamps(_._2) val countPer10Secs = readings .keyBy(_._1) .timeWindow(Time.seconds(10)) .sideOutputLateData( new OutputTag[(String, Long)]("late-readings") ) .process(new CountFunction()) val lateStream = countPer10Secs .getSideOutput( new OutputTag[(String, Long)]("late-readings") ) lateStream.print()
实现CountFunction:
class CountFunction extends ProcessWindowFunction[(String, Long), String, String, TimeWindow] { override def process(key: String, context: Context, elements: Iterable[(String, Long)], out: Collector[String]): Unit = { out.collect("窗口共有" + elements.size + "条数据") } }
java version
public class RedirectLateEvent { private static OutputTag<Tuple2<String, Long>> output = new OutputTag<Tuple2<String, Long>>("late-readings"){}; public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); DataStream<Tuple2<String, Long>> stream = env .socketTextStream("localhost", 9999) .map(new MapFunction<String, Tuple2<String, Long>>() { @Override public Tuple2<String, Long> map(String s) throws Exception { String[] arr = s.split(" "); return Tuple2.of(arr[0], Long.parseLong(arr[1]) * 1000L); } }) .assignTimestampsAndWatermarks( WatermarkStrategy. // like scala: assignAscendingTimestamps(_._2) <Tuple2<String, Long>>forMonotonousTimestamps() .withTimestampAssigner(new SerializableTimestampAssigner<Tuple2<String, Long>>() { @Override public long extractTimestamp(Tuple2<String, Long> value, long l) { return value.f1; } }) ); SingleOutputStreamOperator<String> lateReadings = stream .keyBy(r -> r.f0) .timeWindow(Time.seconds(5)) .sideOutputLateData(output) // use after keyBy and timeWindow .process(new ProcessWindowFunction<Tuple2<String, Long>, String, String, TimeWindow>() { @Override public void process(String s, Context context, Iterable<Tuple2<String, Long>> iterable, Collector<String> collector) throws Exception { long exactSizeIfKnown = iterable.spliterator().getExactSizeIfKnown(); collector.collect(exactSizeIfKnown + " of elements"); } }); lateReadings.print(); lateReadings.getSideOutput(output).print(); env.execute(); } }
下面这个例子展示了ProcessFunction如何过滤掉迟到的元素然后将迟到的元素发送到侧输出流中去。
scala version
val readings: DataStream[SensorReading] = ... val filteredReadings: DataStream[SensorReading] = readings .process(new LateReadingsFilter) // retrieve late readings val lateReadings: DataStream[SensorReading] = filteredReadings .getSideOutput(new OutputTag[SensorReading]("late-readings")) /** A ProcessFunction that filters out late sensor readings and * re-directs them to a side output */ class LateReadingsFilter extends ProcessFunction[SensorReading, SensorReading] { val lateReadingsOut = new OutputTag[SensorReading]("late-readings") override def processElement( SensorReading r, ctx: ProcessFunction[SensorReading, SensorReading]#Context, out: Collector[SensorReading]): Unit = { // compare record timestamp with current watermark if (r.timestamp < ctx.timerService().currentWatermark()) { // this is a late reading => redirect it to the side output ctx.output(lateReadingsOut, r) } else { out.collect(r) } } }
java version
public class RedirectLateEvent { private static OutputTag<String> output = new OutputTag<String>("late-readings"){}; public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); SingleOutputStreamOperator<Tuple2<String, Long>> stream = env .socketTextStream("localhost", 9999) .map(new MapFunction<String, Tuple2<String, Long>>() { @Override public Tuple2<String, Long> map(String s) throws Exception { String[] arr = s.split(" "); return Tuple2.of(arr[0], Long.parseLong(arr[1]) * 1000L); } }) .assignTimestampsAndWatermarks( WatermarkStrategy. <Tuple2<String, Long>>forMonotonousTimestamps() .withTimestampAssigner(new SerializableTimestampAssigner<Tuple2<String, Long>>() { @Override public long extractTimestamp(Tuple2<String, Long> value, long l) { return value.f1; } }) ) .process(new ProcessFunction<Tuple2<String, Long>, Tuple2<String, Long>>() { @Override public void processElement(Tuple2<String, Long> stringLongTuple2, Context context, Collector<Tuple2<String, Long>> collector) throws Exception { if (stringLongTuple2.f1 < context.timerService().currentWatermark()) { context.output(output, "late event is comming!"); } else { collector.collect(stringLongTuple2); } } }); stream.print(); stream.getSideOutput(output).print(); env.execute(); } }
2.3 使用迟到元素更新窗口计算结果
由于存在迟到的元素,所以已经计算出的窗口结果是不准确和不完全的。我们可以使用迟到元素更新已经计算完的窗口结果。
如果我们要求一个operator支持重新计算和更新已经发出的结果,就需要在第一次发出结果以后也要保存之前所有的状态。但显然我们不能一直保存所有的状态,肯定会在某一个时间点将状态清空,而一旦状态被清空,结果就再也不能重新计算或者更新了。而迟到的元素只能被抛弃或者发送到侧输出流。
window operator API提供了方法来明确声明我们要等待迟到元素。当使用event-time window,我们可以指定一个时间段叫做allowed lateness。window operator如果设置了allowed lateness,这个window operator在水位线没过窗口结束时间时也将不会删除窗口和窗口中的状态。窗口会在一段时间内(allowed lateness设置的)保留所有的元素。
当迟到元素在allowed lateness时间内到达时,这个迟到元素会被实时处理并发送到触发器(trigger)。当水位线没过了窗口结束时间+allowed lateness时间时,窗口会被删除,并且所有后来的迟到的元素都会被丢弃。
Allowed lateness可以使用allowedLateness()方法来指定,如下所示:
val readings: DataStream[SensorReading] = ... val countPer10Secs: DataStream[(String, Long, Int, String)] = readings .keyBy(_.id) .timeWindow(Time.seconds(10)) // process late readings for 5 additional seconds .allowedLateness(Time.seconds(5)) // count readings and update results if late readings arrive .process(new UpdatingWindowCountFunction) /** A counting WindowProcessFunction that distinguishes between * first results and updates. */ class UpdatingWindowCountFunction extends ProcessWindowFunction[SensorReading, (String, Long, Int, String), String, TimeWindow] { override def process( id: String, ctx: Context, elements: Iterable[SensorReading], out: Collector[(String, Long, Int, String)]): Unit = { // count the number of readings val cnt = elements.count(_ => true) // state to check if this is // the first evaluation of the window or not val isUpdate = ctx.windowState.getState( new ValueStateDescriptor[Boolean]( "isUpdate", Types.of[Boolean])) if (!isUpdate.value()) { // first evaluation, emit first result out.collect((id, ctx.window.getEnd, cnt, "first")) isUpdate.update(true) } else { // not the first evaluation, emit an update out.collect((id, ctx.window.getEnd, cnt, "update")) } } }
java version
public class UpdateWindowResultWithLateEvent { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); DataStreamSource<String> stream = env.socketTextStream("localhost", 9999); stream .map(new MapFunction<String, Tuple2<String, Long>>() { @Override public Tuple2<String, Long> map(String s) throws Exception { String[] arr = s.split(" "); return Tuple2.of(arr[0], Long.parseLong(arr[1]) * 1000L); } }) .assignTimestampsAndWatermarks( WatermarkStrategy.<Tuple2<String, Long>>forBoundedOutOfOrderness(Duration.ofSeconds(5)) .withTimestampAssigner(new SerializableTimestampAssigner<Tuple2<String, Long>>() { @Override public long extractTimestamp(Tuple2<String, Long> stringLongTuple2, long l) { return stringLongTuple2.f1; } }) ) .keyBy(r -> r.f0) .timeWindow(Time.seconds(5)) .allowedLateness(Time.seconds(5)) .process(new UpdateWindowResult()) .print(); env.execute(); } public static class UpdateWindowResult extends ProcessWindowFunction<Tuple2<String, Long>, String, String, TimeWindow> { @Override public void process(String s, Context context, Iterable<Tuple2<String, Long>> iterable, Collector<String> collector) throws Exception { long count = 0L; for (Tuple2<String, Long> i : iterable) { count += 1; } // 可见范围比getRuntimeContext.getState更小,只对当前key、当前window可见 // 基于窗口的状态变量,只能当前key和当前窗口访问 ValueState<Boolean> isUpdate = context.windowState().getState( new ValueStateDescriptor<Boolean>("isUpdate", Types.BOOLEAN) ); // 当水位线超过窗口结束时间时,触发窗口的第一次计算! if (isUpdate.value() == null) { collector.collect("窗口第一次触发计算!一共有 " + count + " 条数据!"); isUpdate.update(true); } else { collector.collect("窗口更新了!一共有 " + count + " 条数据!"); } } } }