1)顺序写磁盘
Kafka 的 producer 生产数据,要写入到 log 文件中,写的过程是一直追加到文件末端,为顺序写。官网有数据表明,同样的磁盘,顺序写能到 600M/s,而随机写只有 100K/s。这
与磁盘的机械机构有关,顺序写之所以快,是因为其省去了大量磁头寻址的时间。
2)应用
Kafka数据持久化是直接持久化到Pagecache中,这样会产生以下几个好处:
- I/O Scheduler 会将连续的小块写组装成大块的物理写从而提高性能
- I/O Scheduler 会尝试将一些写操作重新按顺序排好,从而减少磁盘头的移动时间
- 充分利用所有空闲内存(非 JVM 内存)。如果使用应用层 Cache(即 JVM 堆内存),会增加 GC 负担
- 读操作可直接在 Page Cache 内进行。如果消费和生产速度相当,甚至不需要通过物理磁盘(直接通过 Page Cache)交换数据
- 如果进程重启,JVM 内的 Cache 会失效,但 Page Cache 仍然可用
尽管持久化到Pagecache上可能会造成宕机丢失数据的情况,但这可以被Kafka的Replication机制解决。如果为了保证这种情况下数据不丢失而强制将 Page Cache 中的数据 Flush 到磁盘,反而会降低性能
3)零复制技术
原始复制
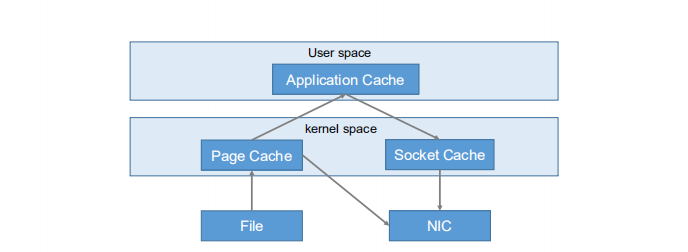
kafka复制
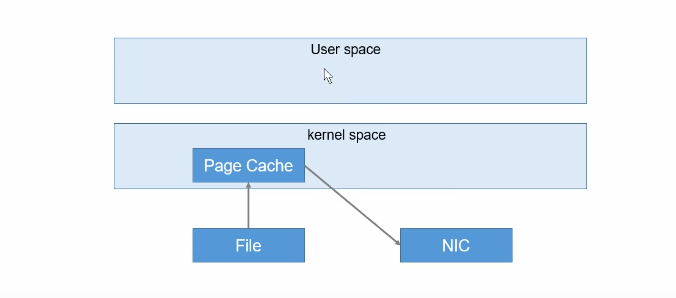
kafka中的消费者在读取服务端的数据时,需要将服务端的磁盘文件通过网络发送到消费者进程,网络发送需要经过几种网络节点。如下图所示:
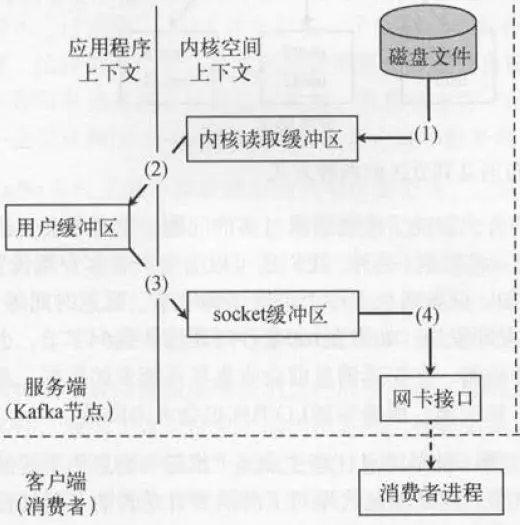
传统的读取文件数据并发送到网络的步骤如下:
(1)操作系统将数据从磁盘文件中读取到内核空间的页面缓存;
(2)应用程序将数据从内核空间读入用户空间缓冲区;
(3)应用程序将读到数据写回内核空间并放入socket缓冲区;
(4)操作系统将数据从socket缓冲区复制到网卡接口,此时数据才能通过网络发送。
通常情况下,Kafka的消息会有多个订阅者,生产者发布的消息会被不同的消费者多次消费,为了优化这个流程,Kafka使用了“零拷贝技术”,如下图所示:
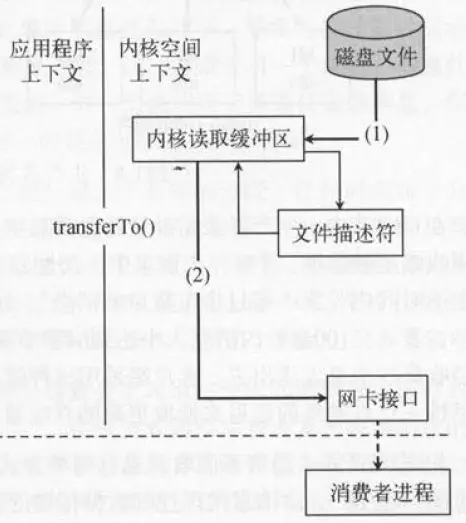
“零拷贝技术”只用将磁盘文件的数据复制到页面缓存中一次,然后将数据从页面缓存直接发送到网络中(发送给不同的订阅者时,都可以使用同一个页面缓存),避免了重复复制操作。
如果有10个消费者,传统方式下,数据复制次数为4*10=40次,而使用“零拷贝技术”只需要1+10=11次,一次为从磁盘复制到页面缓存,10次表示10个消费者各自读取一次页面缓存。
链接:https://www.jianshu.com/p/835ec2d4c170
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。