1 执行计划(Explain)
1)基本语法
EXPLAIN [EXTENDED | DEPENDENCY | AUTHORIZATION] query
2)案例实操
(1)查看下面这条语句的执行计划
没有生成 MR 任务的
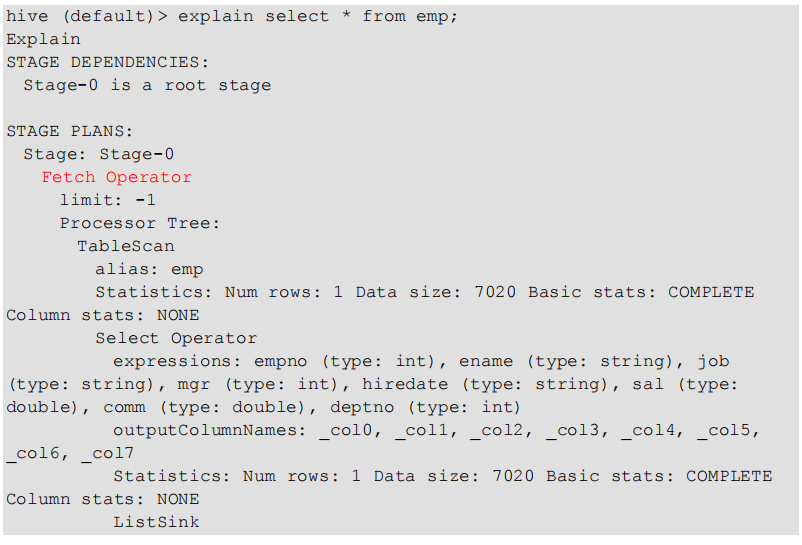
有生成 MR 任务的
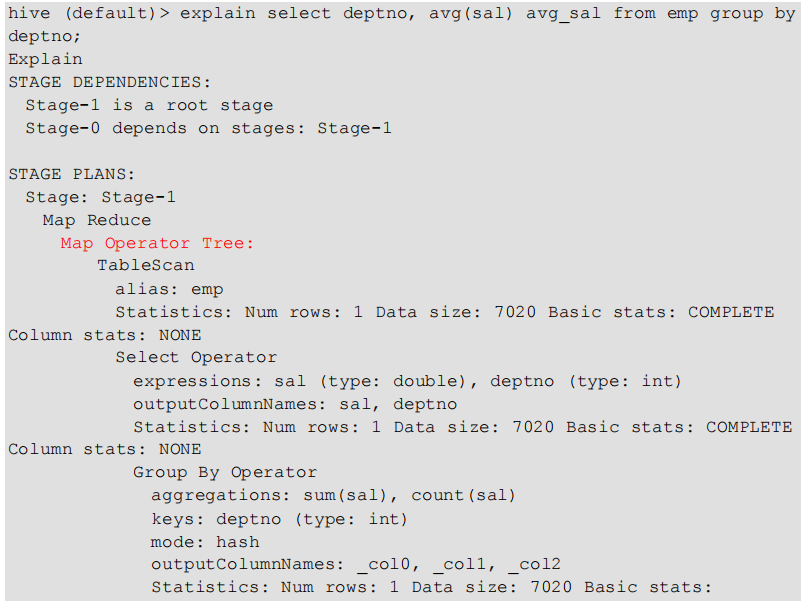
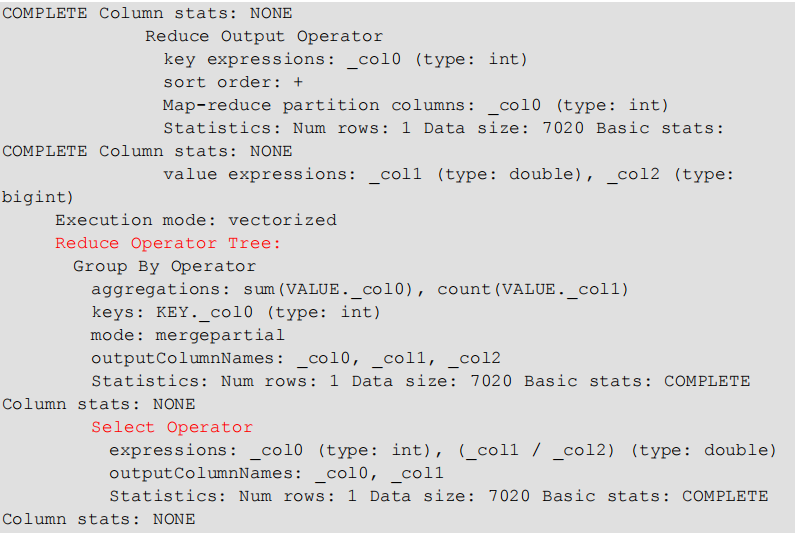
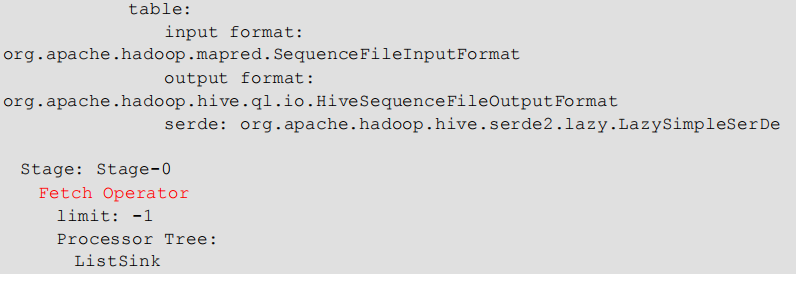
(2)查看详细执行计划

2 Fetch 抓取
Fetch 抓取是指,Hive 中对某些情况的查询可以不必使用 MapReduce 计算。例如:SELECT * FROM employees;在这种情况下,Hive 可以简单地读取 employee 对应的存储目录下的文件,
然后输出查询结果到控制台。
在 hive-default.xml.template 文件中 hive.fetch.task.conversion 默认是 more,老版本 hive默认是 minimal,该属性修改为 more 以后,在全局查找、字段查找、limit 查找等都不走
mapreduce。

1)案例实操:
(1)把 hive.fetch.task.conversion 设置成 none,然后执行查询语句,都会执行 mapreduce程序。
hive (default)> set hive.fetch.task.conversion=none; hive (default)> select * from emp; hive (default)> select ename from emp; hive (default)> select ename from emp limit 3;
(2)把 hive.fetch.task.conversion 设置成 more,然后执行查询语句,如下查询方式都不会执行 mapreduce 程序。
hive (default)> set hive.fetch.task.conversion=more; hive (default)> select * from emp; hive (default)> select ename from emp; hive (default)> select ename from emp limit 3;
3 本地模式
大多数的 Hadoop Job 是需要 Hadoop 提供的完整的可扩展性来处理大数据集的。不过,有时 Hive 的输入数据量是非常小的。在这种情况下,为查询触发执行任务消耗的时间可能
会比实际 job 的执行时间要多的多。对于大多数这种情况,Hive 可以通过本地模式在单台机器上处理所有的任务。对于小数据集,执行时间可以明显被缩短。
用户可以通过设置 hive.exec.mode.local.auto 的值为 true,来让 Hive 在适当的时候自动启动这个优化。

1)案例实操:
(2)关闭本地模式(默认是关闭的),并执行查询语句
hive (default)> select count(*) from emp group by deptno;
(1)开启本地模式,并执行查询语句
hive (default)> set hive.exec.mode.local.auto=true;
hive (default)> select count(*) from emp group by deptno;