1 django、flask、tornado框架的比较?
2 什么是wsgi?
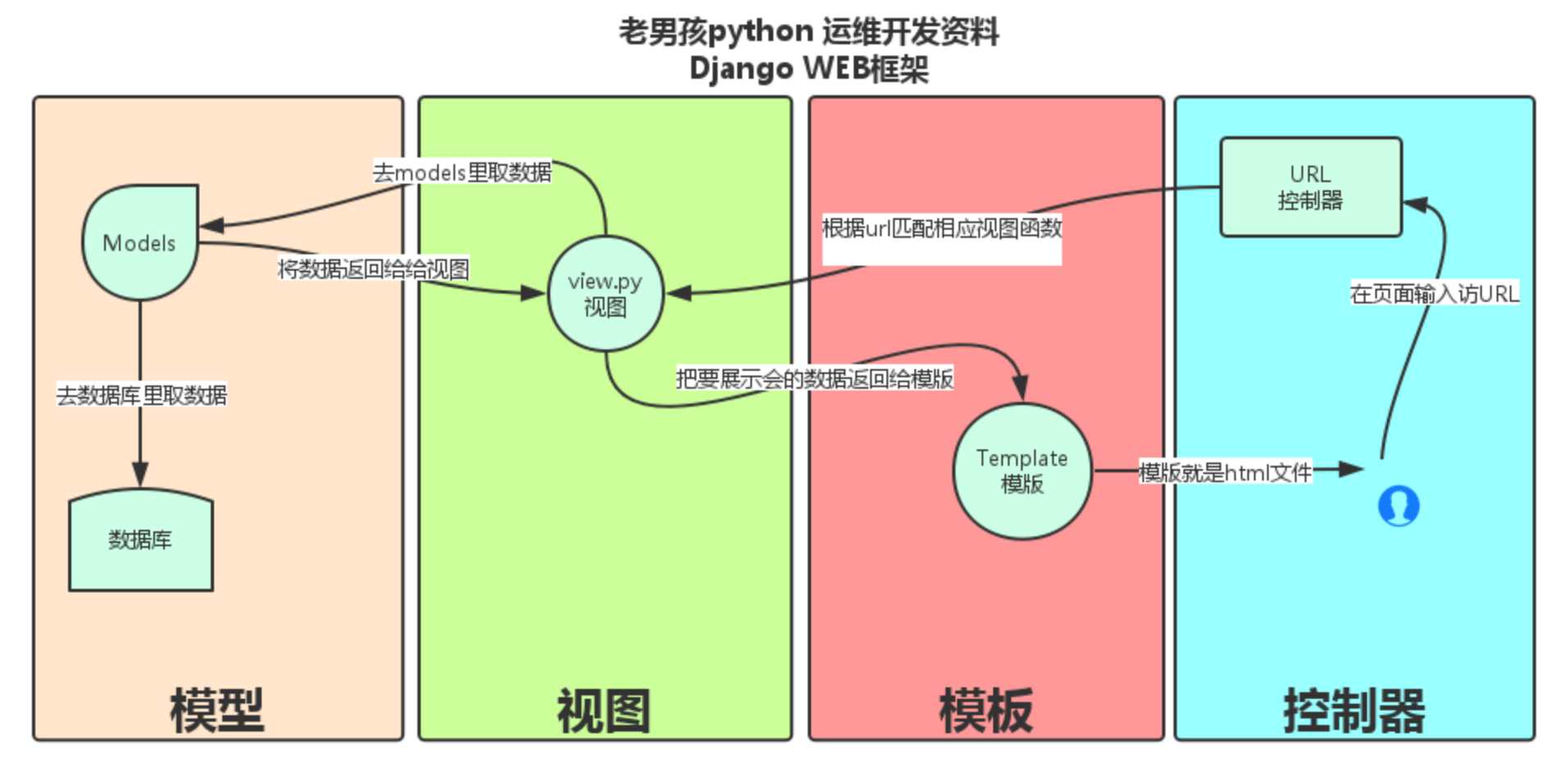
3 简述MVC和MTV。
著名的MVC模式:所谓MVC就是把web应用分为模型(M),控制器(C),视图(V)三层;他们之间以一种插件似的,松耦合的方式连接在一起。
模型负责业务对象与数据库的对象(ORM),视图负责与用户的交互(页面),控制器(C)接受用户的输入调用模型和视图完成用户的请求。

Django的MTV分别代表:
Model(模型):负责业务对象与数据库的对象(ORM)
Template(模版):负责如何把页面展示给用户
View(视图):负责业务逻辑,并在适当的时候调用Model和Template
此外,Django还有一个url分发器,它的作用是将一个个URL的页面请求分发给不同的view处理,view再调用相应的Model和Template
4 谈谈你对restfull 规范的认识?
a.域名:
将api放在主域名下:http://www.example.com/api
b.版本
将api的版本号放在url中
c.路径
路径表示API的具体网址。每个网址代表一种资源。资源作为网址,网址中不能有动词只能有名词,一般名词要与数据库的表名对应。而且名词要使用复数
http://www.example.com/app/goods/1 #获取单个商品
http://www.example.com/app/goods #获取所有商品
d.使用标准的HTTP方法
对于资源的具体操作类型,由HTTP动词表示
GET SELECT :从服务器获取资源
POST CREATE: 从服务器新建资源
PUT UPDATE: 在服务器更新资源
DELETE DELETE:从服务器删除资源
e:过滤信息
如果资源数据过多,服务器不能将所有数据一次全部返回给客户端。API应该提供参数,过滤返回结果。例
#指定返回数据的数量
http://www.example.com/app/goods?limit=10
#指定返回数据的开始位置
http://www.example.com/app/goods?offset=10
#指定第几页,以及每页数据的数量
http://www.example.com/app/goods?page=2&per_page=20
f 错误信息
一般来说,服务器返回的错误信息,以键值对的形式返回。
{error:'Invaid API KEY'}
g.响应结果:
针对不同结果,服务器向客户端返回的结果应该复合物以下规范
#返回商品列表
GET http://www.example.com/app/goods
#返回单个商品
GET http://www.example.com/app/goods/cup
#返回新生成的商品
POST http://www.example.com/app/goods
#返回一个空文档
DELETE http://www.example.com/app/goods
5 Flask框架的优势?
微框架,灵活
6 Flask框架依赖组件?
Werkzeug 以及Jinja2
Flask-SQLalchemy:操作数据库;
Flask-migrate:管理迁移数据库;
Flask-WTF 表单;
7 Flask蓝图的作用?
用于实现单个应用的视图、模板、静态文件的集合
(拆分模块应用)
一个存储操作路由映射方法的容器,主要用来实现客户端请求和URL相互关联的功能
8 列举使用过的Flask第三方组件?
Flask-SQLalchemy:操作数据库;
Flask-migrate:管理迁移数据库;
Flask-WTF 表单;
Flask-script 脚本;
Flask-session
9 简述Flask上下文管理流程?
https://www.cnblogs.com/chaoqi/p/10508328.html
比较详细 https://www.cnblogs.com/leijiangtao/p/3728979.html
补充参考 https://www.cnblogs.com/gaoshengyue/p/8657550.html
10 Flask中的g的作用?
处理请求时,用于临时存储的对象,每次请求都会重设这个变量。比如我们可以获取一些临时请求的用户信息
11 Flask中上下文管理主要涉及到了那些相关的类?并描述类主要作用?
RequestContext #封装进来的请求(赋值给ctx) AppContext #封装app_ctx LocalStack #将local对象中的数据维护成一个栈(先进后出) Local #保存请求上下文对象和app上下文对象
12 为什么要Flask把Local对象中的的值stack 维护成一个列表?
# 因为通过维护成列表,可以实现一个栈的数据结构,进栈出栈时只取一个数据,巧妙的简化了问题。 # 还有,在多app应用时,可以实现数据隔离;列表里不会加数据,而是会生成一个新的列表 # local是一个字典,字典里key(stack)是唯一标识,value是一个列表
13 Flask中多app应用是怎么完成?
利用蓝图
14 在Flask中实现WebSocket需要什么组件?
https://www.cnblogs.com/wt11/p/9288605.html
15 wtforms组件的作用?
在flask内部并没有提供全面的表单验证,所以当我们不借助第三方插件来处理时候代码会显得混乱,而官方推荐的一个表单验证插件就是wtforms。wtfroms是一个支持多种web框架的form组件,主要用于对用户请求数据的进行验证。
https://www.cnblogs.com/carlous/p/10598108.html
16 Flask框架默认session处理机制?
https://www.cnblogs.com/cwp-bg/p/10084523.html
17 解释Flask框架中的Local对象和threading.local对象的区别?
a. threading.local
作用:为每个线程开辟一块空间进行数据存储。
b. 自定义Local对象
作用:为每个线程(协程)开辟一块空间进行数据存储。
https://www.jianshu.com/p/3f38b777a621
18 Flask中 blinker 是什么?
https://www.cnblogs.com/huchong/p/8254218.html
19 SQLAlchemy中的 session和scoped_session 的区别?
https://www.cnblogs.com/ctztake/p/8277372.html
20 SQLAlchemy如何执行原生SQL?
1、方式一
# 查询 cursor = session.execute('select * from users') result = cursor.fetchall() # 添加 cursor = session.execute('insert into users(name) values(:value)', params={"value": 'abc'}) session.commit() print(cursor.lastrowid)
2、方式二
conn = engine.raw_connection() cursor = conn.cursor() cursor.execute( "select * from t1" ) result = cursor.fetchall() cursor.close() conn.close()
21 ORM的实现原理?
https://blog.csdn.net/qq_41421480/article/details/99407283
# ORM的实现基于以下三点
映射类:描述数据库表结构,
映射文件:指定数据库表和映射类之间的关系
数据库配置文件:指定与数据库连接时需要的连接信息(数据库、登录用户名、密码or连接字符串)
22 DBUtils模块的作用?
# 数据库连接池 使用模式: 1、为每个线程创建一个连接,连接不可控,需要控制线程数 2、创建指定数量的连接在连接池,当线程访问的时候去取,不够了线程排队,直到有人释放(推荐) --------------------------------------------------------------------------- 两种写法: 1、用静态方法装饰器,通过直接执行类的方法来连接使用数据库 2、通过实例化对象,通过对象来调用方法执行语句 https://www.cnblogs.com/ArmoredTitan/p/Flask.html
23 SQLAchemy中如何为表设置引擎和字符编码?
1. 设置引擎编码方式为utf8。
engine = create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/sqldb01?charset=utf8")
2. 设置数据库表编码方式为utf8
class UserType(Base): __tablename__ = 'usertype' id = Column(Integer, primary_key=True) caption = Column(String(50), default='管理员') # 添加配置设置编码 __table_args__ = { 'mysql_charset':'utf8' }
这样生成的SQL语句就自动设置数据表编码为utf8了,__table_args__还可设置存储引擎、外键约束等等信息。
24 SQLAchemy中如何设置联合唯一索引?
model如下:
class UserPost(db.Model): id = db.Column(db.Integer, primary_key=True) user_id = db.Column(db.Integer) post_id = db.Column(db.Integer) insert_time = db.Column(db.DateTime) __table_args__ = ( db.UniqueConstraint('user_id', 'post_id', name='uix_user_post_user_id_post_id'), db.Index('ix_user_post_user_id_insert_time', 'user_id', 'insert_time'), )
生成的sql如下:
2016-05-31 19:33:35,625 INFO sqlalchemy.engine.base.Engine CREATE TABLE user_post ( id INTEGER NOT NULL AUTO_INCREMENT, user_id INTEGER, post_id INTEGER, insert_time DATETIME, PRIMARY KEY (id), CONSTRAINT uix_user_post_user_id_post_id UNIQUE (user_id, post_id) ) 2016-05-31 19:33:35,625 INFO sqlalchemy.engine.base.Engine {} 2016-05-31 19:33:35,689 INFO sqlalchemy.engine.base.Engine COMMIT 2016-05-31 19:33:35,692 INFO sqlalchemy.engine.base.Engine CREATE INDEX ix_user_post_user_id_insert_time ON user_post (user_id, insert_time) 2016-05-31 19:33:35,692 INFO sqlalchemy.engine.base.Engine {} 2016-05-31 19:33:35,840 INFO sqlalchemy.engine.base.Engine COMMIT
25 简述Tornado框架的特点。
性能优越,异步非阻塞
26 简述Tornado框架中Future对象的作用?
# 实现异步非阻塞
视图函数yield一个future对象,future对象默认:
self._done = False ,请求未完成
self._result = None ,请求完成后返回值,用于传递给回调函数使用。
tornado就会一直去检测future对象的_done是否已经变成True。
如果IO请求执行完毕,自动会调用future的set_result方法:
self._result = result
self._done = True
参考:http://www.cnblogs.com/wupeiqi/p/6536518.html(自定义异步非阻塞web框架)
27 Tornado框架中如何编写WebSocket程序?
Tornado在websocket模块中提供了一个WebSocketHandler类。 这个类提供了和已连接的客户端通信的WebSocket事件和方法的钩子。 当一个新的WebSocket连接打开时,open方法被调用, 而on_message和on_close方法,分别在连接、接收到新的消息和客户端关闭时被调用。 此外,WebSocketHandler类还提供了write_message方法用于向客户端发送消息,close方法用于关闭连接。
28 Tornado中静态文件是如何处理的? 如: <link href="{{static_url("commons.css")}}" rel="stylesheet" />
# settings.py
settings = {
"static_path": os.path.join(os.path.dirname(__file__), "static"),
# 指定了静态文件的位置在当前目录中的"static"目录下
"cookie_secret": "61oETzKXQAGaYdkL5gEmGeJJFuYh7EQnp2XdTP1o/Vo=",
"login_url": "/login",
"xsrf_cookies": True,
}
经上面配置后
static_url()自动去配置的路径下找'commons.css'文件
29 Tornado操作MySQL使用的模块?
tornado-sqlachemly
30 Tornado操作redis使用的模块?
tornado-redis
31 简述Tornado框架的适用场景?
用户量大,高并发
大量的HTTP持久链接
32 git常见命令作用:
git init //初始化本地git环境 git clone XXX //克隆一份代码到本地仓库 git pull //把远程库的代码更新到工作台 git pull --rebase origin master //强制把远程库的代码跟新到当前分支上面 git fetch //把远程库的代码更新到本地库 git add . //把本地的修改加到stage中 git commit -m 'comments here' //把stage中的修改提交到本地库 git push //把本地库的修改提交到远程库中 git branch -r/-a //查看远程分支/全部分支 git checkout master/branch //切换到某个分支 git checkout -b test //新建test分支 git checkout -d test //删除test分支 git merge master //假设当前在test分支上面,把master分支上的修改同步到test分支上 git merge tool //调用merge工具 git stash //把未完成的修改缓存到栈容器中 git stash list //查看所有的缓存 git stash pop //恢复本地分支到缓存状态 git blame someFile //查看某个文件的每一行的修改记录()谁在什么时候修改的) git status //查看当前分支有哪些修改 git log //查看当前分支上面的日志信息 git diff //查看当前没有add的内容 git diff --cache //查看已经add但是没有commit的内容 git diff HEAD //上面两个内容的合并 git reset --hard HEAD //撤销本地修改,版本回滚
33 简述以下git中stash命令作用以及相关其他命令。
'git stash':将当前工作区所有修改过的内容存储到“某个地方”,将工作区还原到当前版本未修改过的状态 'git stash list':查看“某个地方”存储的所有记录 'git stash clear':清空“某个地方” 'git stash pop':将第一个记录从“某个地方”重新拿到工作区(可能有冲突) 'git stash apply':编号, 将指定编号记录从“某个地方”重新拿到工作区(可能有冲突) 'git stash drop':编号,删除指定编号的记录
34 git 中 merge 和 rebase命令 的区别。
merge:
会将不同分支的提交合并成一个新的节点,之前的提交分开显示,
注重历史信息、可以看出每个分支信息,基于时间点,遇到冲突,手动解决,再次提交
rebase:
将两个分支的提交结果融合成线性,不会产生新的节点;
注重开发过程,遇到冲突,手动解决,继续操作
35 公司如何基于git做的协同开发?
1、你们公司的代码review分支怎么做?谁来做? 答:组长创建review分支,我们小功能开发完之后,合并到review分支交给老大(小组长)来看。 1.1、你组长不开发代码吗? 他开发代码,但是它只开发核心的东西,任务比较少 或者抽出时间,我们一起做这个事情。 2、你们公司协同开发是怎么协同开发的? 每个人都有自己的分支,阶段性代码完成之后,合并到review,然后交给老大看。 -------------------------------------------------------------------------- # 大致工作流程: 在公司: 下载代码 git clone https://gitee.com/wupeiqi/xianglong.git 或创建目录 cd 目录 git init git remote add origin https://gitee.com/wupeiqi/xianglong.git git pull origin maste 创建dev分支 git checkout -b dev git checkout dev git pull origin dev 继续写代码 git add . git commit -m '提交记录' git push origin dev 回到家中: 拉代码: git pull origin dev 继续写: 继续写代码 git add . git commit -m '提交记录' git push origin dev
36 如何基于git实现代码review?
https://blog.csdn.net/june_y/article/details/50817993
37 git如何实现v1.0 、v2.0 等版本的管理?
在命令行中,使用git tag –a tagname –m 'comment'可以快速创建一个标签。 需要注意,命令行创建的标签只存在本地Git库中,还需要使用Git push –tags指令发布到服务器的Git库中。
38 什么是gitlab?
gitlab是公司自己搭建的项目代码托管平台。
39 github和gitlab的区别?
1、gitHub是一个面向开源及私有软件项目的托管平台(创建私有的话,需要购买,最低级的付费为每月7刀,支持5个私有项目)
2、gitlab是公司自己搭建的项目托管平台
40 如何为github上牛逼的开源项目贡献代码?
1、fork需要协作项目 2、克隆/关联fork的项目到本地 3、新建分支(branch)并检出(checkout)新分支 4、在新分支上完成代码开发 5、开发完成后将你的代码合并到master分支 6、添加原作者的仓库地址作为一个新的仓库地址 7、合并原作者的master分支到你自己的master分支,用于和作者仓库代码同步 8、push你的本地仓库到GitHub 9、在Github上提交 pull requests 10、等待管理员(你需要贡献的开源项目管理员)处理
41 git中 .gitignore文件的作用?
一般来说每个Git项目中都需要一个“.gitignore”文件,
这个文件的作用就是告诉Git哪些文件不需要添加到版本管理中。
实际项目中,很多文件都是不需要版本管理的,比如Python的.pyc文件和一些包含密码的配置文件等等。
42 什么是敏捷开发?
'敏捷开发':是一种以人为核心、迭代、循序渐进的开发方式。 它并不是一门技术,而是一种开发方式,也就是一种软件开发的流程。 它会指导我们用规定的环节去一步一步完成项目的开发。 因为它采用的是迭代式开发,所以这种开发方式的主要驱动核心是人
43 简述 jenkins 工具的作用?
'Jenkins'是一个可扩展的持续集成引擎。 主要用于: 持续、自动地构建/测试软件项目。 监控一些定时执行的任务。
44 公司如何实现代码发布?
45 简述 RabbitMQ、Kafka、ZeroMQ的区别?
https://blog.csdn.net/zhailihua/article/details/7899006
46 RabbitMQ如何在消费者获取任务后未处理完前就挂掉时,保证数据不丢失?
47 RabbitMQ如何对消息做持久化?
https://www.cnblogs.com/xiangjun555/articles/7874006.html
48 RabbitMQ如何控制消息被消费的顺序?
https://blog.csdn.net/varyall/article/details/79111745
49 以下RabbitMQ的exchange type分别代表什么意思?如:fanout、direct、topic。
https://www.cnblogs.com/shenyixin/p/9084249.html
50 简述 celery 是什么以及应用场景?
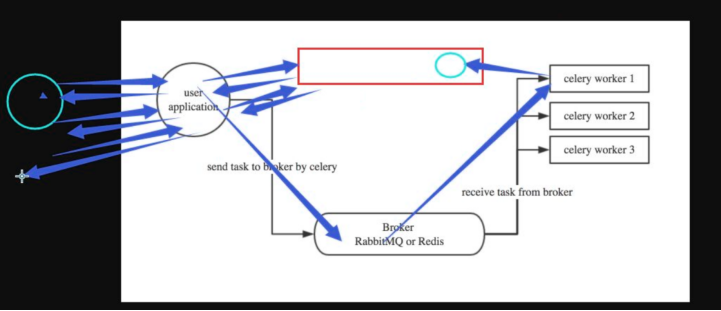
# Celery是由Python开发的一个简单、灵活、可靠的处理大量任务的分发系统, # 它不仅支持实时处理也支持任务调度。 # http://www.cnblogs.com/wupeiqi/articles/8796552.html
51 简述celery运行机制。
52 celery如何实现定时任务?
# celery实现定时任务 启用Celery的定时任务需要设置CELERYBEAT_SCHEDULE 。 CELERYBEAT_SCHEDULE='djcelery.schedulers.DatabaseScheduler'#定时任务 '创建定时任务' # 通过配置CELERYBEAT_SCHEDULE: #每30秒调用task.add from datetime import timedelta CELERYBEAT_SCHEDULE = { 'add-every-30-seconds': { 'task': 'tasks.add', 'schedule': timedelta(seconds=30), 'args': (16, 16) }, }
53 简述 celery多任务结构目录?
pro_cel ├── celery_tasks # celery相关文件夹 │ ├── celery.py # celery连接和配置相关文件 │ └── tasks.py # 所有任务函数 ├── check_result.py # 检查结果 └── send_task.py # 触发任务
54 celery中装饰器 @app.task 和 @shared_task的区别?
# 一般情况使用的是从celeryapp中引入的app作为的装饰器:@app.task # django那种在app中定义的task则需要使用@shared_task
55 简述 requests模块的作用及基本使用?
# 作用: 使用requests可以模拟浏览器的请求 # 常用参数: url、headers、cookies、data json、params、proxy # 常用返回值: content iter_content text encoding="utf-8" cookie.get_dict()
56 简述 beautifulsoup模块的作用及基本使用?
简述 seleninu模块的作用及基本使用?
Selenium是一个用于Web应用程序测试的工具,
他的测试直接运行在浏览器上,模拟真实用户,按照代码做出点击、输入、打开等操作
爬虫中使用他是为了解决requests无法解决javascript动态问题
57 scrapy框架中各组件的工作流程?
Scrapy 使用了 Twisted 异步非阻塞网络库来处理网络通讯,整体架构大致如下(绿线是数据流向):
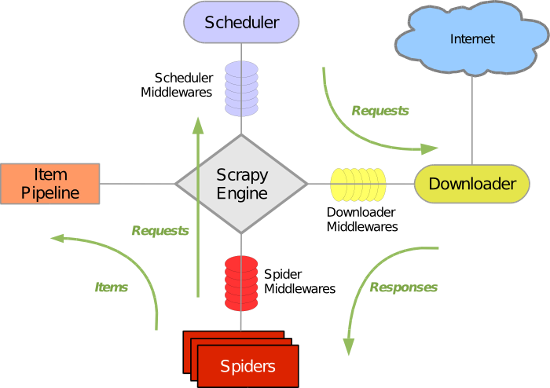
Scrapy主要包括了以下组件:
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
- 下载器中间件(Downloader Middlewares)
介于Scrapy引擎和下载器之间的中间件,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的中间件,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
1.引擎:Hi!Spider, 你要处理哪一个网站? 2.Spider:老大要我处理xxxx.com(初始URL)。 3.引擎:你把第一个需要处理的URL给我吧。 4.Spider:给你,第一个URL是xxxxxxx.com。 5.引擎:Hi!调度器,我这有request请求你帮我排序入队一下。 6.调度器:好的,正在处理你等一下。 7.引擎:Hi!调度器,把你处理好的request请求给我。 8.调度器:给你,这是我处理好的request 9.引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个request请求。 10.下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载) 11.引擎:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你自己处理一下(注意!这儿responses默认是交给def parse()这个函数处理的) 12.Spider:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。 13.引擎:Hi !管道 我这儿有个item你帮我处理一下!调度器!这是需要跟进URL你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。 14.管道、调度器:好的,现在就做!
58 在scrapy框架中如何设置代理(两种方法)?
方式一:内置添加代理功能 # -*- coding: utf-8 -*- import os import scrapy from scrapy.http import Request class ChoutiSpider(scrapy.Spider): name = 'chouti' allowed_domains = ['chouti.com'] start_urls = ['https://dig.chouti.com/'] def start_requests(self): os.environ['HTTP_PROXY'] = "http://192.168.11.11" for url in self.start_urls: yield Request(url=url,callback=self.parse) def parse(self, response): print(response) 方式二:自定义下载中间件 import random import base64 import six def to_bytes(text, encoding=None, errors='strict'): """Return the binary representation of `text`. If `text` is already a bytes object, return it as-is.""" if isinstance(text, bytes): return text if not isinstance(text, six.string_types): raise TypeError('to_bytes must receive a unicode, str or bytes ' 'object, got %s' % type(text).__name__) if encoding is None: encoding = 'utf-8' return text.encode(encoding, errors) class MyProxyDownloaderMiddleware(object): def process_request(self, request, spider): proxy_list = [ {'ip_port': '111.11.228.75:80', 'user_pass': 'xxx:123'}, {'ip_port': '120.198.243.22:80', 'user_pass': ''}, {'ip_port': '111.8.60.9:8123', 'user_pass': ''}, {'ip_port': '101.71.27.120:80', 'user_pass': ''}, {'ip_port': '122.96.59.104:80', 'user_pass': ''}, {'ip_port': '122.224.249.122:8088', 'user_pass': ''}, ] proxy = random.choice(proxy_list) if proxy['user_pass'] is not None: request.meta['proxy'] = to_bytes("http://%s" % proxy['ip_port']) encoded_user_pass = base64.encodestring(to_bytes(proxy['user_pass'])) request.headers['Proxy-Authorization'] = to_bytes('Basic ' + encoded_user_pass) else: request.meta['proxy'] = to_bytes("http://%s" % proxy['ip_port']) 配置: DOWNLOADER_MIDDLEWARES = { # 'xiaohan.middlewares.MyProxyDownloaderMiddleware': 543, }
59 scrapy框架中如何实现大文件的下载?
1.引擎:Hi!Spider, 你要处理哪一个网站? 2.Spider:老大要我处理xxxx.com(初始URL)。 3.引擎:你把第一个需要处理的URL给我吧。 4.Spider:给你,第一个URL是xxxxxxx.com。 5.引擎:Hi!调度器,我这有request请求你帮我排序入队一下。 6.调度器:好的,正在处理你等一下。 7.引擎:Hi!调度器,把你处理好的request请求给我。 8.调度器:给你,这是我处理好的request 9.引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个request请求。 10.下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载) 11.引擎:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你自己处理一下(注意!这儿responses默认是交给def parse()这个函数处理的) 12.Spider:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。 13.引擎:Hi !管道 我这儿有个item你帮我处理一下!调度器!这是需要跟进URL你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。 14.管道、调度器:好的,现在就做!
60 scrapy中如何实现限速?
http://scrapy-chs.readthedocs.io/zh_CN/1.0/topics/autothrottle.html
61 scrapy中如何实现暂定爬虫?
# 有些情况下,例如爬取大的站点,我们希望能暂停爬取,之后再恢复运行。 # Scrapy通过如下工具支持这个功能: 一个把调度请求保存在磁盘的调度器 一个把访问请求保存在磁盘的副本过滤器[duplicates filter] 一个能持续保持爬虫状态(键/值对)的扩展 Job 路径 要启用持久化支持,你只需要通过 JOBDIR 设置 job directory 选项。 这个路径将会存储所有的请求数据来保持一个单独任务的状态(例如:一次spider爬取(a spider run))。 必须要注意的是,这个目录不允许被不同的spider共享,甚至是同一个spider的不同jobs/runs也不行。 也就是说,这个目录就是存储一个单独 job的状态信息。
62 scrapy中如何进行自定制命令?
在spiders同级创建任意目录,如:commands 在其中创建'crawlall.py'文件(此处文件名就是自定义的命令) from scrapy.commands import ScrapyCommand from scrapy.utils.project import get_project_settings class Command(ScrapyCommand): requires_project = True def syntax(self): return '[options]' def short_desc(self): return 'Runs all of the spiders' def run(self, args, opts): spider_list = self.crawler_process.spiders.list() for name in spider_list: self.crawler_process.crawl(name, **opts.__dict__) self.crawler_process.start() 在'settings.py'中添加配置'COMMANDS_MODULE = '项目名称.目录名称'' 在项目目录执行命令:'scrapy crawlall'
63 scrapy中如何实现的记录爬虫的深度?
'DepthMiddleware'是一个用于追踪每个Request在被爬取的网站的深度的中间件。 其可以用来限制爬取深度的最大深度或类似的事情。 'DepthMiddleware'可以通过下列设置进行配置(更多内容请参考设置文档): 'DEPTH_LIMIT':爬取所允许的最大深度,如果为0,则没有限制。 'DEPTH_STATS':是否收集爬取状态。 'DEPTH_PRIORITY':是否根据其深度对requet安排优先
64 scrapy中的pipelines工作原理?
Scrapy 提供了 pipeline 模块来执行保存数据的操作。
在创建的 Scrapy 项目中自动创建了一个 pipeline.py 文件,同时创建了一个默认的 Pipeline 类。
我们可以根据需要自定义 Pipeline 类,然后在 settings.py 文件中进行配置即可
65 scrapy的pipelines如何丢弃一个item对象?
通过raise DropItem()方法
66 简述scrapy中爬虫中间件和下载中间件的作用?
http://www.cnblogs.com/wupeiqi/articles/6229292.html
68 scrapy-redis组件的作用?
实现了分布式爬虫,url去重、调度器、数据持久化 'scheduler'调度器 'dupefilter'URL去重规则(被调度器使用) 'pipeline'数据持久化
69 scrapy-redis组件中如何实现的任务的去重?
a. 内部进行配置,连接Redis b.去重规则通过redis的集合完成,集合的Key为: key = defaults.DUPEFILTER_KEY % {'timestamp': int(time.time())} 默认配置: DUPEFILTER_KEY = 'dupefilter:%(timestamp)s' c.去重规则中将url转换成唯一标示,然后在redis中检查是否已经在集合中存在 from scrapy.utils import request from scrapy.http import Request req = Request(url='http://www.cnblogs.com/wupeiqi.html') result = request.request_fingerprint(req) print(result) # 8ea4fd67887449313ccc12e5b6b92510cc53675c
scrapy和scrapy-redis的去重规则(源码) 1. scrapy中去重规则是如何实现? class RFPDupeFilter(BaseDupeFilter): """Request Fingerprint duplicates filter""" def __init__(self, path=None, debug=False): self.fingerprints = set() @classmethod def from_settings(cls, settings): debug = settings.getbool('DUPEFILTER_DEBUG') return cls(job_dir(settings), debug) def request_seen(self, request): # 将request对象转换成唯一标识。 fp = self.request_fingerprint(request) # 判断在集合中是否存在,如果存在则返回True,表示已经访问过。 if fp in self.fingerprints: return True # 之前未访问过,将url添加到访问记录中。 self.fingerprints.add(fp) def request_fingerprint(self, request): return request_fingerprint(request) 2. scrapy-redis中去重规则是如何实现? class RFPDupeFilter(BaseDupeFilter): """Redis-based request duplicates filter. This class can also be used with default Scrapy's scheduler. """ logger = logger def __init__(self, server, key, debug=False): # self.server = redis连接 self.server = server # self.key = dupefilter:123912873234 self.key = key @classmethod def from_settings(cls, settings): # 读取配置,连接redis server = get_redis_from_settings(settings) # key = dupefilter:123912873234 key = defaults.DUPEFILTER_KEY % {'timestamp': int(time.time())} debug = settings.getbool('DUPEFILTER_DEBUG') return cls(server, key=key, debug=debug) @classmethod def from_crawler(cls, crawler): return cls.from_settings(crawler.settings) def request_seen(self, request): fp = self.request_fingerprint(request) # This returns the number of values added, zero if already exists. # self.server=redis连接 # 添加到redis集合中:1,添加工程;0,已经存在 added = self.server.sadd(self.key, fp) return added == 0 def request_fingerprint(self, request): return request_fingerprint(request) def close(self, reason=''): self.clear() def clear(self): """Clears fingerprints data.""" self.server.delete(self.key)
70 scrapy-redis的调度器如何实现任务的深度优先和广度优先?
71 简述 vitualenv 及应用场景?
'vitualenv'是一个独立的python虚拟环境。 如: 当前项目依赖的是一个版本,但是另一个项目依赖的是另一个版本,这样就会造成依赖冲突, 而virtualenv就是解决这种情况的,virtualenv通过创建一个虚拟化的python运行环境, 将我们所需的依赖安装进去的,不同项目之间相互不干扰。
72 简述 pipreqs 及应用场景?
可以通过对项目目录扫描,自动发现使用了那些类库,并且自动生成依赖清单。
pipreqs ./ 生成requirements.txt
81 在Python中使用过什么代码检查工具?
1)PyFlakes:静态检查Python代码逻辑错误的工具。 2)Pep8: 静态检查PEP8编码风格的工具。 3)NedBatchelder’s McCabe script:静态分析Python代码复杂度的工具。 Python代码分析工具:PyChecker、Pylint
73 简述 saltstack、ansible、fabric、puppet工具的作用?
74 uwsgi和wsgi的区别?
wsgi是一种通用的接口标准或者接口协议,实现了python web程序与服务器之间交互的通用性。 uwsgi:同WSGI一样是一种通信协议 uwsgi协议是一个'uWSGI服务器'自有的协议,它用于定义传输信息的类型, 'uWSGI'是实现了uwsgi和WSGI两种协议的Web服务器,负责响应python的web请求。
75 supervisor的作用?
# Supervisor: 是一款基于Python的进程管理工具,可以很方便的管理服务器上部署的应用程序。 是C/S模型的程序,其服务端是supervisord服务,客户端是supervisorctl命令 # 主要功能: 启动、重启、关闭包括但不限于python进程。 查看进程的运行状态。 批量维护多个进程。
76 解释 PV、UV 的含义?
PV访问量(Page View),即页面访问量,每打开一次页面PV计数+1,刷新页面也是。
UV访客量(Unique Visitor)指独立访客访问数,一台电脑终端为一个访客。
80 列举熟悉的的Linux命令。