微服务架构有一条重要规则:每个微服务必须拥有领域逻辑和数据。与完整的应用有逻辑和数据类似,
在自治的生命周期内,微服务也有自己的逻辑和数据,并可针对每个微服务独立部署。
这意味着子系统和微服务的领域概念模型会有差别。假设有个企业应用,例如客户关系管理(CRM)
系统,交易记录子系统和客户支持子系统都会调用客户实体的属性和数据,而它们是隶属于不同上下文
边界的。
这样的原则在领域驱动设计(DDD)里也是相似的,每个限界上下文、自治的子系统或服务必须拥有
自己的领域模型(数据 + 逻辑 + 行为)。每一个 DDD 限界上下文关联到一个业务的微服务(一个或
多个服务)。(下一节会进一步详细介绍限界上下文的设计。)
另一方面,很多应用程序中使用的传统设计方法(单体式数据)会使用单一的中心化数据库,或有限的
几个数据库。通常此时会为整个应用和所有内部子系统中使用符合范式的 SQL 数据库,如图所
示。
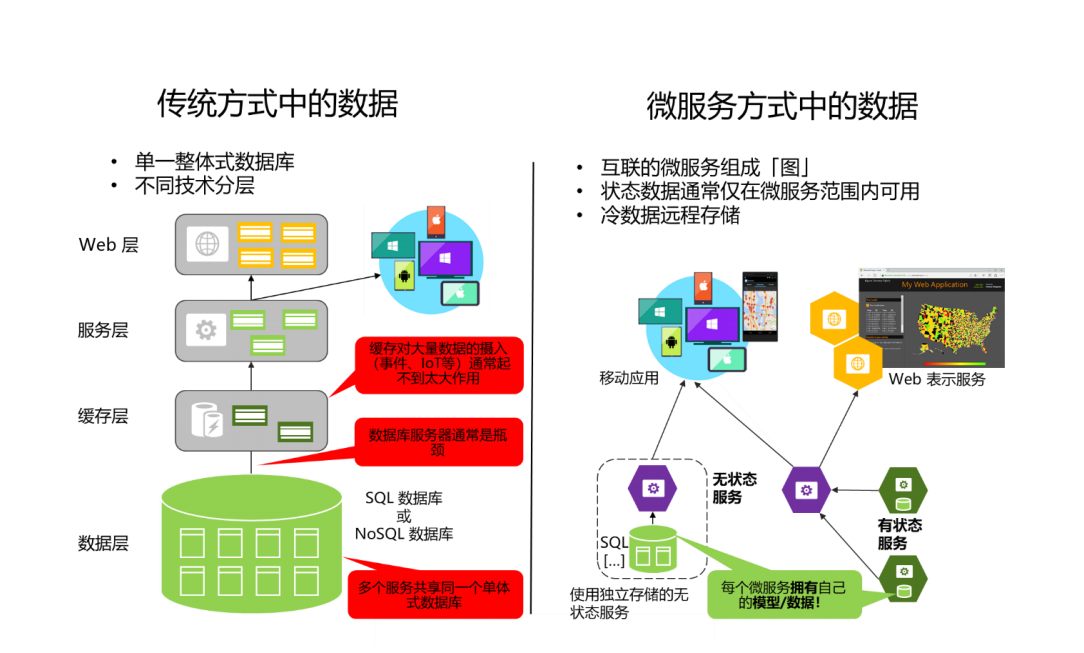
这种中心化数据库的方式初看起来比较简单,好像能够在不同子系统间复用实体,以确保所有内容保持
一致。但现实情况是,为了满足多个不同子系统需求,要建立非常大的表,其中包含大部分情况下都不
需要的属性和字段。这就像使用同一张地形图来满足徒步旅行、长途汽车旅行和学习地理知识的需求。
具有单一关系型数据库的单体式应用有两个重要优点:在应用程序的所有数据库表和数据层面,都支持
ACID 事务和 SQL 语言。这种方式能简单地写出关联多张表组合数据的查询语句。
然而,微服务架构的数据访问会变得更加复杂。即使在一个微服务或限界上下文里能够或者应该做到
ACID 事务一致,但每个微服务的数据是独立的,所以只能通过微服务的 API 来访问。将数据进行封装
确保了微服务是松耦合且能独立变化的。如果多个服务访问相同数据,数据的更新就要求协调同步到所
有服务,这会破坏微服务生命周期的自治性。这就表示,当业务流程跨越多个微服务时,最终一致性是
唯一的办法。这比写一个简单的 SQL 连接要复杂得多。同理,很多其他关系型数据库功能也不支持跨
微服务使用。
此外,不同微服务通常使用不同种类的数据库。对于现代的应用存储和不同类型数据的处理来说,关系
型数据库也不总是最佳选择。一些场景下,NoSQL 数据库(如 MongoDB)比
SQL 数据库(如 SQL Server )有着更方便的数据模型和更好的性能与扩展性。
但在其他方面,关系型数据库仍然是最佳方式。因此,基于微服务的应用通常会混合使用 SQL 和
NoSQL 数据库,这种做法有时会被称为混合数据持久化(Polyglot Persistence)。
这种隔离的混合数据持久化架构有很多优点,包括服务的松散耦合,更好的性能、扩展性,更低成本和
可管理性等。然而也带来了一些分布式数据管理的挑战
虽然微服务应该尽可能地趋向于小型化,但识别每个微服务的模型边界不是为了尽可能拆成细粒度,而
是根据领域知识来进行最有意义的划分。重点不在于大小,而在于业务需要。另外,如果因为存在庞大
复杂的依赖关系而要求应用的某个领域有清晰一致的需求,这也就表明该领域应该是一个独立的微服
务。“一致”这个特点是用来识别如何拆分或组合微服务的方法之一。本质上,当我们对相关领域的了
解越深入,就应该越能够适配微服务的大小。找到正确的大小,这个目标无法一蹴而就。
BC 界定了领域模型的适用性,借
此开发团队成员可以清晰地理解哪些内容必须结合,哪些可以独立开发,并共享知识。微服务的目标正
是如此。