一、Scala概述
scala是一门多范式编程语言,集成了面向对象编程和函数式编程等多种特性。
scala运行在虚拟机上,并兼容现有的Java程序。
Scala源代码被编译成java字节码,所以运行在JVM上,并可以调用现有的Java类库。
二、第一个Scala程序
Scala语句末尾的分号可写可不写
HelloSpark.scala
object HelloSpark{ def main(args:Array[String]):Unit = { println("Hello Spark!") } }
运行过程需要先进行编译
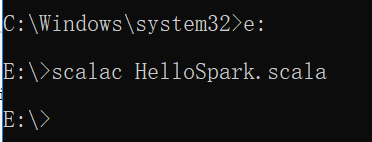
编译之后生成2个文件

运行HelloSpark.class
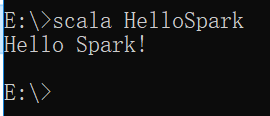
输出结果Hello Spark
三、Scala的基本语法
1、概述
/** * Scala基本语法: * 区分大小写 * 类名首字母大写(MyFirstScalaClass) * 方法名称第一个字母小写(myMethodName()) * 程序文件名应该与对象名称完全匹配 * def main(args:Array[String]):scala程序从main方法开始处理,程序的入口。 * * Scala注释:分为多行/**/和单行// * * 换行符:Scala是面向行的语言,语句可以用分号(;)结束或换行符(println()) * * 定义包有两种方法: * 1、package com.ahu * class HelloScala * 2、package com.ahu{ * class HelloScala * } * * 引用:import java.awt.Color * 如果想要引入包中的几个成员,可以用selector(选取器): * import java.awt.{Color,Font} * // 重命名成员 * import java.util.{HashMap => JavaHashMap} * // 隐藏成员 默认情况下,Scala 总会引入 java.lang._ 、 scala._ 和 Predef._,所以在使用时都是省去scala.的 * import java.util.{HashMap => _, _} //引入了util包所有成员,但HashMap被隐藏了 */
2、Scala的数据类型
Scala 与 Java有着相同的数据类型,下表列出了 Scala 支持的数据类型:
| 数据类型 | 描述 |
|---|---|
| Byte | 8位有符号补码整数。数值区间为 -128 到 127 |
| Short | 16位有符号补码整数。数值区间为 -32768 到 32767 |
| Int | 32位有符号补码整数。数值区间为 -2147483648 到 2147483647 |
| Long | 64位有符号补码整数。数值区间为 -9223372036854775808 到 9223372036854775807 |
| Float | 32位IEEE754单精度浮点数 |
| Double | 64位IEEE754单精度浮点数 |
| Char | 16位无符号Unicode字符, 区间值为 U+0000 到 U+FFFF |
| String | 字符序列 |
| Boolean | true或false |
| Unit | 表示无值,和其他语言中void等同。用作不返回任何结果的方法的结果类型。Unit只有一个实例值,写成()。 |
| Null | null 或空引用 |
| Nothing | Nothing类型在Scala的类层级的最低端;它是任何其他类型的子类型。 |
| Any | Any是所有其他类的超类 |
| AnyRef | AnyRef类是Scala里所有引用类(reference class)的基类 |
Scala多行字符串的表示方式
var str = """ |第一行 |第二行 |第三行 """.stripMargin println(str)
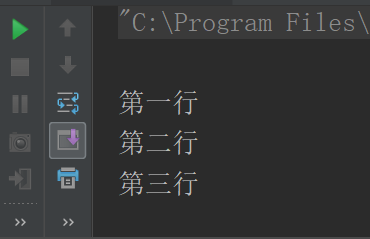
3、Scala的变量
object VariableTest { def main(args: Array[String]) { //使用val定义的变量值是不可变的,相当于java里用final修饰的变量 val i = 1 //使用var定义的变量是可变的,在Scala中鼓励使用val var s = "hello" //Scala编译器会自动推断变量的类型,必要的时候可以指定类型 //变量名在前,类型在后 val str: String = "world" } }
总结:
1)数据类型可以指定,也可以不指定,如果不指定,那么就会进行数据类型的推断。
2)如果指定数据类型,数据类型的执行 方式是 在变量名后面写一个冒号,然后写上数据类型。
3)我们的scala里面变量的修饰符一共有两个,一个是var 一个是val,如果是var修饰的变量,那么这个变量的值是可以修改的。如果是val修饰的变量,那么这个变量的值是不可以修改的。
4、Scala访问修饰符
Scala访问修饰符和Java基本一样,分别有private、protected、public。
默认情况下,Scala对象的访问级别是public。
(1)私有成员
用private关键字修饰的成员仅在包含了成员定义的类或对象内部可见。
class Outer { class Inner{ def start() = println("start") def end() = println("end") private def pause() = println("pause") } new Inner().start() new Inner().end() new Inner().pause() }
在上面的代码里start和end两个方法被定义为public类型,可以通过任意Inner实例访问;pause被显示定义为private,这样就不能在Inner类外部访问它。执行这段代码,就会如注释处声明的一样,会在该处报错:

(2)protected
和私有成员类似,Scala的访问控制比Java来说也是稍显严格些。在 Scala中,由protected定义的成员只能由定义该成员和其派生类型访问。而在 Java中,由protected定义的成员可以由同一个包中的其它类型访问。在Scala中,可以通过其它方式来实现这种功能。
package p { class Super { protected def f(){println("f")} } class Sub extends Super { f() //OK } class Other { (new Super).f() //Error:f不可访问 } }
(3)public
public访问控制为Scala定义的缺省方式,所有没有使用private和 protected修饰的成员(定义的类和方法)都是“公开的”,这样的成员可以在任何地方被访问。Scala不需要使用public来指定“公开访问”修饰符。
注意:Scala中定义的类和方法默认都是public的,但在类中声明的属性默认是private的。
(4)作用保护域
作用域保护:Scala中,访问修饰符可以通过使用限定词强调。
private[x] 或者 protected[x]
private[x]:这个成员除了对[...]中的类或[...]中的包中的类及他们的伴生对象可见外,对其他的类都是private。
package bobsrockets { package navigation { //如果为private class Navigator,则类Navigator只会对当前包navigation中所有类型可见。 //即private默认省略了[X],X为当前包或者当前类或者当前单例对象。 //private[bobsrockets]则表示将类Navigator从当前包扩展到对bobsrockets包中的所有类型可见。 private[bobsrockets] class Navigator { protected[navigation] def useStarChart() {} class LegOfJourney { private[Navigator] val distance = 100 } private[this] var speed = 200 } } package launch { import navigation._ object Vehicle { //private val guide:表示guide默认被当前单例对象可见。 //private[launch] val guide:表示guide由默认对当前单例对象可见扩展到对launch包中的所有类型可见。 private[launch] val guide = new Navigator } } }
在这个例子中,类Navigator使用 private[bobsrockets] 来修饰,这表示这个类可以被bobsrockets包中所有类型访问,比如通常情况下 Vehicle无法访问私有类型Navigator,但使用包作用域之后,Vechile 中可以访问Navigator。
5、Scala运算符
与Java一样,不过Scala的运算符实际上是一种方法。
6、条件表达式
Scala的的条件表达式比较简洁,例如:
def main(args: Array[String]): Unit = { val x = 1 //判断x的值,将结果赋给y val y = if (x > 0) 1 else -1 //打印y的值 println("y=" + y) //支持混合类型表达式 val z = if (x > 1) 1 else "error" //打印z的值 println("z=" + z) //如果缺失else,相当于if (x > 2) 1 else () val m = if (x > 2) 1 println("m=" + m) //在scala中每个表达式都有值,scala中有个Unit类,写做(),相当于Java中的void val n = if (x > 2) 1 else () println("n=" + n) //if和else if val k = if (x < 0) 0 else if (x >= 1) 1 else -1 println("k=" + k) }
运行结果
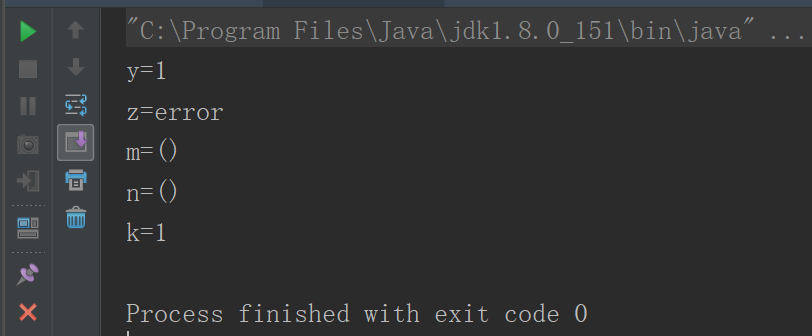
总结:
1)if条件表达式它是有返回值的
2)返回值会根据条件表达式的情况会进行自动的数据类型的推断。
7、块表达式
def main(args: Array[String]): Unit = { val x = 0 val result = { if(x < 0) 1 else if(x >= 1) -1 else "error" } println(result) }
运行结果
8、循环
(1)while循环
def main(args: Array[String]): Unit = { var n = 10 while ( { n > 0 }) { println(n) n -= 1 } }
总结:
1)while使用跟java一模一样
2)注意点:在scala里面不支持 i++ i-- 等操作
统一写成 i-=1
(2)for循环
在scala中有for循环和while循环,用for循环比较多
for循环语法结构:
for (i <- 表达式/数组/集合)
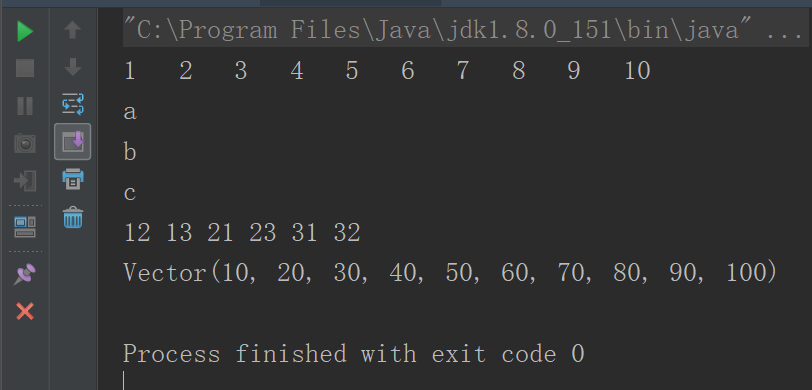
def main(args: Array[String]): Unit = { //for(i <- 表达式),表达式1 to 10返回一个Range(区间) //每次循环将区间中的一个值赋给i for (i <- 1 to 10) print(i+" ") //for(i <- 数组) println() val arr = Array("a", "b", "c") for (i <- arr) println(i) //高级for循环 //每个生成器都可以带一个条件,注意:if前面没有分号 for(i <- 1 to 3; j <- 1 to 3 if i != j) print((10 * i + j) + " ") println() //for推导式:如果for循环的循环体以yield开始,则该循环会构建出一个集合 //每次迭代生成集合中的一个值 val v = for (i <- 1 to 10) yield i * 10 println(v) }
运行结果
总结:
1)在scala里面没有运算符,都有的符号其实都是方法。
2)在scala里面没有++ -- 的用法
3)for( i <- 表达式/数组/集合)
4)在for循环里面我们是可以添加if表达式
5)有两个特殊表达式需要了解:
To 1 to 3 1 2 3
Until 1 until 3 12
6)如果在使用for循环的时候,for循环的时候我们需要获取,我们可以是使用yield关键字。
9、方法和函数
(1)定义方法
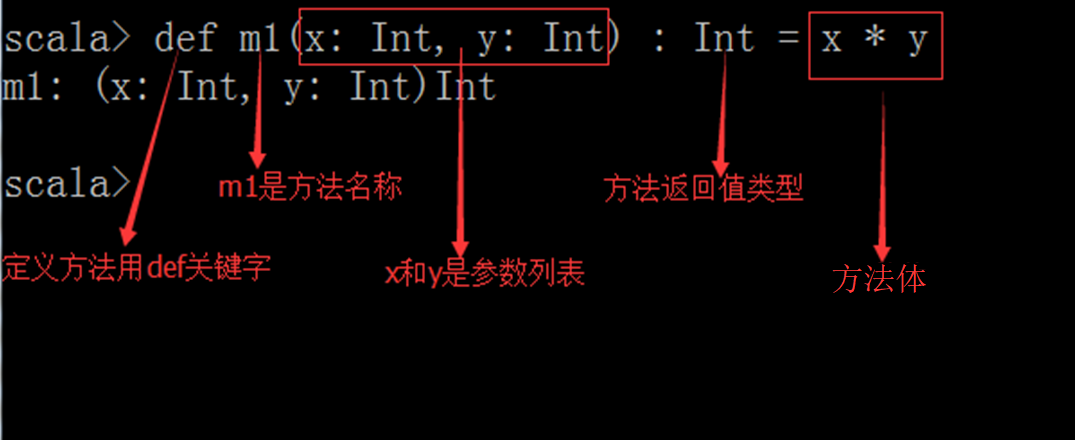
方法的返回值类型可以不写,编译器可以自动推断出来,但是对于递归函数,必须指定返回类型。
如果不写等号,代表没有返回值。
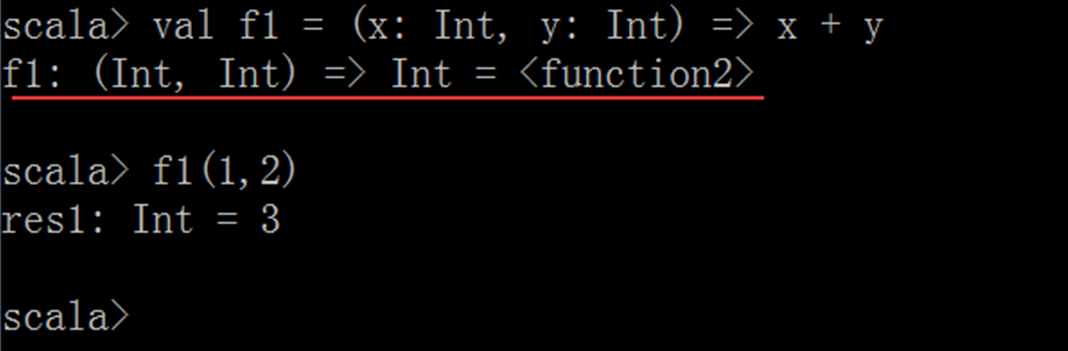
(2)定义函数
(3)方法和函数的区别
在函数式编程语言中,函数是“头等公民”,它可以像任何其他数据类型一样被传递和操作
案例:首先定义一个方法,再定义一个函数,然后将函数传递到方法里面
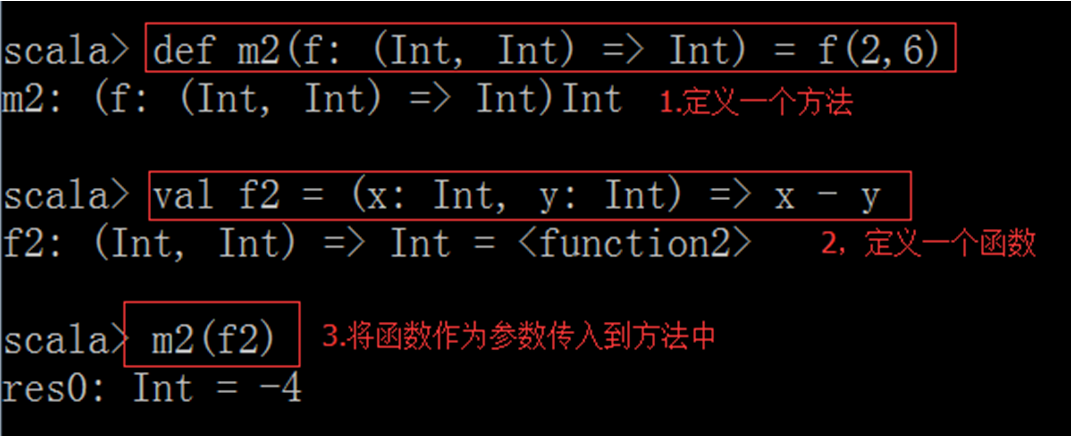
object TestScala { //定义一个方法 //方法m2参数要求是一个函数,函数的参数必须是两个Int类型 //返回值类型也是Int类型 def m1(f:(Int,Int) => Int) : Int = { f(2,6) } //定义一个函数f1,参数是两个Int类型,返回值是一个Int类型 val f1 = (x:Int,y:Int) => x+y //再定义一个函数f2 val f2 = (m:Int,n:Int) => m*n //main方法 def main(args: Array[String]): Unit = { //调用m1方法,并传入f1函数 val r1 = m1(f1) println("r1="+r1) //调用m1方法,并传入f2函数 val r2 = m1(f2) println("r2="+r2) } }
(4)将方法转换成函数
