一.元素的包含提取---------contains()
例:span标签中class包含bookmark-btn
fav_nums = response.xpath("//span[contains(@class, 'bookmark-btn')]/text()").extract()[0]
二.css选择器

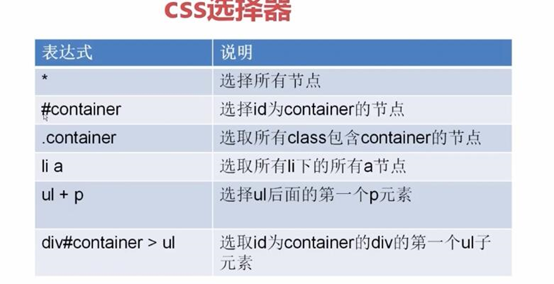

3.css选择器提取标签中的值
1 title = response.css(".entry-header h1::text").extract()[0]
h1标签包含的文字
4.css选择器提取标签中属性的值
1 image_url = post_node.css("img::attr(src)").extract_first("")
二.在你爬取网页的时候,最普遍的事情就是在页面源码中提取需要的数据,我们有几个库可以帮你完成这个任务:
- BeautifulSoup是python中一个非常流行的抓取库,它还能合理的处理错误格式的标签,但是有一个唯一缺点就是:它运行很慢。
- lxml是一个基于ElementTree的XML解析库(同时还能解析HTML),不过lxml并不是Python标准库
而Scrapy实现了自己的数据提取机制,它们被称为选择器,通过XPath或CSS表达式在HTML文档中来选择特定的部分
XPath是一用来在XML中选择节点的语言,同时可以用在HTML上面。CSS是一种HTML文档上面的样式语言。
Scrapy选择器构建在lxml基础之上,所以可以保证速度和准确性。
本章我们来详细讲解下选择器的工作原理,还有它们极其简单和相似的API,比lxml的API少多了,因为lxml可以用于很多其他领域。
完整的API请查看Selector参考
关于选择器
Scrapy帮我们下载完页面后,我们怎样在满是html标签的内容中找到我们所需要的元素呢,这里就需要使用到选择器了,它们是用来定位元素并且提取元素的值。先来举几个例子看看:
- /html/head/title: 选择
<title>节点, 它位于html文档的<head>节点内 - /html/head/title/text(): 选择上面的
<title>节点的内容. - //td: 选择页面中所有的元素
- //div[@class=”mine”]: 选择所有拥有属性
class="mine"的div元素
Scrapy使用css和xpath选择器来定位元素,它有四个基本方法:
- xpath(): 返回选择器列表,每个选择器代表使用xpath语法选择的节点
- css(): 返回选择器列表,每个选择器代表使用css语法选择的节点
- extract(): 返回被选择元素的unicode字符串
- re(): 返回通过正则表达式提取的unicode字符串列表
使用选择器
下面我们通过Scrapy shell演示下选择器的使用,假设我们有如下的一个网页http://doc.scrapy.org/en/latest/_static/selectors-sample1.html,内容如下:
1 <html> 2 <head> 3 <base href='http://example.com/' /> 4 <title>Example website</title> 5 </head> 6 <body> 7 <div id='images'> 8 <a href='image1.html'>Name: My image 1 <br /><img src='image1_thumb.jpg' /></a> 9 <a href='image2.html'>Name: My image 2 <br /><img src='image2_thumb.jpg' /></a> 10 <a href='image3.html'>Name: My image 3 <br /><img src='image3_thumb.jpg' /></a> 11 <a href='image4.html'>Name: My image 4 <br /><img src='image4_thumb.jpg' /></a> 12 <a href='image5.html'>Name: My image 5 <br /><img src='image5_thumb.jpg' /></a> 13 </div> 14 </body> 15 </html>
首先我们打开shell
scrapy shell http://doc.scrapy.org/en/latest/_static/selectors-sample1.html
运行
>>> response.xpath('//title/text()')
[<Selector (text) xpath=//title/text()>]
>>> response.css('title::text')
[<Selector (text) xpath=//title/text()>]
结果可以看出,xpath()和css()方法返回的是SelectorList实例,是一个选择器列表,你可以选择嵌套的数据:
>>> response.css('img').xpath('@src').extract() [u'image1_thumb.jpg', u'image2_thumb.jpg', u'image3_thumb.jpg', u'image4_thumb.jpg', u'image5_thumb.jpg']
必须使用.extract()才能提取最终的数据,如果你只想获得第一个匹配的,可以使用.extract_first()
>>> response.xpath('//div[@id="images"]/a/text()').extract_first() u'Name: My image 1 '
如果没有找到,会返回None,还可选择默认值
>>> response.xpath('//div[@id="not-exists"]/text()').extract_first(default='not-found') 'not-found'
而CSS选择器还可以使用CSS3标准:
>>> response.css('title::text').extract() [u'Example website']
下面是几个比较全面的示例:
1 >>> response.xpath('//base/@href').extract() 2 [u'http://example.com/'] 3 4 >>> response.css('base::attr(href)').extract() 5 [u'http://example.com/'] 6 7 >>> response.xpath('//a[contains(@href, "image")]/@href').extract() 8 [u'image1.html', 9 u'image2.html', 10 u'image3.html', 11 u'image4.html', 12 u'image5.html'] 13 14 >>> response.css('a[href*=image]::attr(href)').extract() 15 [u'image1.html', 16 u'image2.html', 17 u'image3.html', 18 u'image4.html', 19 u'image5.html'] 20 21 >>> response.xpath('//a[contains(@href, "image")]/img/@src').extract() 22 [u'image1_thumb.jpg', 23 u'image2_thumb.jpg', 24 u'image3_thumb.jpg', 25 u'image4_thumb.jpg', 26 u'image5_thumb.jpg'] 27 28 >>> response.css('a[href*=image] img::attr(src)').extract() 29 [u'image1_thumb.jpg', 30 u'image2_thumb.jpg', 31 u'image3_thumb.jpg', 32 u'image4_thumb.jpg', 33 u'image5_thumb.jpg']
嵌套选择器
xpath()和css()返回的是选择器列表,所以你可以继续使用它们的方法。举例来讲:
1 >>> links = response.xpath('//a[contains(@href, "image")]') 2 >>> links.extract() 3 [u'<a href="image1.html">Name: My image 1 <br><img src="image1_thumb.jpg"></a>', 4 u'<a href="image2.html">Name: My image 2 <br><img src="image2_thumb.jpg"></a>', 5 u'<a href="image3.html">Name: My image 3 <br><img src="image3_thumb.jpg"></a>', 6 u'<a href="image4.html">Name: My image 4 <br><img src="image4_thumb.jpg"></a>', 7 u'<a href="image5.html">Name: My image 5 <br><img src="image5_thumb.jpg"></a>'] 8 9 >>> for index, link in enumerate(links): 10 ... args = (index, link.xpath('@href').extract(), link.xpath('img/@src').extract()) 11 ... print 'Link number %d points to url %s and image %s' % args 12 13 Link number 0 points to url [u'image1.html'] and image [u'image1_thumb.jpg'] 14 Link number 1 points to url [u'image2.html'] and image [u'image2_thumb.jpg'] 15 Link number 2 points to url [u'image3.html'] and image [u'image3_thumb.jpg'] 16 Link number 3 points to url [u'image4.html'] and image [u'image4_thumb.jpg'] 17 Link number 4 points to url [u'image5.html'] and image [u'image5_thumb.jpg']
使用正则表达式
Selector有一个re()方法通过正则表达式提取数据,它返回的是unicode字符串列表,你不能再去嵌套使用
1 >>> response.xpath('//a[contains(@href, "image")]/text()').re(r'Name:s*(.*)') 2 [u'My image 1', 3 u'My image 2', 4 u'My image 3', 5 u'My image 4', 6 u'My image 5']
- >>> response.xpath('//a[contains(@href, "image")]/text()').re_first(r'Name:s*(.*)')
- u'My image 1'
XPath相对路径
当你嵌套使用XPath时候,不要使用/开头的,因为这个会相对文档根节点开始算起,需要使用相对路径
1 >>> divs = response.xpath('//div') 2 >>> for p in divs.xpath('.//p'): # extracts all <p> inside 3 ... print p.extract() 4 5 # 或者下面这个直接使用p也可以 6 >>> for p in divs.xpath('p'): 7 ... print p.extract()
使用text作为条件时
避免使用.//text(),直接使用.
1 >>> sel.xpath("//a[contains(., 'Next Page')]").extract() 2 [u'<a href="#">Click here to go to the <strong>Next Page</strong></a>']
//node[1]和(//node)[1]区别
- //node[1]: 选择所有位于第一个子节点位置的node节点
- (//node)[1]: 选择所有的node节点,然后返回结果中的第一个node节点
通过class查找时优先考虑CSS
1 >> from scrapy import Selector 2 >>> sel = Selector(text='<div class="hero shout"><time datetime="2014-07-23 19:00">Special date</time></div>') 3 >>> sel.css('.shout').xpath('./time/@datetime').extract() 4 [u'2014-07-23 19:00']