本文介绍spark2.1.0的源码编译
1.编译环境:
Jdk1.8或以上
Hadoop2.7.3
Scala2.10.4
必要条件:
Maven 3.3.9或以上(重要)
点这里下载
http://mirror.bit.edu.cn/apache/maven/maven-3/3.5.2/binaries/apache-maven-3.5.2-bin.tar.gz
修改/conf/setting.xml
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
2. 下载http://spark.apache.org
2.1Download
![]()
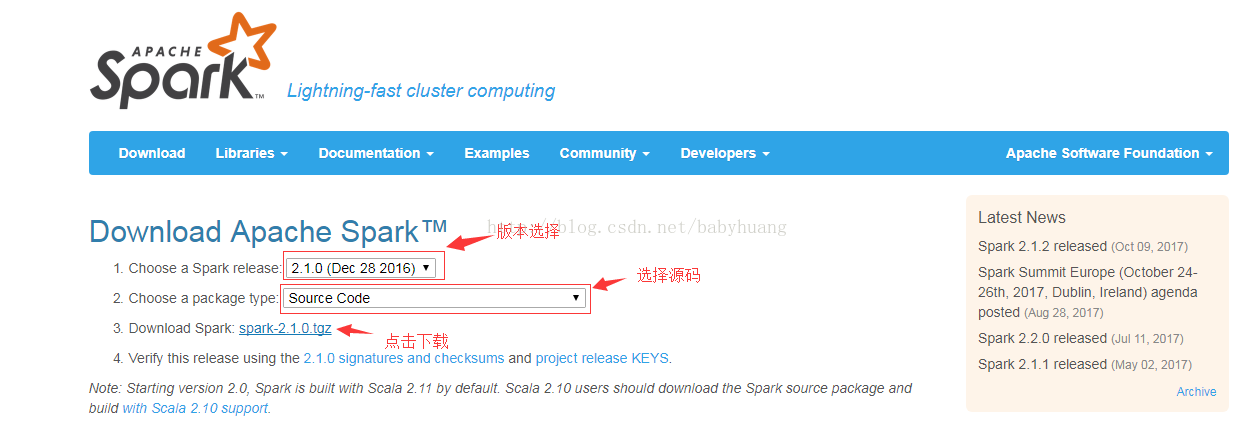
2.2. 解压
tar -zxvf spark-2.1.0.tgz
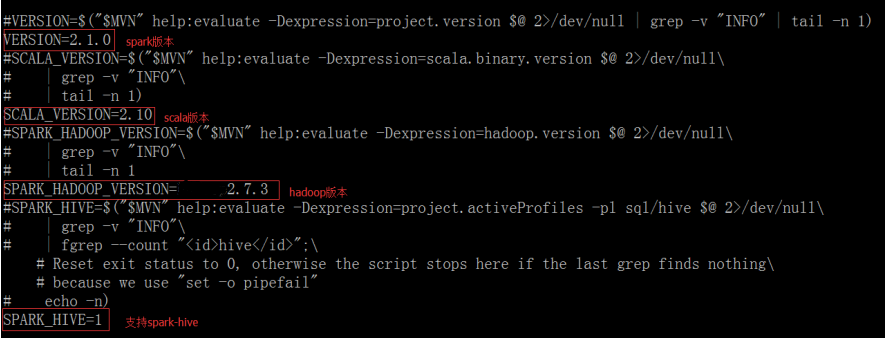
3. 进入主目录,修改编译文件,进行编译
修改spark-2.1.0/dev目录下的make-distribution.sh ,注释掉原来的指定版本,可以节省时间
vi make-distribution.sh
![]()
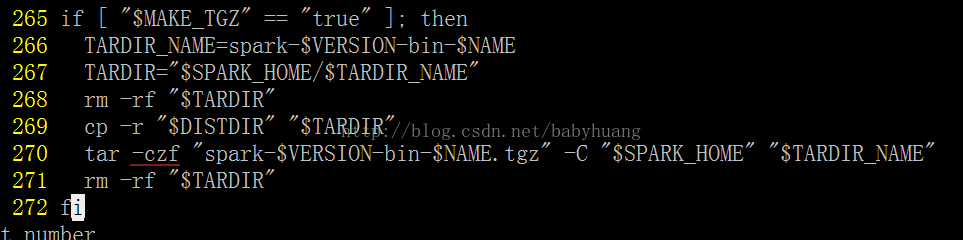
温馨提示:
该文件中如图所示,czf前少个“-”,需要自己修改
注意:
如果你用的hadoop版本是cdh的,那么需要修改spark根目录pom.xml文件,添加cdh的依赖
<repository>
<id>cloudera</id>
<name>cloudera Repository</name>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
添加在<repositorys></repositorys>里
![]()
3.1设置内存
export MAVEN_OPTS="-Xmx2g -XX:ReservedCodeCacheSize=512m"
3.2编译
./dev/make-distribution.sh
--name 2.7.3
--tgz
-Pyarn
-Phadoop-2.7 -Dhadoop.version=2.7.3
-Phive -Phive-thriftserver
-DskipTests clean package
接下来就静静地等待吧,第一次编译时间可能很长,几小时或十几小时,取决于网速,因为要下载很多包
命令解释:
--name 2.7.3 ***指定编译出来的spark名字,name=
--tgz ***压缩成tgz格式
-Pyarn ***支持yarn平台
-Phadoop-2.7 -Dhadoop.version=2.7.3 ***指定hadoop版本为2.7.3
-Phive -Phive-thriftserver ***支持hive
-DskipTests clean package ***跳过测试包
好了,spark的编译到此就结束了
下面分享一下编译遇到的一些问题
错误1:
Failed to execute goal on project spark-launcher_2.11:
Could not resolve dependencies for project org.apache.spark:spark-launcher_2.11:jar:2.1.0:
Failure to find org.apache.hadoop:hadoop-client:jar:hadoop2.7.3 in https://repo1.maven.org/maven2 was cached in the local repository,
resolution will not be reattempted until the update interval of central has elapsed or updates are forced -> [Help 1]
解决:遇该错误,原因可能是编译命令中有参数写错。。。。(希望你没遇到
![]() )
)
错误2:
+ tar czf 'spark-[info] Compile success at Nov 28, 2017 11:27:10 AM [20.248s]-bin-2.7.3.tgz' -C /zhenglh/new-spark-build/spark-2.1.0 'spark-[info] Compile success at Nov 28, 2017 11:27:10 AM [20.248s]-bin-2.7.3'
tar (child): Cannot connect to spark-[info] Compile success at Nov 28, 2017 11: resolve failed
编译的结果没打包:
spark-[info] Compile success at Nov 28, 2017 11:27:10 AM [20.248s]-bin-2.7.3
这个错误可能第一次编译的人都会遇到
解决:见温馨提示
![]()