本章主要是机器学习中关于推荐系统的一些总结的东西
一、SVD
SVD本意是一种数学上的矩阵分解的方法,但在推荐系统中只是借用了这个名字,还有其他各式各样的矩阵分解的方法能运用于推荐系统中,SVD只是其中之一,且和最早的数学上的SVD有一些不太一样。
1.奇异值和特征值的关系:将矩阵Σ的对角元素就称之为奇异值;与特征值一样,这些奇异值标识了数据集中的重要特征。奇异值和特征值的关系为:奇异值是矩阵 Data * DataT 特征值的平方根。
2.loss函数:

3.利用梯度下降法求解上面这个无约束最优化问题:P/Q的更新:

随机梯度和一般的梯度下降法区别在,对P、Q两个矩阵的更新上,是一条记录就立刻更新对应的Puf和Qif,下一条数据来时,用的是更新后的数据了。
4.关于加入偏置,预测打分的公式加了东西,Loss函数多几个正则项:u表示训练集中的所有评分的平均值。bu是用户偏置,代表一个用户评分的平均值。bi是物品偏置,代表一个物品被评分的平均值。所以“偏置”这东西反应的是事物固有的、不受外界影响的属性。

5.关于SVD++,加入了用户的行为记录信息
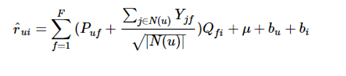
举个例子:程序中是这些矩阵先建立好的,并初始化好,可用随机数或0初始化好,来一条记录(user,item,rate)算一次,通过user,item来找对应的各个矩阵要更新值。细化到代码的层面可以下面这样理解:这只是小型的用来理解SVD的程序,和大型工程上用的要做出区别的。
User数目m Item数目n 隐藏属性f
程序中:
P(m*f)矩阵:每个用户对隐藏属性的权重
Q(n*f)矩阵: 每个项目对隐藏属性的权重
bu(m*1)矩阵:
bi(n*1)矩阵:
Yjf(n*f)矩阵:隐式特征向量矩阵,电影权重矩阵
N(u):一个数,该用户所有评过分的项目的总数,小明看了3部电影,算小明的时候就是3
可以看到,SVD中并没有利用好一个用户评价了哪些电影这种信息,这代表无论评分高低,在看电影之前这些电影对他来说是有吸引力的,更一般的,如果你有用户查看过电影介绍的数据,同样也可以加以利用。
二、关于协同过滤
1.基于Item的协同过滤的优势:
(1)用户的量一般比item大。(2)更好给出推荐的解释.(3)对新用户无缝连接
如果在缺乏用户打分数据的情况下,协同过滤的打分是用熵值法确定的。每个特征的熵值越大,不确定性越高,它最后占的权重就越低,比如一个特征值为(1,1,1,1)每个值都占1/4,这样熵值最大,但因为都一样,没意义,最后的特征权重就最低。
2.关于Svd的一些结论:之所以这里把SVD算协同过滤,因为广义上来说,对user-item矩阵进行各种不同的处理都可以算是协同过滤算法
(1) pureSVD在TopN中表现的比LFM算法好,有个原因是它考虑了所有的打分,而LFM只是考虑了打过分的项目。LFM在预测打分上的表现比TopN上的好
(2)提高隐藏属性F,有利于发掘长尾的项
(3)movielen数据集和netflix数据集 全集:效果pureSVD50>SVD++>pureSVD150
后94%的长尾项目pureSVD150>pureSVD50>SVD++
(4) 且RMSE的好坏和precision的好坏没有线性的关系
(5) 关于参数隐藏特征latent factor的选择:具体的邻域具体调整,大部分20到100之间应该可以满足。具体维度具体分析,没有必然联系,并不是维度增加,结果就变好,而且维度的增加对结果的影响不是很大。
(6)余弦相似度的协同过滤:如果在整体数据集上,和SVD++效果和差不多,但在长尾内容的推荐上,效果差SVD系列蛮多的
3.准确率,召回率等一些评价指标


4.关于相似度(或者说相关性)

皮尔逊和修正余弦区别在分母:修正余弦的分母为: 用户的长度为整个评分项目上的长度, 而Pearson相关相似性则是在 : 用户的长度共同评分项目的基础上的长度。
5.关于推荐系统冷启动解决的一些想法
(1)推热门
(2)从别的网站要数据,比如新浪微博
(3)如果是安卓,拉手机里应用的数据
(4)牺牲一部分用户,给他们随机推荐,会降低他们一些体验度,但是让产生的数据作用于那些活跃度高的用户
(5)互动,主动引导用户说出喜好,之间让他们选标签什么的。
三、关于正则化:
1、越小的参数说明模型越简单,越简单的模型则越不容易产生过拟合现象。为什么越小的参数说明模型越简单?我也不懂,我的理解是:限制了参数很小,实际上就限制了多项式某些分量的影响很小
2、正则化就是对最小化经验误差函数上加约束,这样的约束可以解释为先验知识(正则化参数等价于对参数引入先验分布)。约束有引导作用,在优化误差函数的时候倾向于选择满足约束的梯度减少的方向,使最终的解倾向于符合先验知识(如一般的l-norm先验,表示原问题更可能是比较简单的,这样的优化倾向于产生参数值量级小的解,一般对应于稀疏参数的平滑解)。
3、对参数引入高斯分布等于L2正则,对参数引入拉普拉斯分布等于L1正则。
L1,L2正则化项可以认为是为模型导入了先验分布,对模型向量进行“惩罚”。正则化项本质上是一种先验信息,整个最优化问题从贝叶斯观点来看是一种贝叶斯最大后验估计,其中正则化项对应后验估计中的先验信息,损失函数对应后验估计中的似然函数,两者的乘积即对应贝叶斯最大后验估计的形式,如果你将这个贝叶斯最大后验估计的形式取对数,即进行极大似然估计,你就会发现问题立马变成了损失函数+正则化项的最优化问题形式。
第3点可参考前面线性回归的内容
四、Spark
博主刚学Spark,绝对的菜鸡,瞎写些。
1.
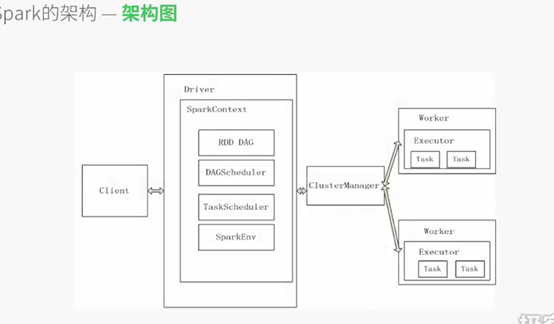
用户提交应用,ClusterManager接收到应用后会启动Driver,Driver会创建SparkContext对象,将应用拆分成多个RDD DAG。之后这些DAG会提交给DAGScheduler,DAGScheduler会再把DAG拆分成多个Stage,提交个TaskScheduler,TaskScheduler会将这些TASK分发到Worker节点的Executor中执行,Executor会启动多个线程。
2.spark可以进行缓存的几个时机:1、特别耗时的步骤 2、计算链条已经很长了 3、Shuffle之后 4、ChechPoint之前
3.spark弹性的表现:1、自动进行内存和磁盘数据存储的切换。2、基于Lineage的高效容错。3、Task如果失败会自动进行特定次数的重试。4、Stage如果失败会自动进行特定次数的重试。
4.Driver部分的代码:SparkConf+SparkContext Executor中的代码:textFile,Flatmap,Map。Executor是运行在Worker节点中的,为当前应用程序开启的进程里的对象,这个对象复杂了具体task的执行。默认情况下,一个Worker只为当前的应用程序开启了一个Executor。
Spark Application的运行,不依赖与Cluster Manager。
Worker管理当前Node的计算资源,并接受Master的指令,来分配具体的计算资源Executor
5.Spark程序的运行有两种模式:Client和Cluster。SparkContext最重要做的事:创建DAGScheduler、TaskScheduler、SchedulerBackend。在实例化的过程中注册当前程序给Master,Master接收注册,如果没有问题,Master会为当前程序分配Appid并分配计算资源。
6.一般情况下,当通过action触发Job时,SparkContext会通过DAGScheduler来把Job中的RDD构成的DAG划分为不同的Stage,每个Stage内部是一系列业务逻辑完全相同但是数据不同的Tasks,构成TaskSet。 TaskScheduler和SchedulerBackend负责Task的运行(遵循数据本地性,数据本地性在DAGScheduler划分Stages时确定的)