在微信公众号看到一篇文章叫做《用ELK分析你的支付宝账单》,看了以后跃跃欲试,并且也很想学习一下ELK技术,所以就将这次的小实验当作ELK的入门吧。
一. 什么是ELK?
ELK指的是elasticsearch, logstash和kibana,Elasticsearch是基于Lucene的分布式搜索引擎,它对Lucene进行了封装,提供了RestApi。Logstash负责采集数据,可以从多个数据源中获取数据、转换数据。kibana则是提供了对ES中的数据的可视化展示和搜索。
二.数据准备
首先在支付宝官网下载自己的支付宝账单(csv格式),先备份一份,另外一份删除表头表尾,只保留数据部分。
如下图,支付宝提供的csv有显示每一列的列名,意味着我们可以通过这些列名来识别每一列分别是干什么的,并且通过Logstash进行解析。

三、ELK的安装
这次我打算先将ELK都安装我的电脑(Windows系统)
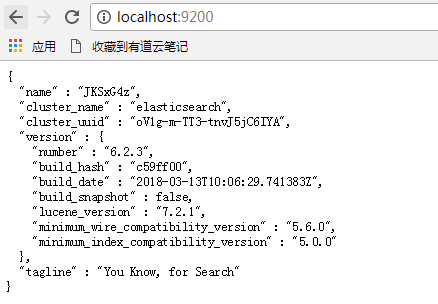
ElasticSearch的安装:解压zip文件,然后直接运行安装目录下bin里面的ElasticSearch.bat即可,要验证是否启动成功,用浏览器访问localhost:9200,如果返回json格式的数据,说明ES启动成功。
注意:因为数据中包含中文,为了避免乱码,应在conf目录下的jvm.options文件中,把-Dfile.encoding=UTF-8改成-Dfile.encoding=GBK.

启动ElasticSearch后访问localhost:9200
Logstash的安装:解压zip文件,要配置好conf文件,运行bin目录下logstash.sh,并用-f指定conf文件的位置。

Kibana的安装,解压zip文件后,打开conf下的kibana.yml,配置好elasticsearch.url="http://localhost:9200"(其实只是被注释了,只需要解开注释即可),然后再运行bin目录下的kibana.bat

然后访问localhost:5601,看到以下界面,说明kibana启动成功了。
四.Logstash的配置
下面这幅图展示了Logstash的pipeline以及在Logstash中数据的流向。
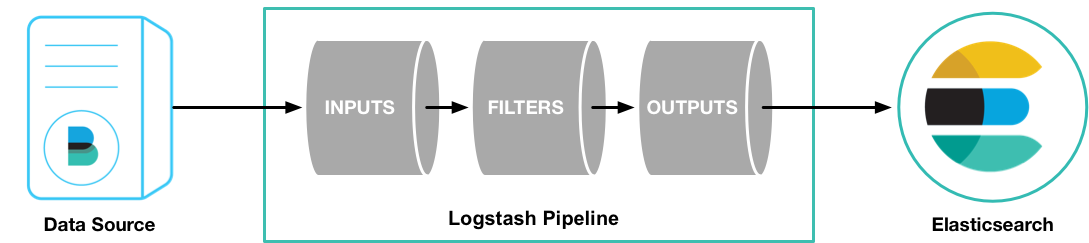
Logstash的配置文件包括三部分,input,filter和output,Logstash的配置实际上是这三部分plugin的配置。
input部分
input{ file{ type => "zhifubao" path => ["D:qingfeiELKdatajenny_alipay.csv"] start_position=>"beginning" codec=> plain { charset=> "GBK" } } }
这里的file就是input的其中一个插件,file plugin的作用是从文件中获取数据,一般是通过tail -0f的形式来读取文件,但我用的是自己的支付宝账单,并不会实时的更新,所以我指定start_position为beginning。type可以用来区分数据的类型,在后面的filter和output中都需要用到。codec用的是GBK.
filter部分:
filter { if[type] == "zhifubao" { csv { separator=>"," columns => ["TranId","OrderId","CreateTime","PayTime","LastModified","TranSource","Type","CounterParty","ProductName","Amount","inOut","status","serviceCost","IssuccessRefund","Remark","Status"] convert => { "Amount" => "float" } } date { match => ["CreateTime","M/dd/yyyy HH:mm:ss","M/dd/yyyy HH:mm"] } } }
Filter部分我们使用的是csv plugin和date plugin。由于我们输入的数据文件是csv文件,csv plugin可以解析csv文件并把它们保存成指定的column.
separator属性是我们要告诉csv plugin,column与column之间的分隔符是什么,默认是逗号。
columns属性的数据类型是数组,这里指定的是将数据文件中的数据解析成那些column,这里必须按照csv中的顺序来写。
默认所有的column都会被解析成Text类型,但如果我们要进行分析,我们需要一些数值类型的数据,convert属性可以对column进行数据类型的转换,例如这里是将amount转换成float类型的数据。
date plugin是用于将某些column转换为日期用于数据分析。match属性的数据类型是数组,格式是[“field name”,formats....],第一个元素是要转换的column名,后面可以为任意多个值,用于定义日期的格式。为什么要定义格式呢?因为date plugin并不知道输入的数据是对应的日期是怎样的,年月日怎么获取,所以我们要告诉date plugin,如何获取年月日小时分钟。所以此时我们必须要观察我们的数据,来确定格式。
以下是部分的日期数据,通过观察可以发现,CreateTime的值是按照“月份/日期/年份 小时:分钟”的格式来表示时间的。

通过查阅date plugin的文档,确定了格式。
output部分:
output { if[type]=="zhifubao" { elasticsearch { hosts => ["localhost:9200"] index => "jenny" } } }
因为我们要将数据导入到ES,所以就应该使用elasticsearch plugin。hosts指定es的host,index指定es中的索引名。
五、在配置Logstash中遇到的问题
启动Logstash后,我发现我的date plugin配置有错误,所以修改了配置,一直重启logstash和es,却发现我的配置一直没有生效。后来我在想是不是要重新创建索引,所以我把output的index的名字改了,重启logstash和es,发现还是不生效,甚至新的index都没有被创建。
后来查找了stackoverflow(https://stackoverflow.com/questions/32742379/logstash-file-input-glob-not-working)以及官方文档,发现了一个叫sincedb的配置。官网是这么解释sincedb的。
The plugin keeps track of the current position in each file by recording it in a separate file named sincedb. This makes it possible to stop and restart Logstash and have it pick up where it left off without missing the lines that were added to the file while Logstash was stopped.
By default, the sincedb file is placed in the home directory of the user running Logstash with a filename based on the filename patterns being watched (i.e. the path option).
我的理解是因为logstash对于每一个文件都会记录上一次读到/解析到的位置,保存在一个叫sincedb的文件,因为文件一直没有更新,所以即使我不停地重新启动logstash和重新指定一个索引,logstash都会从上次读到的位置开始读。所以新的索引一直无法创建成功。后来在conf文件里将sincedb的路径指向null,就可以创建新索引了。
所以新的logstash的配置文件内容如下:
input{ file{ type => "zhifubao" path => ["D:qingfeiELKdatajenny_alipay.csv"] start_position=>"beginning" codec=> plain { charset=> "GBK" } sincedb_path => "null" } } filter { if[type] == "zhifubao" { csv { separator=>"," columns => ["TranId","OrderId","CreateTime","PayTime","LastModified","TranSource","Type","CounterParty","ProductName","Amount","inOut","status","serviceCost","IssuccessRefund","Remark","Status"] convert => { "Amount" => "float" } } date { match => ["CreateTime","M/dd/yyyy HH:mm:ss","M/dd/yyyy HH:mm"] } } } output { if[type]=="zhifubao" { elasticsearch { hosts => ["localhost:9200"] index => "jenny" } } }
重启logstash以后,新的index就被创建了。
接下来的任务就是用kibana展示和分析数据了,这部分放在下一篇文章。