学习真的是一件令人开心的事情,上次分享了 Redis 入门的文章后,收到了很多小伙伴的鼓励,比如说:“哎呀,不错呀,二哥,通俗易懂,十分钟真的入门了”。瞅瞅,瞅瞅,我决定再接再厉,入门一下 Elasticsearch,因为我们公司的商城系统升级了,需要用 Elasticsearch 做商品的搜索。
不过,我首先要声明一点,我对 Elasticsearch 并没有进行很深入的研究,仅仅是因为要用,就学一下。但作为一名负责任的技术博主,我是用心的,为此还特意在某某时间上买了一门视频课程,作者叫阮一鸣。说实话,他光秃秃的头顶让我对这门课程产生了浓厚的兴趣。
经过三天三夜的学习,总算是入了 Elasticsearch 的门,我就决定把这些心得体会分享出来,感兴趣的小伙伴可以作为参考。遇到文章中有错误的地方,不要手下留情,过来捶我,只要不打脸就好。

01、Elasticsearch 是什么
Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。 作为 Elastic Stack 的核心,它集中存储您的数据,帮助您发现意料之中以及意料之外的情况。
以上引用来自于官方,不得不说,解释得蛮文艺的。意料之中和意料之外,这两个词让我想起来了某一年的高考作文题(情理之中和意料之外)。
Elastic Stack 又是什么呢?整个架构图如下图(来源于网络,侵删)所示。
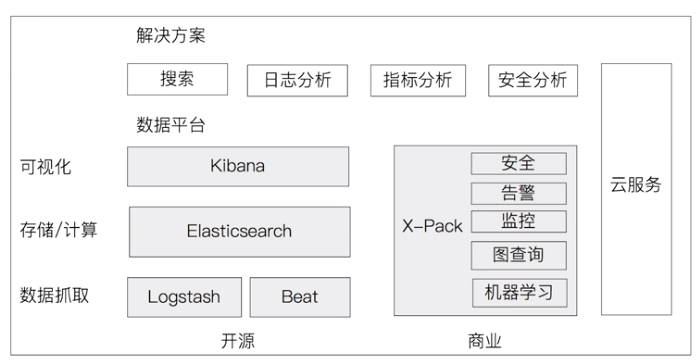
信息量比较多,对吧?那就记住一句话吧,Elasticsearch 是 Elastic Stack 的核心。
国内外的很多知名公司都在用 Elasticsearch,比如说滴滴、今日头条、谷歌、微软等等。Elasticsearch 有很多强大的功能,比如说全文搜索、购物推荐、附近定位推荐等等。
理论方面的内容就不说太多了,我怕小伙伴们会感到枯燥。毕竟入门嘛,实战才重要。
02、安装 Elasticsearch
Elasticsearch 是由 Java 开发的,所以早期的版本需要先在电脑上安装 JDK 进行支持。后来的版本中内置了 Java 环境,所以直接下载就行了。Elasticsearch 针对不同的操作系统有不同的安装包,我们这篇入门的文章就以 Windows 为例吧。
下载地址如下:
https://www.elastic.co/cn/downloads/elasticsearch
最新的版本是 7.6.2,280M 左右。但我硬生生花了 10 分钟的时间才下载完毕,不知道是不是连通的 200M 带宽不给力,还是官网本身下载的速度就慢,反正我去洗了 6 颗葡萄吃完后还没下载完。
Elasticsearch 是免安装的,只需要把 zip 包解压就可以了。
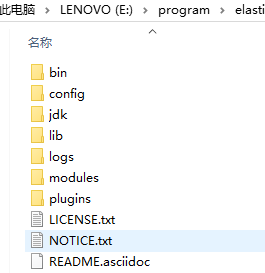
1)bin 目录下是一些脚本文件,包括 Elasticsearch 的启动执行文件。
2)config 目录下是一些配置文件。
3)jdk 目录下是内置的 Java 运行环境。
4)lib 目录下是一些 Java 类库文件。
5)logs 目录下会生成一些日志文件。
6)modules 目录下是一些 Elasticsearch 的模块。
7)plugins 目录下可以放一些 Elasticsearch 的插件。
直接双击 bin 目录下的 elasticsearch.bat 文件就可以启动 Elasticsearch 服务了。
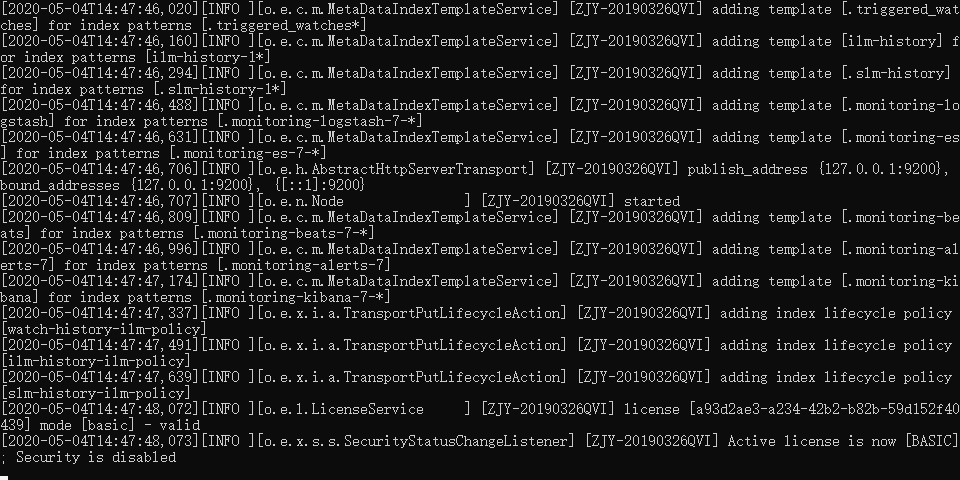
输出的日志信息有点多,不用细看,注意看到有“started”的字样就表明启动成功了。为了进一步确认 Elasticsearch 有没有启动成功,可以在浏览器的地址栏里输入 http://localhost:9200 进行查看(9200 是 Elasticsearch 的默认端口号)。
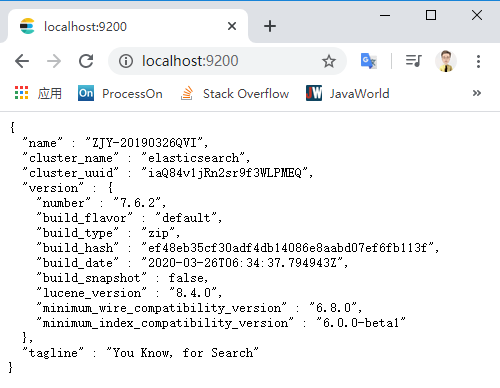
你看,为了 Search。
那如何停止服务呢?可以直接按下 Ctrl+C 组合键——粗暴、壁咚。
03、安装 Kibana
通过 Kibana,我们可以对 Elasticsearch 服务进行可视化操作,就像在 Linux 操作系统下安装一个图形化界面一样。
下载地址如下:
https://www.elastic.co/cn/downloads/kibana
最新的版本是 7.6.2,284M 左右,体积和 Elasticsearch 差不多。选择下载 Windows 版,zip 格式的,完成后直接解压就行了。下载的过程中又去洗了 6 颗葡萄吃,狗头。
包目录不再一一解释了,进入 bin 目录下,双击运行 kibana.bat 文件,启动 Kibana 服务。整个过程比 Elasticsearch 要慢一些,当看到 [Kibana][http] http server running 的信息后,说明服务启动成功了。
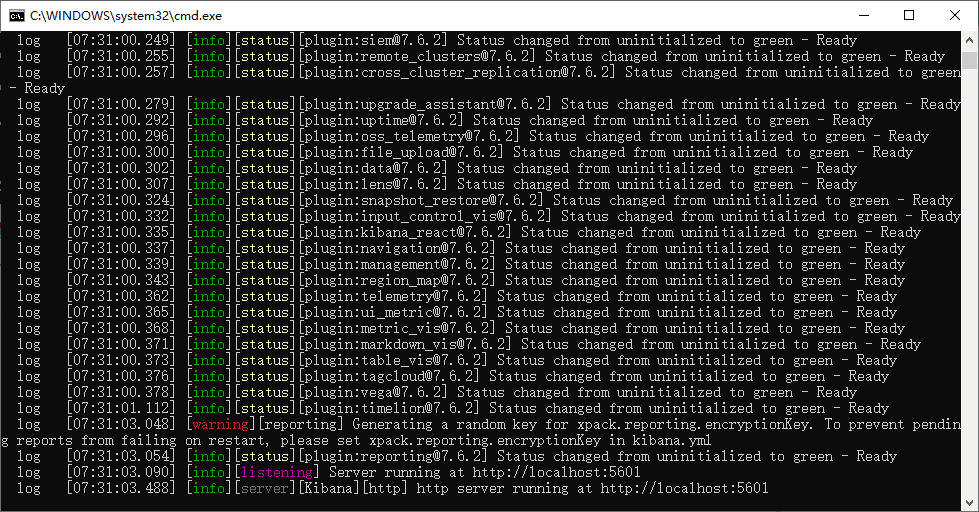
在浏览器地址栏输入 http://localhost:5601 查看 Kibana 的图形化界面。

由于当前的 Elasticsearch 服务端中还没有任何数据,所以我们可以选择「Try Our Sample Data」导入 Kibana 提供的模拟数据体验一下。下图是导入电商数据库的看板页面,是不是很丰富?
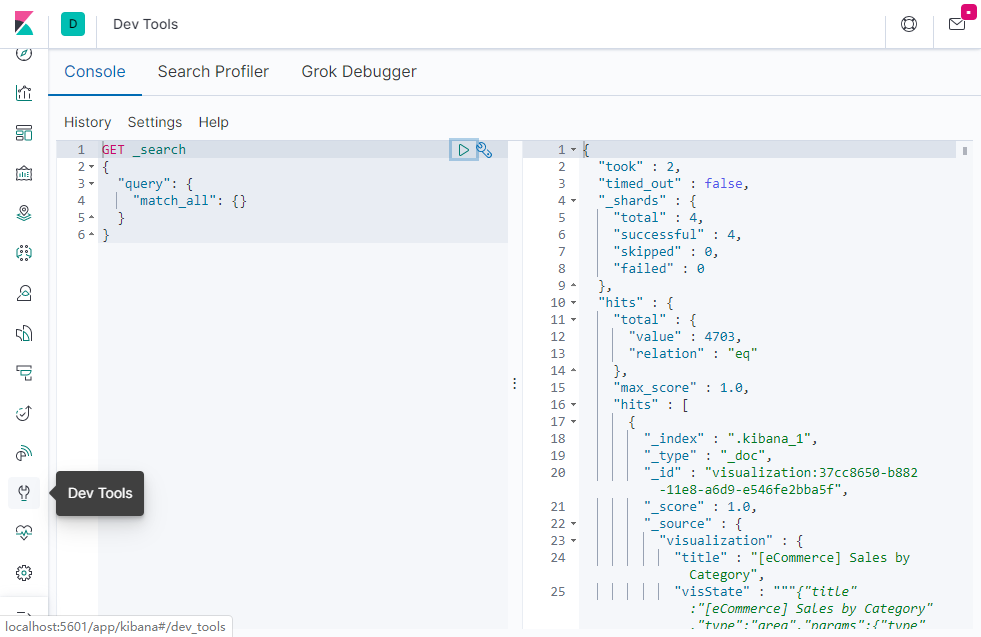
打开 Dev Tools 面板,可以看到一个简单的 DSL 查询语句(一种完全基于 JSON 的特定于领域的语言),点击「运行」按钮后就可以看到 JSON 格式的数据了。
04、Elasticsearch 的关键概念
在进行下一步之前,需要先来理解 Elasticsearch 中的几个关键概念,比如说什么是索引,什么是类型,什么是文档等等。Elasticsearch 既然是一个数据引擎,它里面的一些概念就和 MySQL 有一定的关系。
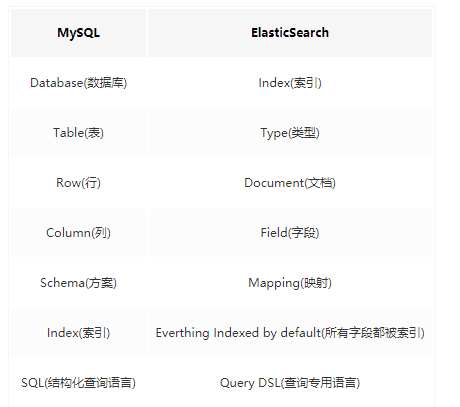
看完上面这幅图(来源于网络,侵删),是不是瞬间就清晰了。向 Elasticsearch 中存储数据,其实就是向 Elasticsearch 中的 index 下面的 type 中存储 JSON 类型的数据。
05、在 Java 中使用 Elasticsearch
有些小伙伴可能会问,“二哥,我是一名 Java 程序员,我该如何在 Java 中使用 Elasticsearch 呢?”这个问题问得好,这就来,这就来。
Elasticsearch 既然内置了 Java 运行环境,自然就提供了一系列 API 供我们操作。
第一步,在项目中添加 Elasticsearch 客户端依赖:
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.6.2</version>
</dependency>
第二步,新建测试类 ElasticsearchTest:
public class ElasticsearchTest {
public static void main(String[] args) throws IOException {
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9200, "http")));
IndexRequest indexRequest = new IndexRequest("writer")
.id("1")
.source("name", "沉默王二",
"age", 18,
"memo", "一枚有趣的程序员");
IndexResponse indexResponse = client.index(indexRequest, RequestOptions.DEFAULT);
GetRequest getRequest = new GetRequest("writer", "1");
GetResponse getResponse = client.get(getRequest, RequestOptions.DEFAULT);
String sourceAsString = getResponse.getSourceAsString();
System.out.println(sourceAsString);
client.close();
}
}
1)RestHighLevelClient 为 Elasticsearch 提供的 REST 客户端,可以通过 HTTP 的形式连接到 Elasticsearch 服务器,参数为主机名和端口号。
有了 RestHighLevelClient 客户端,我们就可以向 Elasticsearch 服务器端发送请求并获取响应。
2)IndexRequest 用于向 Elasticsearch 服务器端添加一个索引,参数为索引关键字,比如说“writer”,还可以指定 id。通过 source 的方式可以向当前索引中添加文档数据源(键值对的形式)。
有了 IndexRequest 对象后,可以调用客户端的 index() 方法向 Elasticsearch 服务器添加索引。
3)GetRequest 用于向 Elasticsearch 服务器端发送一个 get 请求,参数为索引关键字,以及 id。
有了 GetRequest 对象后,可以调用客户端的 get() 方法向 Elasticsearch 服务器获取索引。getSourceAsString() 用于从响应中获取文档数据源(JSON 字符串的形式)。
好了,来看一下程序的输出结果:
{"name":"沉默王二","age":18,"memo":"一枚有趣的程序员"}
完全符合我们的预期,perfect!
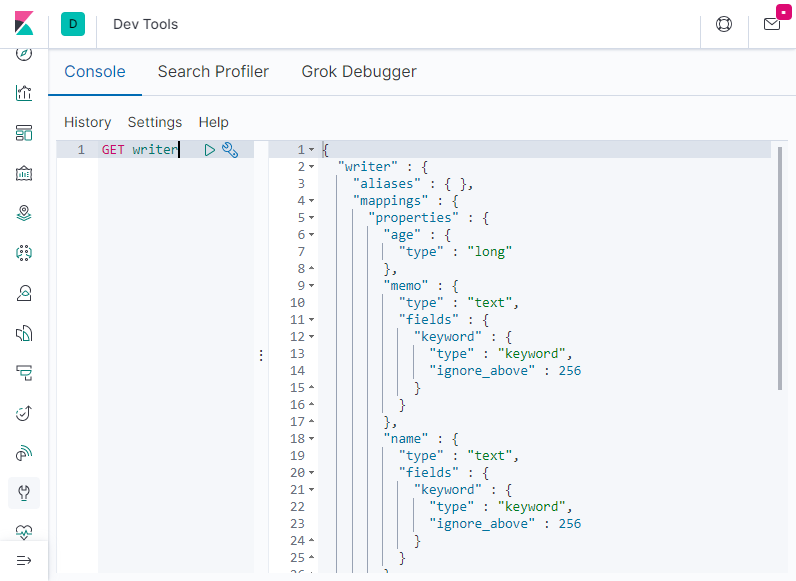
也可以通过 Kibana 的 Dev Tools 面板查看“writer”索引,结果如下图所示。
06、鸣谢
好了,我亲爱的小伙伴们,以上就是本文的全部内容了,是不是看完后很想实操一把 Elasticsearch,赶快行动吧!如果你在学习的过程中遇到了问题,欢迎随时和我交流,虽然我也是个菜鸟,但我有热情啊。
另外,如果你想写入门级别的文章,这篇就是最好的范例。
我是沉默王二,一枚有趣的程序员。如果觉得文章对你有点帮助,请微信搜索「 沉默王二 」第一时间阅读,回复【666】更有我为你精心准备的 500G 高清教学视频(已分门别类)。
本文 GitHub 已经收录,有大厂面试完整考点,欢迎 Star。
原创不易,莫要白票,请你为本文点个赞吧,这将是我写作更多优质文章的最强动力。