关于从0到1搭建大数据平台,之前的一篇博文《如何从0到1搭建大数据平台》已经给大家介绍过了,接下来我们会分步讲解搭建大数据平台的具体注意事项。
一、“大”数据
海量的数据
当你需要搭建大数据平台的时候一定是传统的关系型数据库无法满足业务的存储计算要求了,所以首先我们面临的是海量的数据。
复杂的数据
复杂数据的概念和理想数据完全相反。所有数据集都有一定的复杂性,但有一些天生更难处理。通常这些复杂数据集没有定义结构(没有行列结构),经常变化,数据质量很差。比如更新的网页日志,json数据,xml数据等。
高速的数据
高速数据通常被认为是实时的或是准实时的数据流。数据流本质上是在生成后就发给处理器的数据包,比如物联网的穿戴设备,制造业的传感器,车联网的终端芯片等等。处理实时数据流有很多挑战,包括在采集时不丢失数据、处理数据流中的重复记录、数据如何实时写入磁盘存储、以及如何进行实时分析。
二、采集工具
日志采集
我们业务平台每天都会有大量用户访问,会产生大量的访问日志数据,比如电商系统的浏览,加入购物车,下订单,付款等一系列流程我们都可以通过埋点获取到用户的访问路径以及访问时长这些数据;再比智能穿戴设备,实时都会采集我们的血压、脉搏、心率等数据实时上报到云端。通过分析这些日志信息,我们可以得到出很多业务价值。通过对这些日志信息进行日志采集、收集,然后进行数据分析,挖掘公司业务平台日志数据中的潜在价值。为公司决策和公司后台服务器平台性能评估提高可靠的数据保证。系统日志采集系统做的事情就是收集日志数据提供离线和在线的实时分析使用。目前常用的开源日志收集系统有Flume、Logstash、Filebeat。可以根据自己公司的技术栈储备或者组件的优缺点选择合适的日志采集系统,目前了解到的Flume使用的比较多。各个采集工具的对别如下:
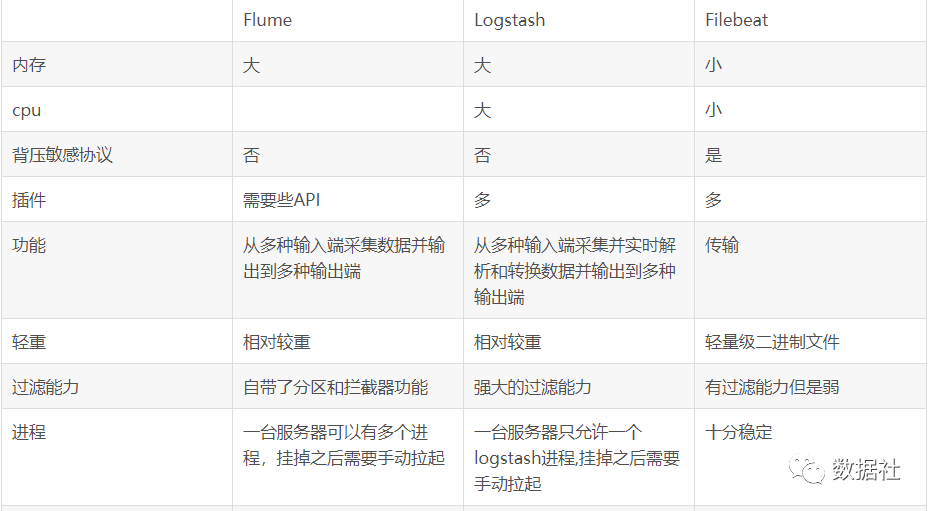
具体组价的相关配置可以参考之前的文章《日志收集组件—Flume、Logstash、Filebeat对比》
数据库抽取

企业一般都会会使用传统的关系型数据库MySQL或Oracle等来存储业务系统数据。每时每刻产生的业务数据,以数据库一行记录的形式被直接写入到数据库中保存。
大数据分析一般是基于历史海量数据,多维度分析,我们不能直接在原始的业务数据库上直接操作,因为分析的一些复杂SQL查询会明显的影响业务数据库的效率,导致业务系统不可用。所以我们通常通过数据库采集系统直接与企业业务后台数据库服务器结合,在业务不那么繁忙的凌晨,抽取我们想要的数据到分析数据库或者到HDFS上,最后有大数据处理系统对这些数据进行清洗、组合进行数据分析。
常用数据库抽取工具:
-
阿里开源软件:DataX
DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。开源的DataX貌似只能单机部署。
-
Apache开源软件:Sqoop
Sqoop(发音:skup)是一款开源的工具,主要用于在HADOOP(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。可以集群化部署。
爬虫爬取
有很多外部数据,比如天气、IP地址等数据,我们通常会爬取相应的网站数据存储。目前常用的爬虫工具是Scrapy,它是一个爬虫框架,提供给开发人员便利的爬虫API接口。开发人员只需要关心爬虫API接口的实现,不需要关心具体框架怎么爬取数据。Scrapy框架大大降低了开发人员开发速率,开发人员可以很快的完成一个爬虫系统的开发。
三、数据存储
HDFS
2003年,Google发布论文GFS,启发Apache Nutch开发了HDFS。2004年,Google 又发布了论文《MapReduce: Simplified Data Processing on Large Clusters》,Doug Cutting等人实现计算框架MapReduce ,并与HDFS结合来更好的支持该框架。2006年项目从Butch搜索引擎中独立出来,成为了现在的Hadoop。
GFS隐藏了底层的负载均衡,切片备份等细节,使复杂性透明化,并提供统一的文件系统接口。其成本低,容错高,高吞吐,适合超大数据集应用场景。
-
HDFS原理:
横向扩展,增加“数据节点”就能增加容量。 -
增加协调部门,“命名节点”维护元数据,负责文件系统的命名空间,控
-
外部访问,将数据块印射到数据节点。还会备份元数据从命名节点,它只与命名节点通信。
-
数据在多个数据节点备份。
通常关系型数据库存储的都是结构化的数据,我们抽取后会直接放到HDFS上作为离线分析的数据源。
HBase
在实际应用中,我们有很多数据可能不需要复杂的分析,只需要我们能存储,并且提供快速查询的功能。HBase在HDFS基础上提供了Bigtable的能力; 并且基于列的模式进行存储。列存储设计的有事减少不必要的字段占用存储,同时查询的时候也可以只对查询的指定列有IO操作。HBase可以存储海量的数据,并且可以根据rowkey提供快速的查询性能,是非常好的明细数据存储方案,比如电商的订单数据就可以放入HBase提供高效的查询。
当然还有其他的存储引擎,比如ES适合文本搜索查询等。
总结
了解了上面的技术栈后,在实际数据接入中,你还会面临各种问题,比如如何考虑确保数据一致性,保障数据不能丢失,数据采集存储的效率,不能产生数据积压等,这些都需要对每个组件进行研究,适配适合你自己业务系统的参数,用最少的资源,达到最好的结果。
历史好文推荐