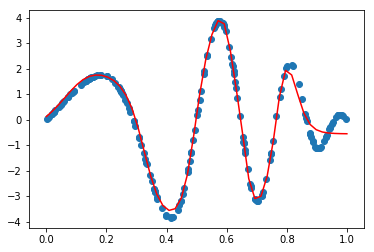
%matplotlib inline import numpy as np import torch from torch import nn import matplotlib.pyplot as plt d = 1 n = 200 X = torch.rand(n,d) #200*1, batch * feature_dim #y = 3*torch.sin(X) + 5* torch.cos(X**2) y = 4 * torch.sin(np.pi * X) * torch.cos(6*np.pi*X**2) #注意这里hid_dim 设置是超参数(如果太小,效果就不好),使用tanh还是relu效果也不同,优化器自选 hid_dim_1 = 128 hid_dim_2 = 32 d_out = 1 model = nn.Sequential(nn.Linear(d,hid_dim_1), nn.Tanh(), nn.Linear(hid_dim_1, hid_dim_2), nn.Tanh(), nn.Linear(hid_dim_2, d_out) ) loss_func = nn.MSELoss() optim = torch.optim.SGD(model.parameters(), 0.05) epochs = 6000 print("epoch loss ") for i in range(epochs): y_hat = model(X) loss = loss_func(y_hat, y) optim.zero_grad() loss.backward() optim.step() if((i+1)%100 == 0): print("{} {:.5f}".format(i+1,loss.item())) #这个地方容易出错,测试时不要用原来的x,因为原来的x不是从小到达排序,导致x在连线时会混乱,所以要用np.linspace重新来构造 test_x = torch.tensor(np.linspace(0,1,50), dtype = torch.float32).reshape(-1,1) final_y = model(test_x) plt.scatter(X,y) plt.plot(test_x.detach(),final_y.detach(),"r") #不使用detach会报错 print("over")
epoch loss 100 3.84844 200 3.83552 300 3.78960 400 3.64596 500 3.43755 600 3.17153 700 2.59001 800 2.21228 900 1.87939 1000 1.55716 1100 1.41315 1200 1.26750 1300 1.05869 1400 0.91269 1500 0.81320 1600 0.74047 1700 0.67874 1800 0.61939 1900 0.56204 2000 0.51335 2100 0.47797 2200 0.45317 2300 0.43151 2400 0.40505 2500 0.37628 2600 0.34879 2700 0.32457 2800 0.30431 2900 0.28866 3000 0.30260 3100 0.26200 3200 0.30286 3300 0.25229 3400 0.21422 3500 0.22737 3600 0.22905 3700 0.19909 3800 0.24601 3900 0.17733 4000 0.22905 4100 0.15704 4200 0.21570 4300 0.14141 4400 0.14657 4500 0.14609 4600 0.11998 4700 0.12598 4800 0.10871 4900 0.08616 5000 0.18319 5100 0.08111 5200 0.08213 5300 0.11087 5400 0.06879 5500 0.07235 5600 0.11281 5700 0.06817 5800 0.08423 5900 0.06886 6000 0.06301