看到标题,肯定知道,这一篇又是定位,因为我们做自动化测试,第一步就是定位元素,如果元素都定位不好,那么怎么实现代码点点点?
Xpath
XPath , 全称XML Path Language ,即XML 路径语言,它是一门在XML 文档中查找信息的语言。它最初是用来搜寻XML 文档的,但是它同样适用于HTML 文档的搜索。XPath的选择功能十分强大,它提供了非常简明的路径选择表达式,另外,它还提供了超过100个内建函数,用于字符串、数值、时间的匹配以及节点、序列的处理等,几乎所有我们想要定位的节点,都可以用XPath来选择。
Xpath常用属性
格式:
# XPath定位方法 driver.find_element_by_xpath('//*[@属性=元素值]')
| 表达式 | 描述 |
| nodename | 选取此节点的所有子节点 |
| / | 从当前节点选取直接子节点 |
| // | 从当前节点选取子孙节点 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
| * | 通配符,选择所有元素节点与元素名 |
| @* | 选取所有属性 |
| [@属性] | 选取具有给定属性的所有元素 |
| [@属性=‘value’] | 选取给定属性具有给定值的所有元素 |
通用方法定位
这里安静还是以百度输入框为例子
1、通过id属性定位
# coding:utf-8 from selenium import webdriver driver = webdriver.Chrome()
# 通过id属性定位 driver.get('https://www.baidu.com/')driver.find_element_by_xpath('//*[@id="kw"]').send_keys('测试-安静博客园')
2、通过name属性定位
# coding:utf-8 from selenium import webdriver driver = webdriver.Chrome() driver.get('https://www.baidu.com/') # 通过name属性定位 driver.find_element_by_xpath('//*[@name="wd"]').send_keys('测试-安静博客园')
3、通过class属性定位
# coding:utf-8 from selenium import webdriver driver = webdriver.Chrome() driver.get('https://www.baidu.com/') # 通过class属性定位 driver.find_element_by_xpath('//*[@class="s_ipt"]').send_keys('测试-安静博客园')
4、通过text属性定位
# coding:utf-8 from selenium import webdriver driver = webdriver.Chrome() driver.get('https://www.baidu.com/') # 通过text属性定位 driver.find_element_by_xpath('//*[text()="新闻"]').click()
5、通过contains方法定位
contains属于 属性中包含XXX就可以进行匹配
# coding:utf-8 from selenium import webdriver driver = webdriver.Chrome() driver.get('https://www.baidu.com/') # 通过contains方法中的text属性定位# driver.find_element_by_xpath('//*[contains(text(),"地图")]').click() # 通过contains方法中的id属性定位 driver.find_element_by_xpath('//*[contains(@id,"kw")]').send_keys('测试-安静博客园')
6、通过标签名进行定位
前面了解到XPath定位前面的*表示标签,如果多个标签的话,我们可以直接通过标签进行匹配
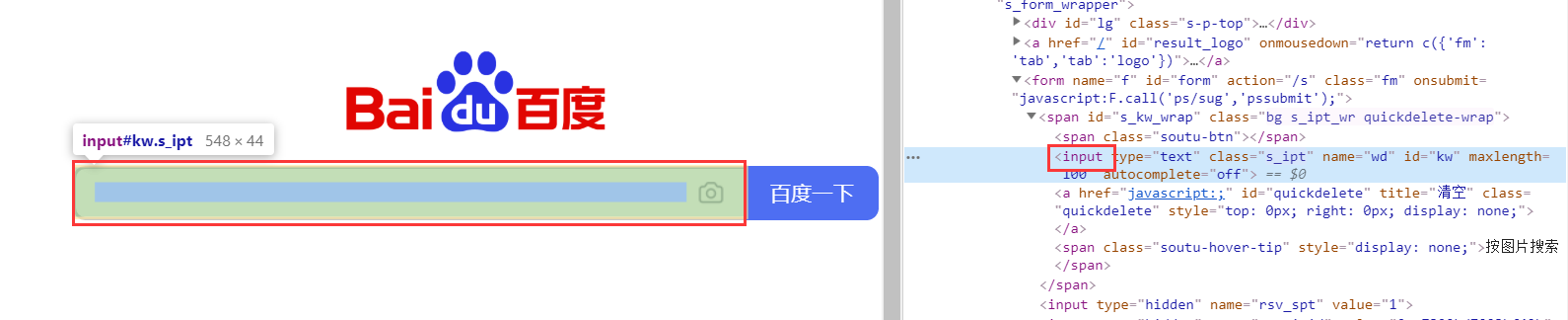
# coding:utf-8 from selenium import webdriver driver = webdriver.Chrome() driver.get('https://www.baidu.com/') # 通过标签名进行匹配 driver.find_element_by_xpath('//input[@id="kw"]').send_keys('测试-安静博客园')
7、多个属性进行匹配
前面大多数都是唯一表示的属性,那么我们可能会遇到不是唯一标识的,那么我们可以通过多个属性进行定位
# coding:utf-8 from selenium import webdriver driver = webdriver.Chrome() driver.get('https://www.baidu.com/') # 通过多个属性进行定位 driver.find_element_by_xpath('//*[@id="kw" and @name="wd"]').send_keys('测试-安静博客园')
8、通过父级或者爷爷级进行定位
在遇到元素无法定位的时候,我们可以用个定位元素的父级或者爷爷级别的进行定位

# coding:utf-8 from selenium import webdriver driver = webdriver.Chrome() driver.get('https://www.baidu.com/') # 通过上级进行定位 driver.find_element_by_xpath("//form[@id='form']/span[contains(@class,'s_ipt_wr')]/input").send_keys('测试-安静博客园')
定位元素这个东西,只有多练,多写,才能孰能生巧。定位方法很多种,大家可以自己看看哪一种适合自己。
如果安静写的对您有帮助,可以点个关注,不懂得地方或者写错的地方可以下方留言,持续更新中~