前面通过python爬虫爬取过图片,文字,今天我们一起爬取下b站的小视频,其实呢,测试过程中需要用到视频文件,找了几个网站下载,都需要会员什么的,直接写一篇爬虫爬取视频~~~
分析b站小视频
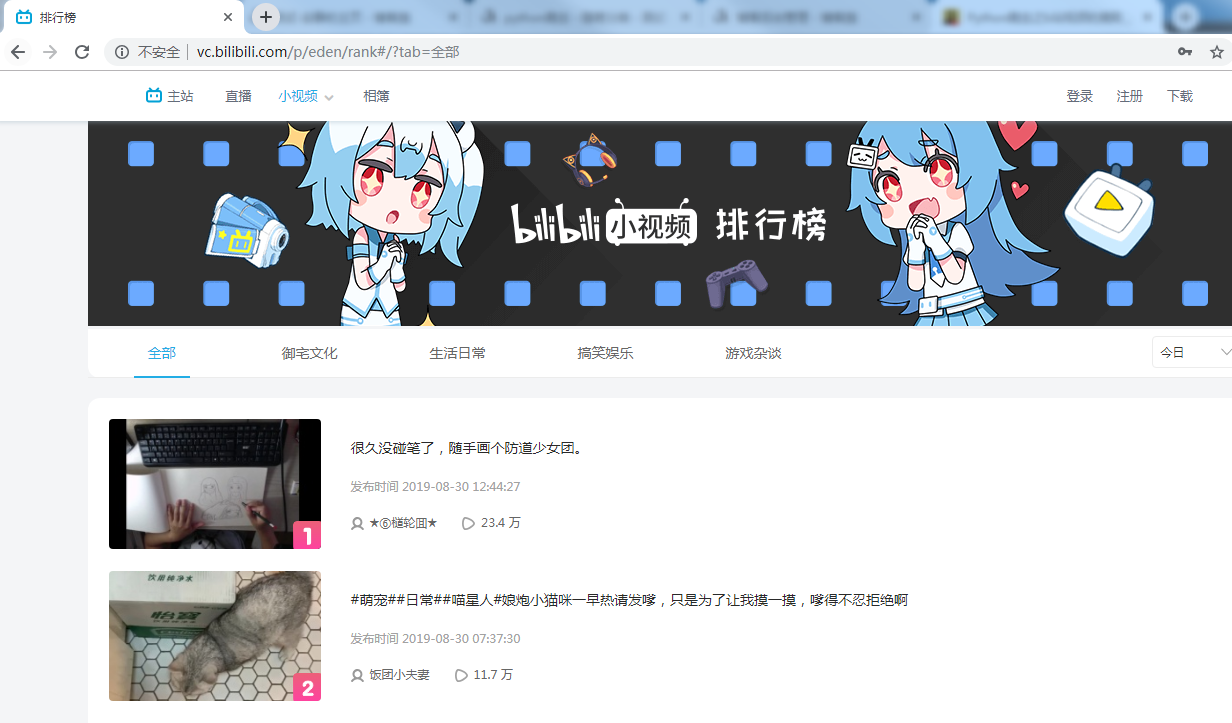
1、进入到抓取链接地址
http://vc.bilibili.com/p/eden/rank#/?tab=%E5%85%A8%E9%83%A8
2、分析抓取链接内容
通过F12或者抓包工具进行查看我们需要爬取的视频在哪里存放,页面以ajax动态加载的
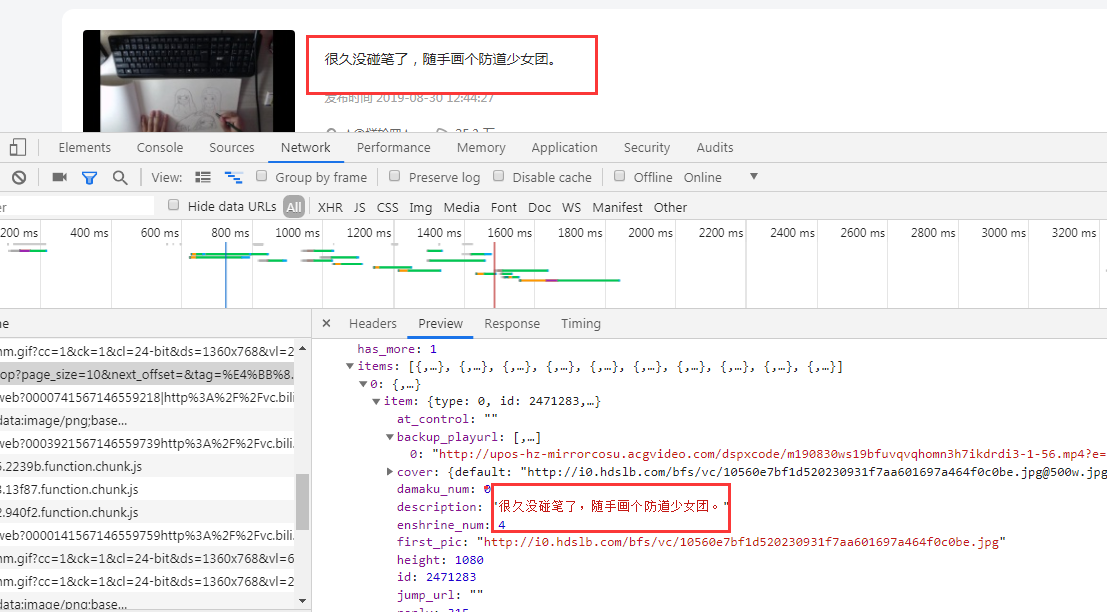
3、分析请求内容和请求参数
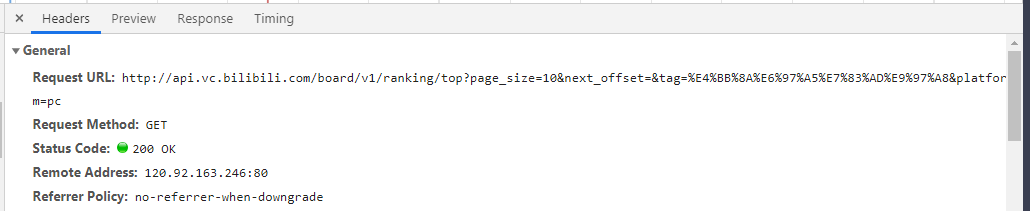
通过查看请求内容得到这些数据
1、请求的接口地址
2、请求方式为get
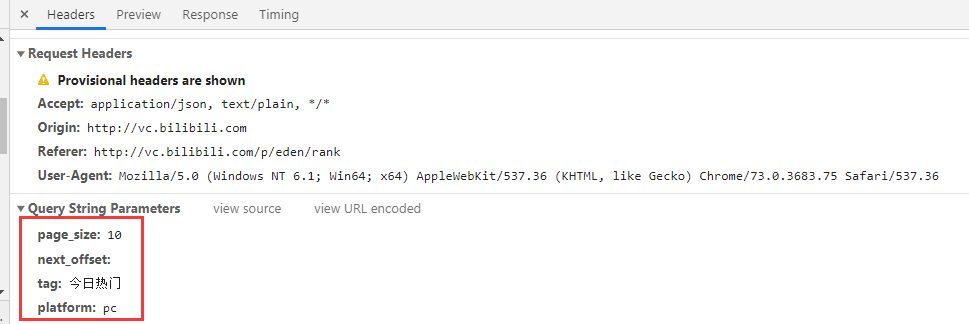
3、请求参数为
- page_size 显示的个数
- next_offset 动态跳转页面
- tag 搜索标题
- platfrom (应该是pc端)
分析了页面内容,那么动手来写代码,爬取视频下来
爬取b站小视频
开始写代码之前呢,我们也要一步一步的来,分清楚每一步都是干什么用的,这样的话才能让我们写的代码更加清除。
1、构建请求信息,请求需要爬取的地址
# 构建请求信息,获取数据信息 def get_json(url,ajax): # 构建请求信息 params = { 'page_size':10, 'next_offset': ajax, 'tag':'今日热门', 'platform':'pc' } # 防止请求失败 try: html = requests.get(url,params=params,headers=headers).json() return html except BaseException: print('页面加载失败')
2、进行访问链接,下载视频
# 获取视频信息 def get_video(viedeo_url,path): # 取出来视频的名称和地址 r2 = requests.get(viedeo_url,headers=headers) with open(path,'wb')as f: f.write(r2.content)
3、保存下载的视频
infos=html['data']['items'] for info in infos: title = info['item']['description']#小视频的标题 video_url = info['item']['video_playurl']#视频地址 print(title,video_url) #为了防止视频没有video_url try: get_video(video_url,path=r"E:app视频\%s.mp4"%title) print("成功下载一个") except BaseException: print("下载失败") pass
完整代码
import requests import random import time headers = { "User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36" } def get_json(url,ajax): # 构建请求信息 params = { 'page_size':10, 'next_offset': ajax, 'tag':'今日热门', 'platform':'pc' } # 防止请求失败 try: html = requests.get(url,params=params,headers=headers).json() return html except BaseException: print('页面加载失败') def get_video(viedeo_url,path): # 取出来视频的名称和地址 r2 = requests.get(viedeo_url,headers=headers) with open(path,'wb')as f: f.write(r2.content) if __name__ == '__main__': for i in range(3): url='http://api.vc.bilibili.com/board/v1/ranking/top?' num=i*10+1 html=get_json(url,num) infos=html['data']['items'] for info in infos: title = info['item']['description']#小视频的标题 video_url = info['item']['video_playurl']#视频地址 print(title,video_url) #为了防止视频没有video_url try: get_video(video_url,path=r"E:app视频\%s.mp4"%title) print("成功下载一个") except BaseException: print("下载失败") pass # 设置加载时间 time.sleep(random.random() * 3)
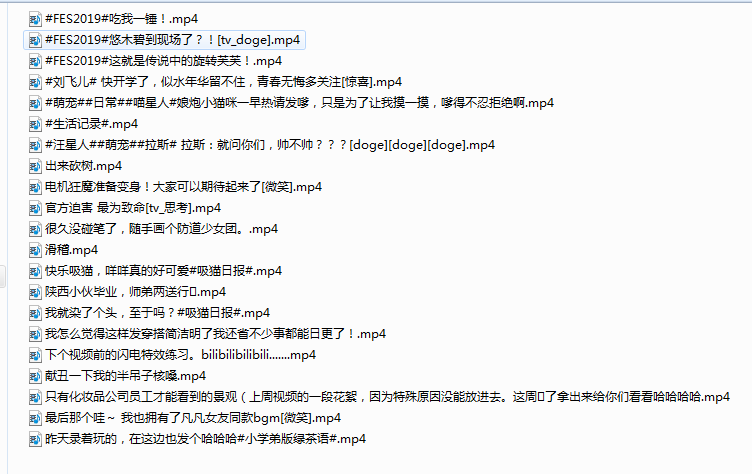
写的时间有点紧急,大概的写了下过程,如果不懂的地方可以下方留言,看到后第一时间会进行回复,感觉写的对您有帮助,点个关注~~~~