原文地址:http://www.cnblogs.com/qiaoyihang/p/7348385.html
下面有两张表
数学试卷成绩
表1
|
学号 |
省份 |
批次 |
学校 |
试卷成绩 |
数学试卷小题成绩
表2
|
学号 |
小题号 |
分值 |
成绩 |
下面是星型模型:
维度:省份,批次,学校 指标:标准差,信度(比较有代表性)
星型模型表
表3
|
省份(维度) |
批次(维度) |
学校(维度) |
试卷最高分(指标) |
试卷标准差(指标) |
试卷信度(指标) |
上面是我的OLAP 星型模型,在我同时选中维度:省份,批次,学校 指标:信度这个信度是正确的。
如果我要查询省份成绩的试卷信度,在这个情况下
在我选中 维度:省份 指标:信度
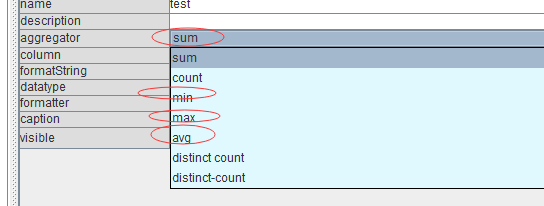
Mondrian支持sum,count,avg等,如下图

但是并不没有信度的计算,同时,信度不能用sum累加,更不能count,min,max进行聚合。
我在从表3中通过省份查询,会得出多条记录。
我如何解决查询选择省份,得出正确的信度值?
我解决的方式是:
通过Mondrian的聚合表优化的特性:
下面是三张聚合表:
agg_1(表4)
|
省份 |
批次 |
试卷最高分(指标) |
试卷标准差(指标) |
试卷信度(指标) |
agg_2(表5)
|
省份 |
学校 |
试卷最高分(指标) |
试卷标准差(指标) |
试卷信度(指标) |
agg_3(表6)
|
省份 |
试卷最高分(指标) |
试卷标准差(指标) |
试卷信度(指标) |
mondrian的聚合表使用规则是:
agg_1(表4)
agg_2(表5)
agg_3(表6)
上面是三张聚合表,如果我们查询的指标是:试卷最高分, 上面的三张聚合表都身份维度
那么,从上面的任何一张聚合表查询的结果都正确。
刨根究底的人会好奇,mondrian作为OLAP服务器引擎,会查询哪一张聚合表得到结果?
mondrian会首先查询上面所有的聚合表,获取每张表的数据量。
表的数据量关系依次是: agg_1 > agg_2>agg_3
为了提升性能,mondrian会选择数据量最少的表,就是agg_3,数据量最少的表,相应最快。
我就是应用这条规则:
如果我创建了agg_3这张聚合表,mondrian引擎就好选择聚合表agg_3上查询信度,
在星型模型设计器上,
我选择红色圈起来的,其得到的结果都是一样的。
如果,我要查询的维度变了
在我选中 维度:批次 指标:信度
这个维度时,mondrian引擎,会选择
agg_1(表4)
|
省份 |
批次 |
试卷最高分(指标) |
试卷标准差(指标) |
试卷信度(指标) |
在这种情况下,批次对应了多个省份,
根据批次查询的信度,就是多个省份的信度值
如果前面是sum,查询的结果sum就是多个省份的信度值累加,这是错误的。
如果要查询到正确的信度值
需要创建一张聚合表
agg_batch(表7)
|
批次 |
试卷最高分(指标) |
试卷标准差(指标) |
试卷信度(指标) |
这个聚合表只有一个批次维度,查询的信度值才是正确的。
如果 我操作选中
维度:省份,批次 指标:信度
mondrian引擎,会选择agg_1(表4),得到的结果才是正确的,这种维度组合,agg_1的结果才会正确。
OK,通过上面的例子,我们对信度指标,聚合表已经有了个大概的了解。
这个设计有个缺点
每一种维度组合,都需要有一种维度表对应,信度,平均分,区分度等指标查询的结果才能保证正确。
需要对OLAP星型模型的所有维度进行组合
组合的结果集为:
如果有5个维度
取一个维度: C(5,1) 5种组合
取二个维度: C(5,2) 10种组合
取三个维度: C(5,3) 10种组合
取四个维度: C(5,4) 5种组合
取五个维度: C(5,5) 1种组合
总的组合数为: C(5,1)+ C(5,2)+ C(5,3)+ C(5,4)+ C(5,5) = 31种
如果有6个维度
C(6,1)+ C(6,2)+ C(6,3)+ C(6,4)+ C(6,5)+C(6,6) = 63种
如果有8个维度
2的8次方减1等于255种
如果有3个维度
2的3次方减1等于7种
一个星型模型的维度是有限的,kylin最大支持15个维度,我觉得,Mondrian也是需要有极限,2的16次方是65 536。
16个维度就产生65 535个聚合表。
通过梳理我们业务,差不多有15到16个维度,但通过去除一些无意义的组合(例如,年份,科目试卷,两个维度只选择一个维度,其OLAP组合没有意义)
维度降低为11个,也就是2047张聚合表。
但是,实际应用中。一般模型的维度一般都在8个以内,其聚合表也就是255张表。在计算上是可控的。