data.table包提供了一个非常简洁的通用格式:DT[i,j,by]。
可以理解为:对于数据集DT,选取子集行i,通过by分组计算j。
对比与dplyr等包,data.table的运行速度更快。
创建方式和data.frame 一样
创建一个data.frame:
DF = data.frame(x=c("b","b","b","a","a"),v=rnorm(5))
创建一个data.table:
DT = data.table(x=c("b","b","b","a","a"),v=rnorm(5))
data.frame转换为data.table类型:
DT = data.table(DF)
查看内存中所有的data.table
tables()
构建一个数据集用于测试
library(data.table)
CARS = data.table(cars)
X=data.table(speed=c(4,7,8),type=c("small","middle","large"))
dt <- CARS[X,on='speed']
tables()
dt
# speed dist type
# 1: 4 2 small
# 2: 4 10 small
# 3: 7 4 middle
# 4: 7 22 middle
# 5: 8 16 large
Keys
Keys在data.table中是一个重要的概念,在一个data.table中只能设置一个key,但是这一个key可以包含多个列。当我们设置好key后,data.table会将数据按照key来排序。
# 选取第二行
dt[2,]
# 选取speed=4 的行
dt[speed==4]
# 更快,更简单的表达
#筛选行
setkey(dt,type)
dt["small"]
dt[c("small","large")]
dt[.("small","large")]
dt["small",mult='first']
dt["small",mult='last']
dt[speed %between% c(7,8)]
dt[speed %in% c(7,8)]
all.equal(ans1,ans2)
#把列当作行 筛选其他列
dt["small",speed]
dt["small","speed"]
dt["small",2]
dt["small",2,on="type"]# on 相当于使用了setkey
# 筛选列
# 选取第一列
dt[,1]
# 选取第一到第二列
dt[,1:2]
# 选取列也可以直接输入列名
dt[,.(speed,dist)]
# 排序 speed升序,dist降序排列
setorder(dt,speed,-dist)
删选子集
选取子集仍然采用subset函数,调用公式为:
# subset是行满足条件
# select是列满足条件
> subset(x, subset, select)
subset(dt,speed==8,select =c('speed','dist'))
重排序数据框的列
可以通过数值位置重排序:
|
1
2
|
# 通过列的数值位置重排序dat = dat[c(1,3,2)] |
也可以通过列的名称重排序:
|
1
2
|
# 通过列的名称重排序dat = dat[c("col1", "col3", "col2")] |
# 接下下我们创建一个1000万行的数据,用来演示data.table的性能 grpsize = ceiling(1e7/26^2) # 10 million rows, 676 groups tt=system.time( DF <- data.frame( x=rep(LETTERS,each=26*grpsize), y=rep(letters,each=grpsize), v=runif(grpsize*26^2), stringsAsFactors=FALSE) ) dim(DF)
我们试试将DF中x为“R”的行与y为”h”的行提取出来
system.time(ans1 <- DF[DF$x=="R" & DF$y=="h",])
# 用户 系统 流逝
# 0.06 0.08 0.14
DT = as.data.table(DF)
system.time(setkey(DT,x,y))
# 用户 系统 流逝
# 0.05 0.01 0.07
system.time(ans2 <- DT[list("R","h")])
# 用户 系统 流逝
0 0 0
x与y这两列返回一个data.table
data.table也允许用 .() 来包围列名,它是 list() 的别名,它们的效果是同样的。如果不使用.()或者list,结果为返回一个向量
可以看到,当我们设置好key后,提取行的操作基本不需要等待时间,比我们平时用的操作快了100倍。要注意的是,如果使用”==”操作符,那么它会扫描整个数组,虽然data.table用这种方法也可以提取,但很慢,要尽量避免。
system.time(ans1 <- DT[x=="R" & y=="h"]) # works but is using data.table badly # 用户 系统 流逝 # 0.06 0.04 0.11
(不建议这样使用)
下面我们要看data.table的第二个参数
DT[,sum(v)] ## [1] 4999770 head(DT[,sum(v),by=x])
以上代码以x为分组,依次调用sum函数,统计了每个分组x的总和。
# 单一分组 dt[,.(total=sum(dist),avg=mean(dist)),by=type] # type total avg # 1: small 12 6 # 2: middle 26 13 # 3: large 16 16 # 多分组 dt[,.(total=sum(dist),avg=mean(dist)),by=list(type,speed)] # data.table有一个特殊的变量.N可以直接计算分组的观测值个数。 dt[,.N,by=type]
显然这一功能在plyr包和dplyr包也有相对应的函数实现,接下来我们比较一下这3个包的速度。
#plyr包
system.time(
ddply(DF,.(x),function(x)sum(x$v))
)
## user system elapsed
## 1.71 0.22 1.94
#dplyr包
system.time({
DF%>%
group_by(x)%>%
summarise(sum(v))
})
## user system elapsed
## 0.60 0.12 0.72
#data.table包
DT = as.data.table(DF)
system.time({
DT[,sum(v),by=x]
})
## user system elapsed
## 0.12 0.02 0.14
增加删除列
# 单变量添加
DT[i, LHS:=RHS, by=...]
# LHS为新建的变量,RHS为该变量的计算方式
# 双变量添加
DT[i, c("LHS1","LHS2") := list(RHS1, RHS2), by=...]
# #多变量添加,注意`:=`
DT[i, `:=`(LHS1=RHS1,LHS2=RHS2,...), by=...]
# 单变量 dt[,total:=speed+dist] # speed dist type total # 1: 4 10 small 14 # 2: 4 2 small 6 # 3: 7 22 middle 29 # 4: 7 4 middle 11 # 5: 8 16 large 24 # 删除变量(变量:=NULL即可) dt[,total:=NULL]
#当我们把data.frame数据框转化成data.table时,默认抛弃行名,不过我们也可以用一个参数保留行名成为新的一列
df1 <- data.frame(weight,height,row.names = name1) dt1 <- as.data.table(df1) dt2 <- as.data.table(df1,keep.rownames=T) # 将原来数据框中的行名当成一列,列名为rn dt1;dt2 as.data.table(df1,keep.rownames = "rownames") # 自己指定新增列的列名
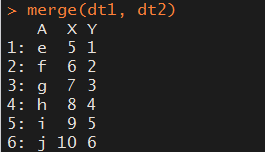
# 数据合并仍然采用merge函数,只是合并对象必须是data.table类型,这样才能发挥出data.table的威力!> merge(x, y, by = NULL, by.x = NULL, by.y = NULL,all = FALSE, all.x = all, all.y = all, sort = TRUE, suffixes = c(".x", ".y"),
allow.cartesian=getOption("datatable.allow.cartesian"), ...)
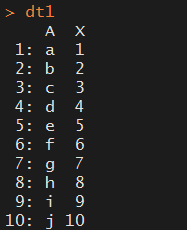
dt1 <- data.table(A = letters[1:10], X = 1:10, key = "A") dt2 <- data.table(A = letters[5:14], Y = 1:10, key = "A")


join 连接操作
使用DT[X],该操作会将X中key(没指定key则默认第一列)与DT的key作连接,同理,X[DT]会将DT与X作连接
DT = data.table(x=rep(c("a","b","c"),each=3), y=c(1,3,6), v=1:9)
DT ## x y v ## 1: a 1 1 ## 2: a 3 2 ## 3: a 6 3 ## 4: b 1 4 ## 5: b 3 5 ## 6: b 6 6 ## 7: c 1 7 ## 8: c 3 8
## 9: c 6 9
X = data.table(c("b","c"),foo=c(4,2))
X
## V1 foo
## 1: b 4
## 2: c 2
setkey(DT,x) DT[X] ## x y v foo ## 1: b 1 4 4 ## 2: b 3 5 4 ## 3: b 6 6 4 ## 4: c 1 7 2 ## 5: c 3 8 2 ## 6: c 6 9 2 setkey(X,V1) X[DT] ## V1 foo y v ## 1: a NA 1 1 ## 2: a NA 3 2 ## 3: a NA 6 3 ## 4: b 4 1 4 ## 5: b 4 3 5 ## 6: b 4 6 6 ## 7: c 2 1 7 ## 8: c 2 3 8 ## 9: c 2 6 9
我们也可以使用on操作来连接两个相同的列:
DT = data.table(x=rep(c("a","b","c"),each=3), y=c(1,3,6), v=1:9)
X = data.table(x=c("b","c"),foo=c(4,2))
DT[X, on="x"] # join on columns 'x'
## x y v foo
## 1: b 1 4 4
## 2: b 3 5 4
## 3: b 6 6 4
## 4: c 1 7 2
## 5: c 3 8 2
## 6: c 6 9 2
本文出自:http://blog.csdn.net/a358463121,感谢分享~
参考文献:https://cran.r-project.org/web/packages/data.table/data.table.pdf
Data.Table若干高级技巧
http://blog.csdn.net/iqqiqqiqqiqq/article/details/51812957
关于dplyr 和data.table的比较 可参考:
http://www.xueqing.tv/cms/article/213