Sqoop与HDFS结合
下面我们结合 HDFS,介绍 Sqoop 从关系型数据库的导入和导出。
Sqoop import
它的功能是将数据从关系型数据库导入 HDFS 中,其流程图如下所示。
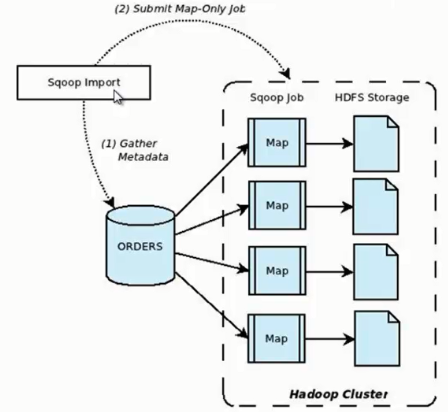
我们来分析一下 Sqoop 数据导入流程,首先用户输入一个 Sqoop import 命令,Sqoop 会从关系型数据库中获取元数据信息,比如要操作数据库表的 schema是什么样子,这个表有哪些字段,这些字段都是什么数据类型等。它获取这些信息之后,会将输入命令转化为基于 Map 的 MapReduce作业。这样 MapReduce作业中有很多 Map 任务,每个 Map 任务从数据库中读取一片数据,这样多个 Map 任务实现并发的拷贝,把整个数据快速的拷贝到 HDFS 上。
下面我们看一下 Sqoop 如何使用命令行来导入数据的,其命令行语法如下所示
sqoop import
--connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop
--username sqoop
--password sqoop
--table user
--target-dir /junior/sqoop/ //可选,不指定目录,数据默认导入到/user下
--where "sex='female'" //可选
--as-sequencefile //可选,不指定格式,数据格式默认为 Text 文本格式
--num-mappers 10 //可选,这个数值不宜太大
--null-string '\N' //可选
--null-non-string '\N' //可选
--connect:指定 JDBC URL。
--username/password:mysql 数据库的用户名。
--table:要读取的数据库表。
--target-dir:将数据导入到指定的 HDFS 目录下,文件名称如果不指定的话,会默认数据库的表名称。
--where:过滤从数据库中要导入的数据。
--as-sequencefile:指定数据导入数据格式。
--num-mappers:指定 Map 任务的并发度。
--null-string,--null-non-string:同时使用可以将数据库中的空字段转化为'N',因为数据库中字段为 null,会占用很大的空间。
下面我们介绍几种 Sqoop 数据导入的特殊应用。
1、Sqoop 每次导入数据的时候,不需要把以往的所有数据重新导入 HDFS,只需要把新增的数据导入 HDFS 即可,下面我们来看看如何导入新增数据。
sqoop import
--connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop
--username sqoop
--password sqoop
--table user
--incremental append //代表只导入增量数据
--check-column id //以主键id作为判断条件
--last-value 999 //导入id大于999的新增数据
上述三个组合使用,可以实现数据的增量导入。
2、Sqoop 数据导入过程中,直接输入明码存在安全隐患,我们可以通过下面两种方式规避这种风险。
1)-P:sqoop 命令行最后使用 -P,此时提示用户输入密码,而且用户输入的密码是看不见的,起到安全保护作用。密码输入正确后,才会执行 sqoop 命令。
sqoop import
--connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop
--username sqoop
--table user
-P
2)--password-file:指定一个密码保存文件,读取密码。我们可以将这个文件设置为只有自己可读的文件,防止密码泄露。
sqoop import
--connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop
--username sqoop
--table user
--password-file my-sqoop-password
Sqoop export
它的功能是将数据从 HDFS 导入关系型数据库表中,其流程图如下所示。
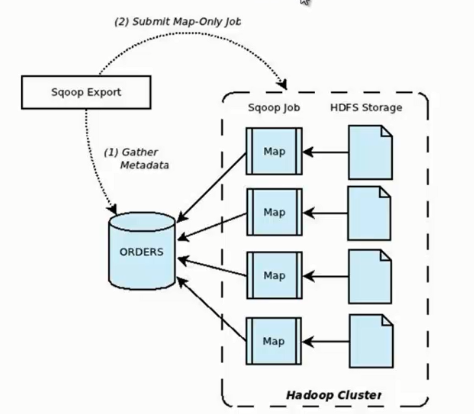
我们来分析一下 Sqoop 数据导出流程,首先用户输入一个 Sqoop export 命令,它会获取关系型数据库的 schema,建立 Hadoop 字段与数据库表字段的映射关系。 然后会将输入命令转化为基于 Map 的 MapReduce作业,这样 MapReduce作业中有很多 Map 任务,它们并行的从 HDFS 读取数据,并将整个数据拷贝到数据库中。
下面我们看一下 Sqoop 如何使用命令行来导出数据的,其命令行语法如下所示。
sqoop export
--connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop
--username sqoop
--password sqoop
--table user
--export-dir user
--connect:指定 JDBC URL。
--username/password:mysql 数据库的用户名和密码。
--table:要导入的数据库表。
--export-dir:数据在 HDFS 上的存放目录。
下面我们介绍几种 Sqoop 数据导出的特殊应用。
1、Sqoop export 将数据导入数据库,一般情况下是一条一条导入的,这样导入的效率非常低。这时我们可以使用 Sqoop export 的批量导入提高效率,其具体语法如下。
sqoop export
--Dsqoop.export.records.per.statement=10
--connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop
--username sqoop
--password sqoop
--table user
--export-dir user
--batch
--Dsqoop.export.records.per.statement:指定每次导入10条数据,--batch:指定是批量导入。
2、在实际应用中还存在这样一个问题,比如导入数据的时候,Map Task 执行失败, 那么该 Map 任务会转移到另外一个节点执行重新运行,这时候之前导入的数据又要重新导入一份,造成数据重复导入。 因为 Map Task 没有回滚策略,一旦运行失败,已经导入数据库中的数据就无法恢复。Sqoop export 提供了一种机制能保证原子性, 使用--staging-table 选项指定临时导入的表。Sqoop export 导出数据的时候会分为两步:第一步,将数据导入数据库中的临时表,如果导入期间 Map Task 失败,会删除临时表数据重新导入;第二步,确认所有 Map Task 任务成功后,会将临时表名称为指定的表名称。
sqoop export
--connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop
--username sqoop
--password sqoop
--table user
--staging-table staging_user
3、在 Sqoop 导出数据过程中,如果我们想更新已有数据,可以采取以下两种方式。
1)通过 --update-key id 更新已有数据。
sqoop export
--connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop
--username sqoop
--password sqoop
--table user
--update-key id
2)使用 --update-key id和--update-mode allowinsert 两个选项的情况下,如果数据已经存在,则更新数据,如果数据不存在,则插入新数据记录。
sqoop export
--connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop
--username sqoop
--password sqoop
--table user
--update-key id
--update-mode allowinsert
4、如果 HDFS 中的数据量比较大,很多字段并不需要,我们可以使用 --columns 来指定插入某几列数据。
sqoop export
--connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop
--username sqoop
--password sqoop
--table user
--column username,sex
5、当导入的字段数据不存在或者为null的时候,我们使用--input-null-string和--input-null-non-string 来处理。
sqoop export
--connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop
--username sqoop
--password sqoop
--table user
--input-null-string '\N'
--input-null-non-string '\N'
Sqoop与其它系统结合
Sqoop 也可以与Hive、HBase等系统结合,实现数据的导入和导出,用户需要在 sqoop-env.sh 中添加HBASE_HOME、HIVE_HOME等环境变量。
1、Sqoop与Hive结合比较简单,使用 --hive-import 选项就可以实现。
sqoop import
--connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop
--username sqoop
--password sqoop
--table user
--hive-import
2、Sqoop与HBase结合稍微麻烦一些,需要使用 --hbase-table 指定表名称,使用 --column-family 指定列名称。
sqoop import
--connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop
--username sqoop
--password sqoop
--table user
--hbase-table user
--column-family city