1. 机器学习算法大致可以分为三种:
1. 监督学习(如回归,分类)
从给定的训练数据集中学习出一个函数(模型参数),当新的数据到来时,可以根据这个函数预测结果。监督学习的训练集要求包括输入输出,也可以说是特征和目标。
简单说就是从一堆有标签的样本中总结出模型,有标签信息,有数据
举例说明:
①回归
通过房地产市场的数据,预测一个给定面积的房屋的价格就是一个回归问题。这里我们可以把价格看成是面积的函数,它是一个连续的输出值。 但是,当把上面的问题改为“预测一个给定面积的房屋的价格是否比一个特定的价格高或者低”的时候,这就变成了一个分类问题, 因为此时的输出是‘高’或者‘低’两个离散的值。
②分类
给定医学数据,通过肿瘤的大小来预测该肿瘤是恶性瘤还是良性瘤这就是一个分类问题,它的输出是0或者1两个离散的值。(0代表良性,1代表恶性)。
分类问题的输出可以多于两个,比如在该例子中可以有{0,1,2,3}四种输出,分别对应{良性, 第一类肿瘤, 第二类肿瘤, 第三类肿瘤}。
2. 非监督学习(如聚类,降维)有数据,没有标签信息。
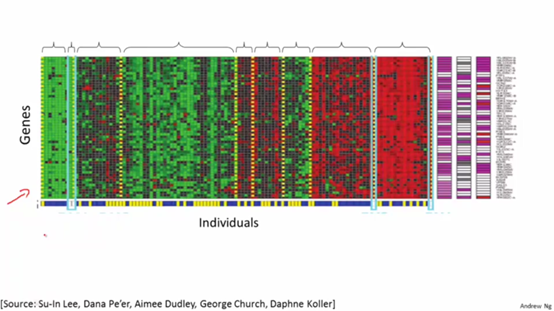
根据给定基因将人群分类
如图是DNA数据,对于一组不同的人我们测量他们DNA中对于一个特定基因的表达程度。然后根据测量结果可以用聚类算法将他们分成不同的类型。这就是一种无监督学习, 因为我们只是给定了一些数据,而并不知道哪些是第一种类型的人,哪些是第二种类型的人等等。
3. 强化学习

智能体如何在环境中采取一系列行为,从而获得最大的累积回报。通过增强学习,一个智能体 (agent)应该知道在什么状态下应该采取什么行为。RL是从环境状态到动作的映射的学习,我们把这个映射称为策略。
强化学习是试错学习,智能体不断与环境进行交互,来获得最佳策略。
4.强化学习能解决的问题,举例说明
(1)flappy bird游戏,现在让小鸟自行进行游戏。不断的进行游戏,如果小鸟撞到柱子了,那就获得-1的回报,否则获得0回报。通过这样的若干次训练,我们最终可以得到一只飞行技能高超的小鸟
(2)构建国际象棋的机器。我们本身不是优秀的棋手,而请象棋老师来遍历每个状态下的最佳棋步则代价过于昂贵。其次,每个棋步好坏判断不是孤立的,要依赖于对手的选择和局势的变化。是一系列的棋步组成的策略决定了是否能赢得比赛。下棋过程的唯一的反馈是在最后赢得或是输掉棋局时才产生的。通过不断的探索和试错学习,增强学习可以获得某种下棋的策略,并在每个状态下都选择最有可能获胜的棋步。
引用:
(1)https://www.cnblogs.com/jinxulin/p/3511298.html
(2)郭宪老师的《深入浅出强化学习-原理入门》