一、移除重复数据
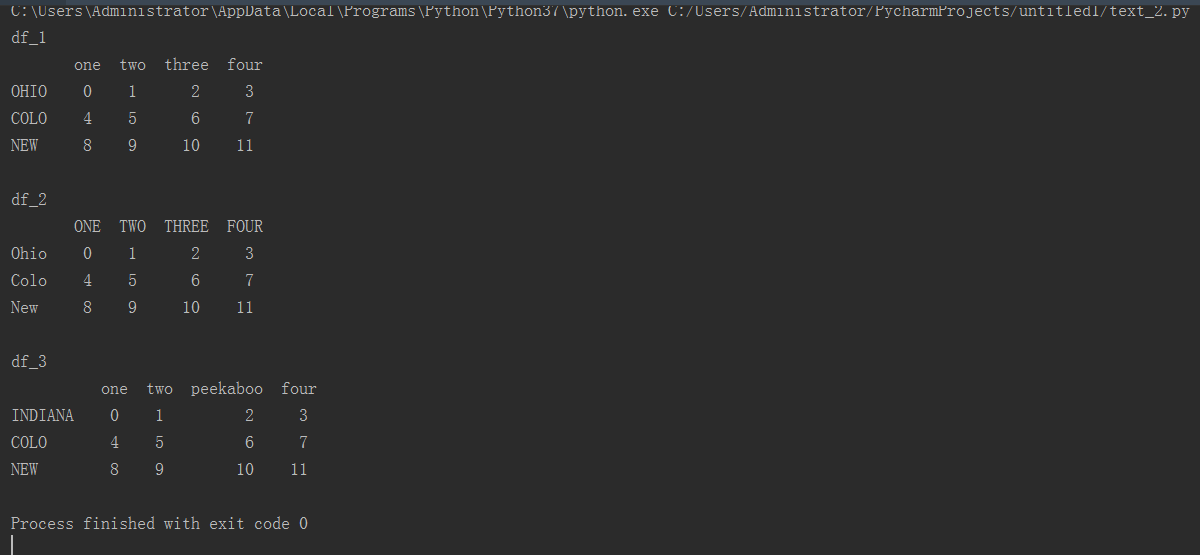
1.1 删除重复行
import pandas as pd df_1 = pd.DataFrame({'k1': ['one', 'two','one']*2, 'k2': ['1','2', '3']*2}) series_1 = df_1.duplicated() df_2 = df_1.drop_duplicates() # 删除重复行,默认判断所有行,默认保留第一次出现的数据 df_3 = df_1[series_1] df_4 = df_1.drop_duplicates(['k1']) # 保留最后一次出现的数据 df_5 = df_1.drop_duplicates(['k1'], keep='last') # 删除重复行,只判读K1列 print('df_1 ', df_1) print(' series_1 ', series_1) print(' df_2 ', df_2) print(' df_3 ', df_3) print(' df_4 ', df_4) print(' df_5 ', df_5)
二、替换值
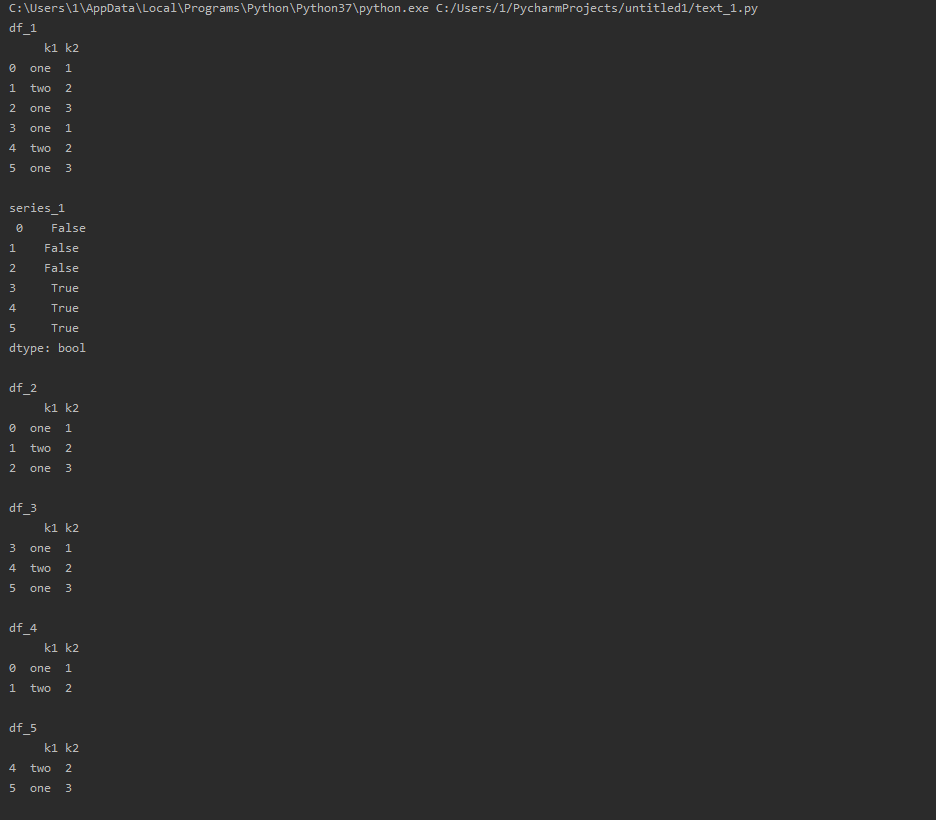
利用fillna方法填充缺失数据可以看做值替换的一种特殊情况。
前面已经看到,map可用于修改对象的数据集,
而replace则提供了多种实现该功能的更简单、更灵活的⽅式。
import pandas as pd from numpy import nan as NA df_1 = pd.DataFrame([[1, 2, 3, 4], [5, 6, 998, 999], [999, 999, 999, 999]]) df_2 = df_1.replace(999, NA) # 一对一替换 df_3 = df_1.replace([998, 999], NA) # 多对一替换 df_4 = df_1.replace([998, 999], [NA, 0]) # 多对多替换 df_5 = df_1.replace({998: NA, 999: 0}) # 多对多替换 print('df_1 ', df_1) print(' df_2 ', df_2) print(' df_3 ', df_3) print(' df_4 ', df_4) print(' df_5 ', df_5)
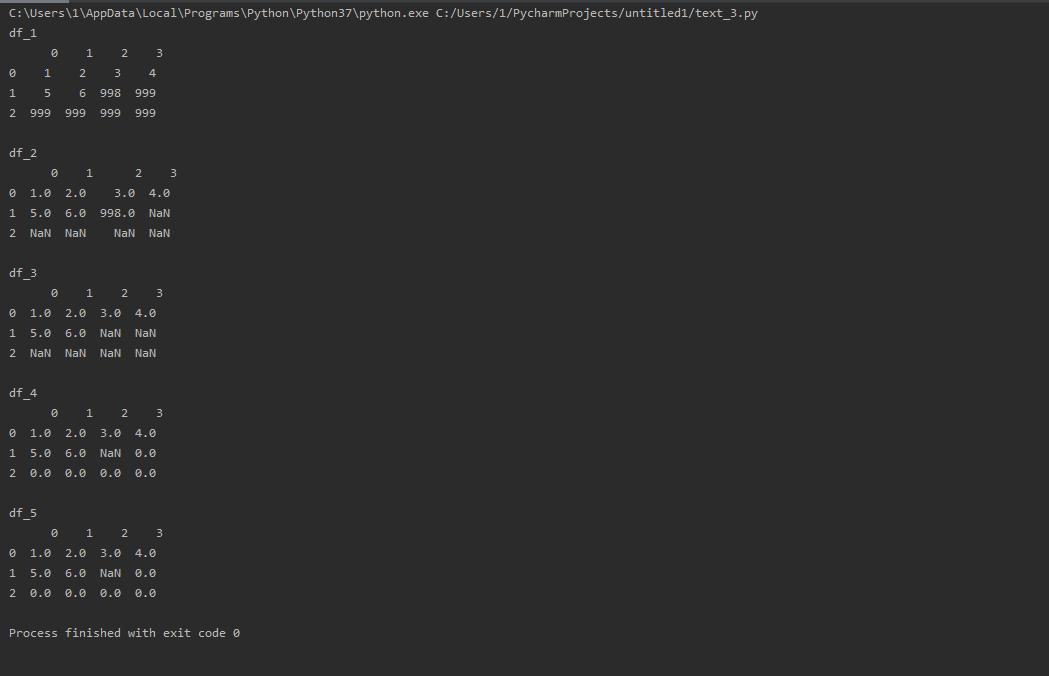
三 、重命名轴索引
import numpy as np df_1 =pd.DataFrame(np.arange(12).reshape(3, 4), index=['Ohio', 'Colorado', 'New York'], columns=['one', 'two', 'three', 'four']) transform = lambda x: x[:4].upper() df_1.index = df_1.index.map(transform) df_2 = df_1.rename(index=str.title, columns=str.upper) df_3 = df_1.rename(index={'OHIO':'INDIANA'}, columns={'three':'peekaboo'}) print('df_1 ', df_1) print(' df_2 ', df_2) print(' df_3 ', df_3)