一、定义
Series是一种类似于一维数组的对象,它由一组数据(各种numpy数据类型)以及一组与之相关的数据标签(索引)组成。
也可以看成一个定长的有序字典。
二、创建
2.1 无索引创建
如果未指定索引,索引默认为0只n-1
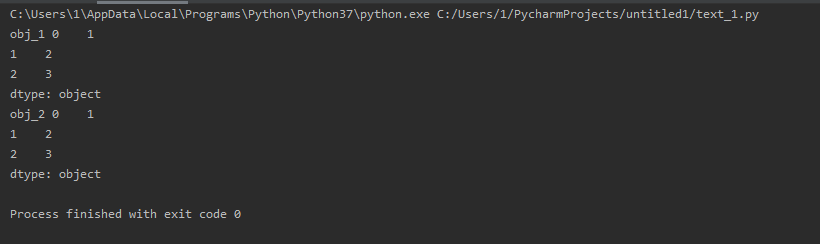
import pandas as pd obj_1 = pd.Series(['1', '2', '3']) obj_2 = pd.Series(('1', '2', '3')) print('obj_1', obj_1) print('obj_2', obj_2)
2.2 有索引创建
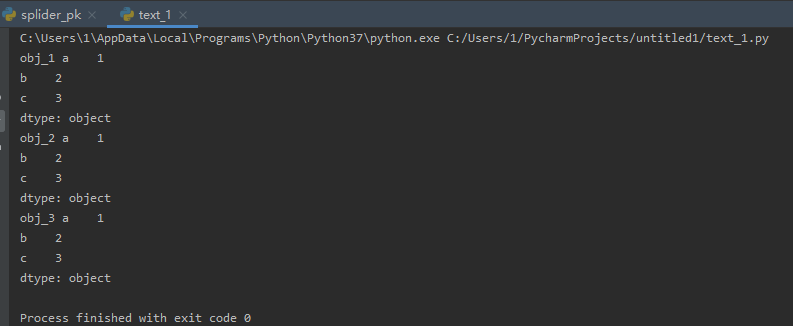
import pandas as pd obj_1 = pd.Series(['1', '2', '3'], index=['a', 'b', 'c']) obj_2 = pd.Series(('1', '2', '3'), index=['a', 'b', 'c']) dict_1 = {'a':1, 'b':'2', 'c':'3'} obj_3 = pd.Series(dict_1) print('obj_1', obj_1) print('obj_2', obj_2) print('obj_3', obj_3)
三、索引
3.1 索引对象不可变,索引可变。
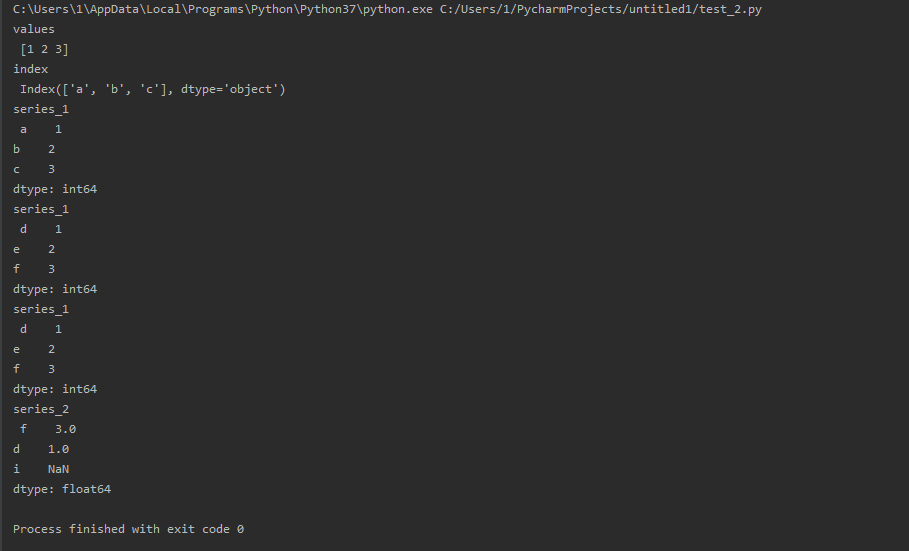
import pandas as pd series_1 = pd.Series([1, 2, 3], index=['a', 'b', 'c']) values = series_1.values index = series_1.index print('values ', values) print('index ', index) print('series_1 ', series_1) series_1.index = ['d', 'e', 'f'] # 更改索引.索引个数不能多也不能少 print('series_1 ', series_1) series_2 = series_1.reindex(['f','d','i']) # 重新索引,索引数量可以变化,索引对象也可以变化 print('series_1 ', series_1) # 注意,此时的series_1未发生变化。 print('series_2 ', series_2) # index[1] = 'd' 更改索引对象,报错
3.2 标签切片
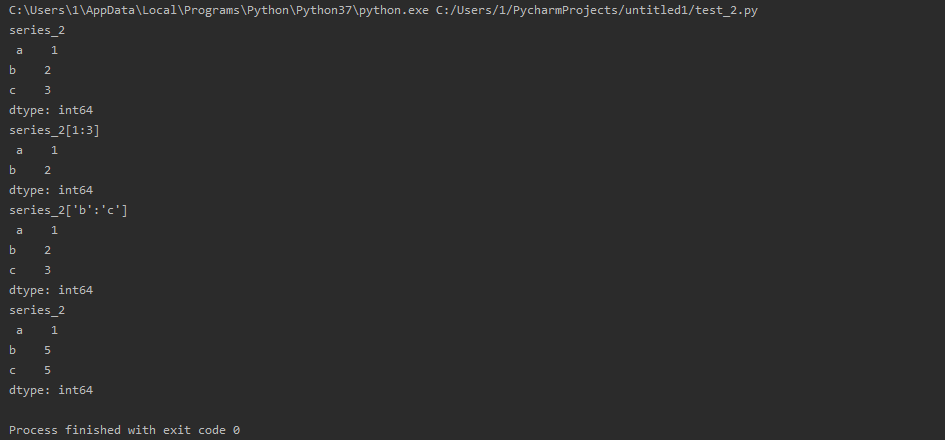
import pandas as pd series_2 = pd.Series([1, 2, 3], index=['a', 'b', 'c']) print('series_2 ', series_2) print('series_2[1:3] ', series_2[0:2]) # 不包含最后一项 print("series_2['b':'c'] ", series_2['a':'c']) # 包含最后一项 series_2['b':'c'] = 5 # 赋值操作 print('series_2 ', series_2)
3.2 整数索引
如果索引为整数,最好使用标签索引。
import pandas as pd series = pd.Series(range(5), index=range(5)) index = series[1:3] #此处未按标签切片 iloc = series.iloc[1:3] loc = series.loc[1:3] print('index ', index) print(' iloc ', iloc) print(' loc ', loc)
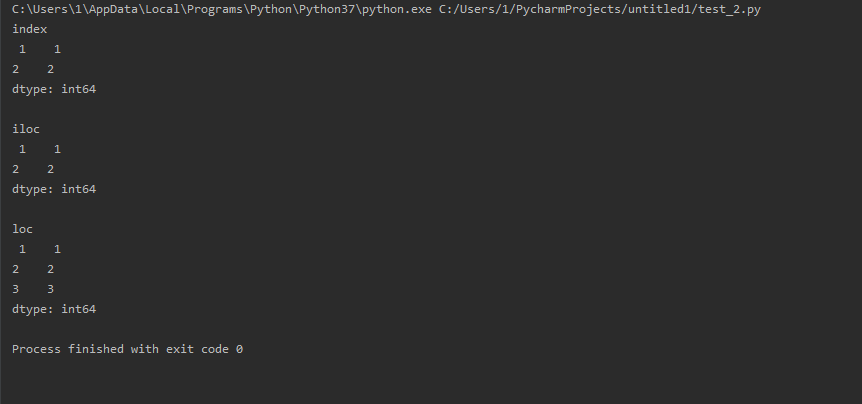
3.3 重复索引
import pandas as pd series_1 = pd.Series(range(4), index=list('aabd')) print( series_1['a']) print( series_1.index.is_unique) # 判断index是不是不重复的

四、操作
4.1 取值操作
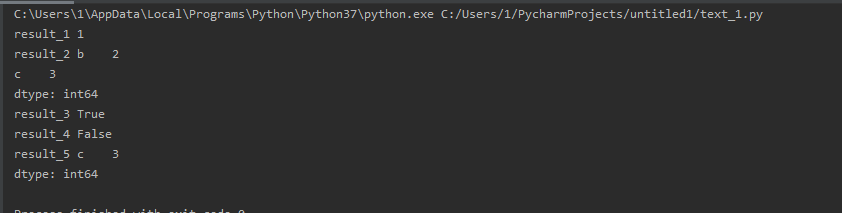
import pandas as pd series_1 = pd.Series([1, 2, 3], index=['a', 'b', 'c']) result_1 = series_1['a'] result_2 = series_1[['b', 'c']] result_3 = 'c' in series_1 result_4 = 'd' in series_1 result_5 = series_1[series_1 > 2] # 布尔类型 print('result_1', result_1) print('result_2', result_2) print('result_3', result_3) print('result_4', result_4) print('result_5', result_5)
4.2 算术操作
⾃动的数据对⻬操作在不重叠的索引处引⼊了NA值。
缺失值会在算术运算过程中传播。
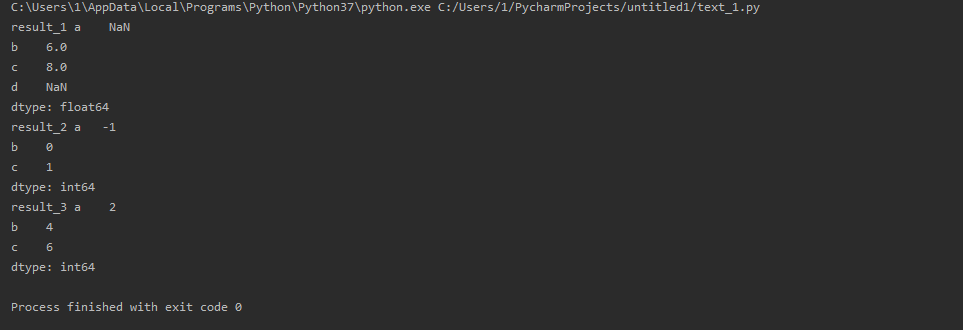
import pandas as pd series_1 = pd.Series([1, 2, 3], index=['a', 'b', 'c']) series_2 = pd.Series([4, 5, 6], index=['b', 'c', 'd']) result_1 = series_1 + series_2 result_2 = series_1 - 2 result_3 = series_1 * 2 print('result_1', result_1) print('result_2', result_2) print('result_3', result_3)
4.3 name属性
Series对象本身及其索引都有⼀个name属性,该属性跟pandas
其他的关键功能关系⾮常密切

4.4 drop 操作
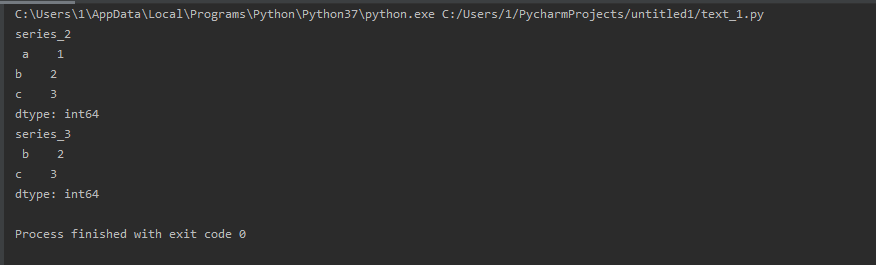
import pandas as pd series_2 = pd.Series([1, 2, 3], index=['a', 'b', 'c']) series_3 = series_2.drop('a', inplace=False) #inplace默认为False,series_2不发生改变,如果为True,则series会发生改变 print('series_2 ', series_2) print('series_3 ', series_3)
4.5 排序
import pandas as pd series_1 = pd.Series(range(4), index=list('cabd')) series_2 = series_1.sort_index() series_3 = series_1.sort_values() series_4 = series_1.reindex(list('cabdfe')).sort_values() # NaN值会直接放到最后 print('series_1 ', series_1) print(' series_2 ', series_2) print(' series_3 ', series_3) print(' series_4 ', series_4)

4.6 排名
排名会从1开始⼀直到数组中有效数据的数量;
默认情况下,rank是通过“为各组分配⼀个平均排名”的⽅式破坏平级关系的:


这⾥,条⽬0和2没有使⽤平均排名6.5,它们被设成了6和7,因为数据中标签0位于标签2的前⾯。
