1.介绍
RabbitMQ是一个消息代理 - 一个消息系统的媒介。它的工作就是接收和转发消息。你可以把他想象成一个邮局,你把信件都放到这个邮箱中,邮递员叔叔就会把信件投递到你的收件人处。只是邮箱中放的是你的信件,而我们要使用的RabbitMQ中存放的是我们的二进制数据。
下面是RabbitMQ和消息所涉及到的一些术语。
- 生产(Producing)的意思就是发送。发送消息的程序就是生产者(producer)。我们一般使用"P"表示。
- 队列(queue)就是存在于RabbitMQ中邮箱的名称。实质上队列就是一个巨大的消息缓冲区,我们同一时刻能够处理的数据有限,所以就将这些数据按照先后顺序存在这个消息队列中,我们一点点的进行处理。
- 消费(Consuming)和接收(receiving)是同一个意思。一个消费者(consumer)就是一个等待获取消息的程序。我们把它绘制为"C":
2. 作用
1)程序解耦
允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
2)冗余:
消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。
许多消息队列所采用的"插入-获取-删除"方式中,在把一个消息从队列中删除之前,需要你的处理系统明确的指出该消息已经被处理完毕,从而确保你的数据被安全的保存直到你使用完毕。
3)峰值处理能力:
使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
4)可恢复性:
系统的一部分组件失效时,不会影响到整个系统。
消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
5)顺序保证:
在大多使用场景下,数据处理的顺序都很重要。
大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。
6)缓冲:
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
7)异步通信:
消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
3.RabbitMQ的安装
Windows系统
1.RabbitMQ 它依赖于Erlang,需要先安装Erlang。
https://www.erlang.org/downloads
2.运行行Erlang/OTP(otp_win64_17.5.exe)的安装步骤,安装完成后
设置ERLANG_HOME 环境变量
在开始菜单查找Erlang,点击启动 ,如下所示证明安装成功。
注意:如果之前安装了Erlang的其他版本,需要卸载后在进行重新安装和设置。
3.进行RabbitMQ Server的下载与安装,直接运行rabbitmq-server-3.5.2.exe,选择要安装的目录,进行安装
https://www.rabbitmq.com/download.html
4.为了能够在任意Windows命令窗口上操控RabbitMQ服务需要在系统里加一个环境变量并且配置在系统的PHTH环境变量中。
5.检查RabbitMQ是否运行正常,打开终端,进入RabbitMQ的安装目录rabbitmq_server-3.5.2sbin,输入rabbitmqctl status,如果出现以下的图,说明安装是成功的,并且说明现在RabbitMQ Server已经启动了,运行正常。
6.安装rabbitmq_management插件,这款插件是可以可视化的方式查看RabbitMQ 服务器实例的状态,以及操控RabbitMQ服务器。
rabbitmq-plugins enable rabbitmq_management现在我们在浏览器中输入:http://localhost:15672 可以看到一个登录界面:

这里可以使用默认账号guest/guest登录
linux系统下安装


1 rabbitmq-server服务端 2 3 1.下载centos源,方便使用yum安装软件 4 wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.cloud.tencent.com/repo/centos7_base.repo 5 2.下载epel源,安装完成之后你就可以直接使用yum来安装额外的软件包了 6 wget -O /etc/yum.repos.d/epel.repo http://mirrors.cloud.tencent.com/repo/epel-7.repo 7 3.清空yum缓存并且生成新的yum缓存 8 yum clean all 9 yum makecache 10 4.安装erlang 11 $ yum -y install erlang 12 5.安装RabbitMQ 13 $ yum -y install rabbitmq-server 14 6.启动(无用户名密码): 15 systemctl start/stop/restart/status rabbitmq-server 16 # 设置新用户xiaoqi 密码123 17 sudo rabbitmqctl add_user xiaoqi 123 18 # 设置用户为administrator角色 19 sudo rabbitmqctl set_user_tags xiaoqi administrator 20 # 设置权限,允许对所有的队列都有权限 21 对何种资源具有配置、写、读的权限通过正则表达式来匹配,具体命令如下: 22 set_permissions [-p <vhostpath>] <user> <conf> <write> <read> 23 sudo rabbitmqctl set_permissions -p "/" xiaoqi ".*" ".*" ".*" 24 # 停止/重启服务 25 service rabbitmq-server start/stop/restart
rabbitmq相关命令
1 # 设置rabbitmq账号密码,以及角色权限设置 2 # 设置新用户xiaoqi 密码123 3 rabbitmqctl add_user xiaoqi 123 4 # 设置用户为administrator角色 5 rabbitmqctl set_user_tags xiaoqi administrator 6 # 设置权限,允许对所有的队列都有权限 7 对何种资源具有配置、写、读的权限通过正则表达式来匹配,具体命令如下: 8 set_permissions [-p <vhostpath>] <user> <conf> <write> <read> 9 rabbitmqctl set_permissions -p "/" xiaoqi ".*" ".*" ".*" 10 # 停止rabbitmq 11 rabbitmqctl stop 12 # 重启服务生效设置 13 rabbitmq-server restart 14 rabbitmq相关命令 15 // 新建用户 16 rabbitmqctl add_user {用户名} {密码} 17 // 设置权限 18 rabbitmqctl set_user_tags {用户名} {权限} 19 // 查看用户列表 20 rabbitmqctl list_users 21 // 为用户授权 22 添加 Virtual Hosts : 23 rabbitmqctl add_vhost <vhost> 24 // 删除用户 25 rabbitmqctl delete_user Username 26 // 修改用户的密码 27 rabbitmqctl change_password Username Newpassword 28 // 删除 Virtual Hosts : 29 rabbitmqctl delete_vhost <vhost> 30 // 添加 Users : 31 rabbitmqctl add_user <username> <password> 32 rabbitmqctl set_user_tags <username> <tag> ... 33 rabbitmqctl set_permissions [-p <vhost>] <user> <conf> <write> <read> 34 // 删除 Users : 35 delete_user <username> 36 // 使用户user1具有vhost1这个virtual host中所有资源的配置、写、读权限以便管理其中的资源 37 rabbitmqctl set_permissions -p vhost1 user1 '.*' '.*' '.*' 38 // 查看权限 39 rabbitmqctl list_user_permissions user1 40 rabbitmqctl list_permissions -p vhost1 41 // 清除权限 42 rabbitmqctl clear_permissions [-p VHostPath] User 43 //清空队列步骤 44 rabbitmqctl reset 45 需要提前关闭应用rabbitmqctl stop_app , 46 然后再清空队列,启动应用 47 rabbitmqctl start_app 48 此时查看队列rabbitmqctl list_queues 49 50 查看所有的exchange:rabbitmqctl list_exchanges 51 查看所有的queue:rabbitmqctl list_queues 52 查看所有的用户: rabbitmqctl list_users 53 查看所有的绑定(exchange和queue的绑定信息):rabbitmqctl list_bindings 54 查看消息确认信息:rabbitmqctl list_queues name messages_ready messages_unacknowledged 55 查看RabbitMQ状态,包括版本号等信息:rabbitmqctl status 56 57 #下列命令安装rabbitmq_management插件,这款插件是可以可视化的方式查看RabbitMQ 服务器实例的状态,以及操控RabbitMQ服务器。 58 rabbitmq-plugins enable rabbitmq_management 59 60 #访问web界面 61 http://server-name:15672/ 62 63 # 在浏览器中输入 http://localhost:15672/api/ 就可以看到 RabbitMQ Management HTTP API 文档
RabbitMQ使用的是AMQP协议。这是一个用于消息传递的开放、通用的协议。针对不同编程语言有大量的RabbitMQ客户端可用。
4. 什么是AMQP?
5. 消息代理和他们所扮演的角色?
消息代理(message brokers)从发布者(publishers)亦称生产者(producers)那儿接收消息,并根据既定的路由规则把接收到的消息发送给处理消息的消费者(consumers)。
由于AMQP是一个网络协议,所以这个过程中的发布者,消费者,消息代理 可以存在于不同的设备上。
AMQP AMQP协议是一个高级抽象层消息通信协议,RabbitMQ是AMQP协议的实现。它主要包括以下组件: 1.Server(broker): 接受客户端连接,实现AMQP消息队列和路由功能的进程。 2.Virtual Host:其实是一个虚拟概念,类似于权限控制组,一个Virtual Host里面可以有若干个Exchange和Queue,但是权限控制的最小粒度是Virtual Host 3.Exchange:交换机,接受生产者发送的消息,并根据Binding规则将消息路由给服务器中的队列。ExchangeType决定了Exchange路由消息的行为,在RabbitMQ中,ExchangeType有direct、Fanout和Topic三种,不同类型的Exchange路由的行为是不一样的。 - Direct直连交换机 特点:依据key进行投递 例如绑定时设置了routing key为”hello”,那么客户端提交的消息,只有设置了key为”hello”的才会投递到队列。 - Topic主题交换机 特点:对key模式匹配后进行投递,符号”#”匹配一个或多个词,符号”*”匹配一个词 例如”abc.#”匹配”abc.def.ghi”,”abc.*”只匹配”abc.def”。 - Fanout扇型交换机 特点:不需要key,采取广播模式,一个消息进来时,投递到与该交换机绑定的所有队列 4.Message Queue:消息队列,用于存储还未被消费者消费的消息。 5.Message: 由Header和Body组成,Header是由生产者添加的各种属性的集合,包括Message是否被持久化、由哪个Message Queue接受、优先级是多少等。而Body是真正需要传输的APP数据。 6.Binding:Binding联系了Exchange与Message Queue。Exchange在与多个Message Queue发生Binding后会生成一张路由表,路由表中存储着Message Queue所需消息的限制条件即Binding Key。当Exchange收到Message时会解析其Header得到Routing Key,Exchange根据Routing Key与Exchange Type将Message路由到Message Queue。Binding Key由Consumer在Binding Exchange与Message Queue时指定,而Routing Key由Producer发送Message时指定,两者的匹配方式由Exchange Type决定。 7.Connection:连接,对于RabbitMQ而言,其实就是一个位于客户端和Broker之间的TCP连接。 8.Channel:信道,仅仅创建了客户端到Broker之间的连接后,客户端还是不能发送消息的。需要为每一个Connection创建Channel,AMQP协议规定只有通过Channel才能执行AMQP的命令。一个Connection可以包含多个Channel。之所以需要Channel,是因为TCP连接的建立和释放都是十分昂贵的,如果一个客户端每一个线程都需要与Broker交互,如果每一个线程都建立一个TCP连接,暂且不考虑TCP连接是否浪费,就算操作系统也无法承受每秒建立如此多的TCP连接。RabbitMQ建议客户端线程之间不要共用Channel,至少要保证共用Channel的线程发送消息必须是串行的,但是建议尽量共用Connection。 9.Command:AMQP的命令,客户端通过Command完成与AMQP服务器的交互来实现自身的逻辑。例如在RabbitMQ中,客户端可以通过publish命令发送消息,txSelect开启一个事务,txCommit提交一个事务。
6.python中使用RabbitMQ
需要先进行模块安装
# rabbitmq官方推荐的python客户端pika模块 pip3 install pika
简单的收发程序,即单发送单接收
发送方send.py
1 import pika 2 3 # 创建凭证,使用rabbitmq用户密码登录 4 # 使用前,必须得验证身份 5 credentials = pika.PlainCredentials("guest","guest") 6 # 建立一个到RabbitMQ服务器的连接。 7 connection = pika.BlockingConnection(pika.ConnectionParameters('localhost',credentials=credentials)) 8 channel = connection.channel() 9 10 # 创建一个名为"q1"的队列用来投递消息 11 channel.queue_declare(queue='q1') 12 # 注意在rabbitmq中,消息想要发送给队列,必须经过交换(exchange),初学可以使用空字符串交换(exchange=''), 13 # 它允许我们精确的指定发送给哪个队列(routing_key=''),参数body值发送的数据 14 channel.basic_publish(exchange='',routing_key='q1',body='很高兴见到你') 15 16 print("已经发送了消息") 17 # 程序退出前,确保刷新网络缓冲以及消息发送给rabbitmq,需要关闭本次连接 18 connection.close()
接收方receive.py
1 import pika 2 # 创建凭证,使用rabbitmq用户密码登录 3 # 使用前,必须得验证身份 4 credentials = pika.PlainCredentials("guest","guest") 5 # 建立一个到RabbitMQ服务器的连接。 6 connection = pika.BlockingConnection(pika.ConnectionParameters('localhost',credentials=credentials)) 7 channel = connection.channel() 8 # 创建一个名为"q1"的队列用来投递消息 9 channel.queue_declare(queue='q1') 10 11 def callbak(ch,method,properties,body): 12 print("消费者接收到了任务:%r"%body.decode("utf8")) 13 # 有消息来临,立即执行callbak,没有消息则夯住,等待消息 14 # 消息来了,立即去取,队列名字为q1 15 channel.basic_consume(queue='q1', on_message_callback=callbak, auto_ack=True) 16 # 开始消费,接收消息 17 channel.start_consuming()
你也许要问: 为什么要在接收方和发送方重复声明队列呢 —— 我们已经在前面的代码中声明过它了。如果我们确定了队列是已经存在的,那么我们可以不这么做,比如此前预先运行了send.py程序。可是我们并不确定哪个程序会首先运行。这种情况下,在程序中重复将队列重复声明一下是种值得推荐的做法。
工作队列,即单发送多接收
我们将创建一个工作队列(Work Queue),工作队列(又称:任务队列——Task Queues),它会发送一些耗时的任务给多个工作者(Worker)。为了避免等待一些占用大量资源、时间的操作。当我们把任务(Task)当作消息发送到队列中,一个运行在后台的工作者(worker)进程就会取出任务然后处理。当你运行多个工作者(workers),任务就会在它们之间共享。
发送方sender.py1 # 修改代码 2 import sys 3 message = ' '.join(sys.argv[1:]) or "很高兴见到你" 4 channel.basic_publish(exchange='',routing_key='q1',body=message) 5 print(" [x] Sent %r" % (message,))
接收方receiver1.py和receiver2.py
1 # 修改代码 2 import time 3 def callbak(ch,method,properties,body): 4 print("[x] Received %r"%body.decode("utf8")) 5 time.sleep(body.decode("utf8").count('.')) 6 print(" [x] Done")
我们将receiver1.py和receiver2.py开启,会夯住等待接收消息。
sender.py用来发布新任务,终端执行。
1 python sender.py First message. 2 python sender.py Second message.. 3 python sender.py Third message... 4 python sender.py Fourth message.... 5 python sender.py Fifth message.....
默认来说,RabbitMQ会按顺序得把消息发送给每个消费者(consumer)。平均每个消费者都会收到同等数量得消息。这种发送消息得方式叫做——轮询(round-robin)。如果添加三个消费者则会出现丢失数据的问题。
7.M消息确认ack
为了防止消息丢失,RabbitMQ提供了消息响应(acknowledgments)。消费者会通过一个ack(响应),告诉RabbitMQ已经收到并处理了某条消息,然后RabbitMQ就会释放并删除这条消息。
如果消费者(consumer)挂掉了,没有发送响应,RabbitMQ就会认为消息没有被完全处理,然后重新发送给其他消费者(consumer)。这样,及时工作者(workers)偶尔的挂掉,也不会丢失消息。
消息响应默认是开启的。之前的例子中我们可以使用no_ack=True标识把它关闭。是时候移除这个标识了,当工作者(worker)完成了任务,就发送一个响应。
生产者,发布任务。sender.py
1 import pika 2 import sys 3 # 创建凭证,使用rabbitmq用户密码登录 4 # 使用前,必须得验证身份 5 credentials = pika.PlainCredentials("guest","guest") 6 # 建立一个到RabbitMQ服务器的连接。 7 connection = pika.BlockingConnection(pika.ConnectionParameters('localhost',credentials=credentials)) 8 channel = connection.channel() 9 10 # 创建一个名为"q1"的队列用来投递消息 11 channel.queue_declare(queue='q1') 12 message = ' '.join(sys.argv[1:]) or "很高兴见到你" 13 # 注意在rabbitmq中,消息想要发送给队列,必须经过交换(exchange),初学可以使用空字符串交换(exchange=''), 14 # 它允许我们精确的指定发送给哪个队列(routing_key=''),参数body值发送的数据 15 channel.basic_publish(exchange='',routing_key='q1',body=message) 16 print(" [x] Sent %r" % (message,)) 17 # 程序退出前,确保刷新网络缓冲以及消息发送给rabbitmq,需要关闭本次连接 18 connection.close()
消费者,receiver.py
1 import time 2 import pika 3 # 创建凭证,使用rabbitmq用户密码登录 4 # 使用前,必须得验证身份 5 credentials = pika.PlainCredentials("guest","guest") 6 # 建立一个到RabbitMQ服务器的连接。 7 connection = pika.BlockingConnection(pika.ConnectionParameters('localhost',credentials=credentials)) 8 channel = connection.channel() 9 # 创建一个名为"q1"的队列用来投递消息 10 channel.queue_declare(queue='q1') 11 12 def callbak(ch,method,properties,body): 13 print("[x] Received %r"%body.decode("utf8")) 14 time.sleep(body.decode("utf8").count('.')) 15 print(" [x] Done") 16 # 消息确认 17 ch.basic_ack(delivery_tag=method.delivery_tag) 18 19 # 有消息来临,立即执行callbak,没有消息则夯住,等待消息 20 # 消息来了,立即去取,队列名字为q1 21 channel.basic_consume(queue='q1', on_message_callback=callbak) 22 # 开始消费,接收消息 23 channel.start_consuming()
将多个receiver.py启动,然后按如下方式在终端启动sender.py
python sender.py First message.
python sender.py Second message..
python sender.py Third message...
python sender.py Fourth message....
python sender.py Fifth message.....
我们会发现现在没有消息丢失,全部被消费者接收。
忘记确认
一个很容易犯的错误就是忘了basic_ack,后果很严重。消息在你的程序退出之后就会重新发送,如果它不能够释放没响应的消息,RabbitMQ就会占用越来越多的内存。
为了排除这种错误,你可以使用rabbitmqctl命令,输出messages_unacknowledged字段:
1 E:myrabbitmq>rabbitmqctl list_queues name messages_ready messages_unacknowledged 2 Timeout: 60.0 seconds ... 3 Listing queues for vhost / ... 4 xiaoqi 0 0 5 q1 0 0
8.消息持久化
如果你没有特意告诉RabbitMQ,那么在它退出或者崩溃的时候,将会丢失所有队列和消息。为了确保信息不会丢失,有两个事情是需要注意的:我们必须把“队列”和“消息”设为持久化。
队列持久化:如果两个队列,a1队列没有做队列持久化,a2队列做了队列持久化,那么重启后a1队列消失,a2队列依然存在,可通过命令rabbitmqctl list_queues查看
消息持久化:还是两个队列,a2队列做了队列持久化,a3做了队列持久化和消息持久化,那么重启后a2和a3队列都存在,但是a2中的数据丢失,a3中的数据依然存在。
首先,为了不让队列消失,需要把队列声明为持久化(durable):
1 channel.queue_declare(queue='q1', durable=True) # 虽然代码正确,但是会报错。
尽管这行代码本身是正确的,但是仍然不会正确运行。因为我们已经定义过一个叫q1的非持久化队列。RabbitMq不允许你使用不同的参数重新定义一个队列,它会返回一个错误。但我们现在使用一个快捷的解决方法——用不同的名字,例如task_queue。
channel.queue_declare(queue='task_queue', durable=True)
这时候,我们就可以确保在RabbitMq重启之后queue_declare队列不会丢失。
另外,我们需要把我们的消息也要设为持久化——将delivery_mode的属性设为2。
channel.basic_publish( exchange='', routing_key="task_queue", body=message, # delivery_mode = 2 使消息持久化 properties=pika.BasicProperties(delivery_mode = 2,) )
注意:消息持久化
将消息设为持久化并不能完全保证不会丢失。以上代码只是告诉了RabbitMq要把消息存到硬盘,但从RabbitMq收到消息到保存之间还是有一个很小的间隔时间。因为RabbitMq并不是所有的消息都使用fsync(2)(同步)——它有可能只是保存到缓存中,并不一定会写到硬盘中。并不能保证真正的持久化,但已经足够应付我们的简单工作队列。如果你一定要保证持久化,你需要改写你的代码来支持事务(transaction)。
9.公平调度
你应该已经发现,它仍旧没有按照我们期望的那样进行分发。比如有两个工作者(workers),处理奇数消息的比较繁忙,处理偶数消息的比较轻松。然而RabbitMQ并不知道这些,它仍然一如既往的派发消息。
这时因为RabbitMQ只管分发进入队列的消息,不会关心有多少消费者(consumer)没有作出响应。它盲目的把第n-th条消息发给第n-th个消费者。
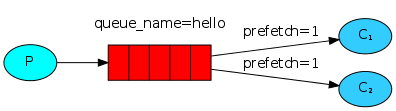
我们可以使用basic.qos方法,并设置prefetch_count=1。这样是告诉RabbitMQ,再同一时刻,不要发送超过1条消息给一个工作者(worker),直到它已经处理了上一条消息并且作出了响应。这样,RabbitMQ就会把消息分发给下一个空闲的工作者(worker)。
channel.basic_qos(prefetch_count=1)
关于队列大小
如果所有的工作者都处理繁忙状态,你的队列就会被填满。你需要留意这个问题,要么添加更多的工作者(workers),要么使用其他策略。
10.工作队列代码整合
sender.py
1 import pika 2 import sys 3 4 # 创建凭证,使用rabbitmq用户密码登录 5 # 使用前,必须得验证身份 6 credentials = pika.PlainCredentials("guest", "guest") 7 # 建立一个到RabbitMQ服务器的连接。 8 connection = pika.BlockingConnection(pika.ConnectionParameters('localhost', credentials=credentials)) 9 channel = connection.channel() 10 11 # 创建一个名为"task1"的队列用来投递消息,durable=True队列持久化 12 channel.queue_declare(queue='task1', durable=True) 13 # 注意在rabbitmq中,消息想要发送给队列,必须经过交换(exchange),初学可以使用空字符串交换(exchange=''), 14 # 它允许我们精确的指定发送给哪个队列(routing_key=''),参数body值发送的数据 15 message = ' '.join(sys.argv[1:]) or "很高兴见到你" 16 # 发送消息到指定的路由和路由键 17 channel.basic_publish( 18 exchange='', 19 routing_key='task1', 20 body=message, 21 # 消息持久化 22 properties=pika.BasicProperties(delivery_mode=2) 23 ) 24 print(" [x] Sent %r" % (message,)) 25 # 程序退出前,确保刷新网络缓冲以及消息发送给rabbitmq,需要关闭本次连接 26 connection.close()
receiver.py
1 import time 2 3 import pika 4 # 创建凭证,使用rabbitmq用户密码登录 5 # 使用前,必须得验证身份 6 credentials = pika.PlainCredentials("guest","guest") 7 # 建立一个到RabbitMQ服务器的连接。 8 connection = pika.BlockingConnection(pika.ConnectionParameters('localhost',credentials=credentials)) 9 channel = connection.channel() 10 # 创建一个名为"task1"的队列用来投递消息 11 channel.queue_declare(queue='task1',durable=True) 12 13 def callbak(ch,method,properties,body): 14 print("[x] Received %r"%body.decode("utf8")) 15 time.sleep(body.decode("utf8").count('.')) 16 print(" [x] Done") 17 # 消息确认 18 ch.basic_ack(delivery_tag=method.delivery_tag) 19 20 # 只处理一条数据,作出响应后再处理下一条 21 channel.basic_qos(prefetch_count=1) 22 # 有消息来临,立即执行callbak,没有消息则夯住,等待消息 23 # 消息来了,立即去取,队列名字为task1 24 channel.basic_consume(queue='task1', on_message_callback=callbak) 25 # 开始消费,接收消息 26 channel.start_consuming()
注:会发现此时消息是谁有时间谁去处理,而不是轮询分配的方式。
11.exchange交换机
前面的学习只搭建了一个工作队列,每个任务只分发给一个工作者(worker),如果有些任务需要多个工作者都能够拿到,那么就需要使用到exchange。一个消息给到多个消费者,这种模式叫"发布/订阅"
RabbitMQ消息模型的核心理念是:发布者(producer)不会直接发送任何消息给队列。而是将消息发送给交换机,由交换机发送给队列。

exchange的四种模式
fanout Exchange
扇形交换机是最基本的交换机类型,它所能做的事情非常简单———广播消息。扇形交换机会把能接收到的消息全部发送给绑定在自己身上的队列。因为广播不需要“思考”,所以扇形交换机处理消息的速度也是所有的交换机类型里面最快的。
direct Exchange
直连交换机是一种带路由功能的交换机,一个队列会和一个交换机绑定,除此之外再绑定一个routing_key,当消息被发送的时候,需要指定一个binding_key,这个消息被送达交换机的时候,就会被这个交换机送到指定的队列里面去。同样的一个binding_key也是支持应用到多个队列中的。这样当一个交换机绑定多个队列,就会被送到对应的队列去处理。
topic Exchange
主题交换机是一种支持正则匹配的exchange,发送到topic exchange上的消息需要携带指定规则的routing_key,主题交换机会根据这个规则将数据发送到对应的(多个)队列上。该exchange的routing_key需要有一定的规则,交换机和队列的binding_key需要采用.#......的格式,每个部分用.分开,其中:*表示一个单词,#表示任意数量(零个或多个)单词。
headers Exchange
头交换机是忽略routing_key的一种路由方式。路由器和交换机路由的规则是通过Headers信息来交换的,这个有点像HTTP的Headers。将一个exchange声明成Headers exchange,绑定一个队列的时候,定义一个Hash的数据结构,消息发送的时候,会携带一组hash数据结构的信息,当Hash的内容匹配上的时候,消息就会被写入队列。绑定exchange和队列的时候,Hash结构中要求携带一个键“x-match”,这个键的Value可以是any或者all,这代表消息携带的Hash是需要全部匹配(all),还是仅匹配一个键(any)就可以了。相比direct exchange,首部交换机的优势是匹配的规则不被限定为字符串(string)。
channel.exchange_declare(exchange='logs', exchange_type='fanout')
匿名的交换器
前面我们对交换机一无所知,但仍然能够发送消息到队列中。因为我们使用了命名为空字符串("")默认的交换机。
回想我们之前是如何发布一则消息:
channel.basic_publish(exchange='', routing_key='hello', body=message)
exchange参数就是交换机的名称。空字符串代表默认或者匿名交换机:消息将会根据指定的routing_key分发到指定的队列。
现在,我们就可以发送消息到一个具名交换机了:
channel.basic_publish(exchange='logs', routing_key='', body=message)
临时队列
临时队列手动创建一个随机的队列名,或者让服务器为我们选择一个随机的队列名(推荐)。只需要在调用queue_declare方法的时候,不提供queue参数的值就可以了:
result = channel.queue_declare(queue="")
我们可以通过result.method.queue获得已经生成的随机队列名。它可能是这样子的:amq.gen-U0srCoW8TsaXjNh73pnVAw==。
result.method.queue
当与消费者(consumer)断开连接的时候,这个队列应当被立即删除。exclusive标识符即可达到此目的。
result = channel.queue_declare(queue="",exclusive=True) # 断开连接,队列立即删除
绑定(bindings)
已经创建了一个扇型交换机(fanout)和一个队列。现在我们需要告诉交换机如何发送消息给我们的队列。交换器和队列之间的联系我们称之为绑定(binding)。
channel.queue_bind(exchange='logs', queue=result.method.queue)
你可以使用rabbitmqctl list_bindings 列出所有现存的绑定。
发布/订阅和简单的消息队列区别在于,发布订阅会将消息发送给所有的订阅者,而消息队列中的数据被消费一次便消失。所以,RabbitMQ实现发布和订阅时,会为每一个订阅者创建一个队列,而发布者发布消息时,会将消息放置在所有相关队列中。
扇形交换机(fanout)
如:日志文件。
sender.py
import pika import sys # 创建凭证,使用rabbitmq用户密码登录 credentials = pika.PlainCredentials("guest", "guest") # 创建一个rabbitmq连接 connection = pika.BlockingConnection(pika.ConnectionParameters('localhost', credentials=credentials)) channel = connection.channel() # 指定交换机类型 channel.exchange_declare(exchange='m1',exchange_type='fanout') message = ' '.join(sys.argv[1:]) or "很高兴见到你" # 指定发送给哪个交换机(exchange='')路由键(routing_key=''),参数body值发送的数据 channel.basic_publish( exchange='m1', routing_key='', body=message, ) print(" [x] Sent %r" % (message,)) connection.close()
receiver.py
import time import pika credentials = pika.PlainCredentials("guest", "guest") connection = pika.BlockingConnection(pika.ConnectionParameters('localhost', credentials=credentials)) channel = connection.channel() channel.exchange_declare(exchange='m1', exchange_type='fanout') # 随机创建一个队列,扇形交换机要将消息给所有人,所以不需要特意指定一个队列的名称。 result = channel.queue_declare(queue="", exclusive=True) # 获取队列的名字 queue_name = result.method.queue # 创建绑定,交换机和队列 channel.queue_bind(exchange='m1', queue=queue_name) def callbak(ch, method, properties, body): print("[x] Received %r" % body.decode("utf8")) time.sleep(body.decode("utf8").count('.')) print(" [x] Done") channel.basic_consume(queue=queue_name, on_message_callback=callbak, auto_ack=True) # 开始消费,接收消息 channel.start_consuming()
这样我们就完成了。如果你想把结果保存到日志文件中,只需要打开控制台输入:
python receiver.py > logs_from_rabbit.log # 使用该方式启动receiver.py
直连交换机
绑定(binding)是指交换机(exchange)和队列(queue)的关系。可以简单理解为:这个队列(queue)对这个交换机(exchange)的消息感兴趣。
绑定的时候可以带上一个额外的routing_key参数。为了避免与basic_publish的参数混淆,我们把它叫做绑定键(binding key)。以下是如何创建一个带绑定键的绑定。
channel.queue_bind(exchange=exchange_name, queue=queue_name, routing_key='black')
直连交换机(direct exchange)将会对绑定键(binding key)和路由键(routing key)进行精确匹配,从而确定消息该分发到哪个队列。绑定的都是同一个路由,通过路由键来区分是谁处理任务。
比如:有三个任务,分别分配给三个人,任务1-->p1、任务2-->p2、任务3-->p3,你是一个任务发布者,说我想要任务1的结果了,对应的就是p1给你答案,想要任务2的结果了,对应的就是p2给你答案。
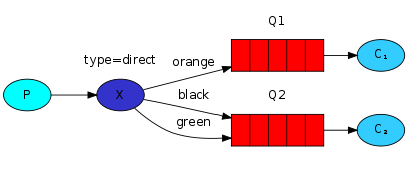
如上图所示:直连交换机绑定了Q1和Q2两个队列,第一个队列使用orange作为绑定键,第二个队列使用black和green作为绑定键,当路由键为orange时会被路由到Q1这个队列。为black或green时会被路由到Q2这个队列。
多个绑定(Multiple bindings)
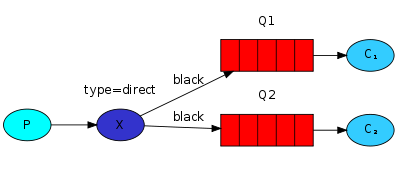
多个队列使用相同的绑定键是合法的。这个例子中,我们可以添加一个X和Q1之间的绑定,使用black绑定键。这样一来,直连交换机就和扇型交换机的行为一样,会将消息广播到所有匹配的队列。带有black路由键的消息会同时发送到Q1和Q2。
sender.py
import pika routing_key=input("请输入routing_key:") credentials = pika.PlainCredentials("guest", "guest") connection = pika.BlockingConnection(pika.ConnectionParameters('localhost', credentials=credentials)) channel = connection.channel() # 指定直连交换机 channel.exchange_declare(exchange='task1',exchange_type='direct') message = f"很高兴见到你{routing_key}" channel.basic_publish( exchange='task1', routing_key=routing_key, body=message, ) print(f"给{routing_key}发送消息成功") connection.close()
receiver1.py
import time import pika credentials = pika.PlainCredentials("guest", "guest") connection = pika.BlockingConnection(pika.ConnectionParameters('localhost', credentials=credentials)) channel = connection.channel() channel.exchange_declare(exchange='task1', exchange_type='direct') # 随机创建一个队列 result = channel.queue_declare(queue="", exclusive=True) # 获取队列的名字 queue_name = result.method.queue # 绑定交换机和队列 channel.queue_bind(exchange='task1', queue=queue_name, routing_key="xiaoqi") def callbak(ch, method, properties, body): print(body.decode("utf8")) channel.basic_consume(queue=queue_name, on_message_callback=callbak, auto_ack=True) # 开始消费,接收消息 channel.start_consuming()
receiver2.py
import time import pika credentials = pika.PlainCredentials("guest", "guest") connection = pika.BlockingConnection(pika.ConnectionParameters('localhost', credentials=credentials)) channel = connection.channel() channel.exchange_declare(exchange='task1', exchange_type='direct') # 随机创建一个队列 result = channel.queue_declare(queue="", exclusive=True) # 获取队列的名字 queue_name = result.method.queue # 绑定交换机和队列 channel.queue_bind(exchange='task1', queue=queue_name, routing_key="dada") def callbak(ch, method, properties, body): print(body.decode("utf8")) channel.basic_consume(queue=queue_name, on_message_callback=callbak, auto_ack=True) # 开始消费,接收消息 channel.start_consuming()
应用场景:可以是错误日志,不同日志保存到不同的文件。
如果你希望只是保存warning和error级别的日志到磁盘,只需要打开控制台并输入:
python receive_logs_direct.py warning error > logs_from_rabbit.log # 此方式开启receiver
主题交换机
发送到主题交换机(topic exchange)的消息不可以携带随意什么样子的路由键(routing_key),它的路由键必须是一个由.分隔开的词语列表。词语的个数可以随意,但是不要超过255字节。
* (星号) 用来表示一个单词.
# (井号) 用来表示任意数量(零个或多个)单词。
主题交换机是很强大的,它可以表现出跟其他交换机类似的行为
-
当一个队列的绑定键为 "#"(井号) 的时候,这个队列将会无视消息的路由键,接收所有的消息。
-
当
*(星号) 和#(井号) 这两个特殊字符都未在绑定键中出现的时候,此时主题交换机就拥有的直连交换机的行为。
sender.py
import pika routing_key=input("请输入routing_key:") credentials = pika.PlainCredentials("guest", "guest") connection = pika.BlockingConnection(pika.ConnectionParameters('localhost', credentials=credentials)) channel = connection.channel() # 指定直连交换机 channel.exchange_declare(exchange='task2',exchange_type='topic') message = f"很高兴见到你{routing_key}" channel.basic_publish( exchange='task2', routing_key=routing_key, body=message, ) print(f"给{routing_key}发送消息成功") connection.close()
receiver.py
import time import pika credentials = pika.PlainCredentials("guest", "guest") connection = pika.BlockingConnection(pika.ConnectionParameters('localhost', credentials=credentials)) channel = connection.channel() channel.exchange_declare(exchange='task2', exchange_type='topic') # 随机创建一个队列 result = channel.queue_declare(queue="", exclusive=True) # 获取队列的名字 queue_name = result.method.queue # 绑定交换机和队列 channel.queue_bind(exchange='task2', queue=queue_name, routing_key="*.md") def callbak(ch, method, properties, body): print(body.decode("utf8")) # 有消息来临,立即执行callbak,从队列q1中取数据;没有消息则夯住,等待消息 channel.basic_consume(queue=queue_name, on_message_callback=callbak, auto_ack=True) # 开始消费,接收消息 channel.start_consuming()
官方文档:http://rabbitmq.mr-ping.com/tutorials_with_python/[5]Topics.html
12.RPC远程过程调用
RPC远程过程调用,在计算机A上的进程,调用另外一台计算机B的进程,A上的进程被挂起,B上的被调用进程开始执行后,产生返回值给A,A继续执行。它是一个计算机通信协议。
RPC的关键不在于它是什么通信协议,重点在于可以通过RPC进行解耦服务。
应用:
一个电商的下单过程,涉及物流、支付、库存、红包等多个系统,多个系统又在多个服务器上,由不同的技术团队负责,整个下单过程,需要所有团队进行远程调用。
下单 { 库存>减少库存
支付>扣款
红包>减免红包
物流>生成订单}
python实现RPC
利用RabbitMQ构建一个RPC系统,包含了客户端和RPC服务器,依旧使用pika模块
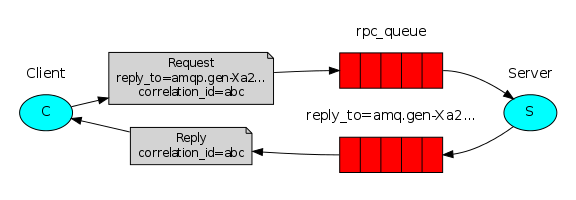
Callback queue 回调队列
一个客户端向服务器发送请求,服务器端处理请求后,将其处理结果保存在一个存储体中。而客户端为了获得处理结果,那么客户在向服务器发送请求时,同时发送一个回调队列地址reply_to。
result = channel.queue_declare(queue="",exclusive=True) callback_queue = result.method.queue channel.basic_publish(exchange='', routing_key='rpc_queue', properties=pika.BasicProperties( reply_to = callback_queue, ), body=request)
Correlation id 关联标识
一个客户端可能会发送多个请求给服务器,当服务器处理完后,客户端无法辨别在回调队列中的响应具体和那个请求时对应的。为了处理这种情况,客户端在发送每个请求时,同时会附带一个独有correlation_id属性,这样客户端在回调队列中根据correlation_id字段的值就可以分辨此响应属于哪个请求。
客户端发送请求:某个应用将请求信息交给客户端,然后客户端发送RPC请求,在发送RPC请求到RPC请求队列时,客户端至少发送带有reply_to以及correlation_id两个属性的信息。
服务器端工作流: 等待接受客户端发来RPC请求,当请求出现的时候,服务器从RPC请求队列中取出请求,然后处理后,将响应发送到reply_to指定的回调队列中。
客户端接受处理结果: 客户端等待回调队列中出现响应,当响应出现时,它会根据响应中correlation_id字段的值,将其返回给对应的应用。
client.py
import pika import uuid class FibonacciRpcClient(object): def __init__(self): credentials = pika.PlainCredentials("guest", "guest") # 客户端启动时,创建回调队列,会开启会话用于发送RPC请求以及接受响应 # 建立连接,指定服务器的ip地址 self.connection = pika.BlockingConnection( pika.ConnectionParameters(host='localhost', credentials=credentials)) # 建立一个会话,每个channel代表一个会话任务 self.channel = self.connection.channel() # 声明回调队列,再次声明的原因是,服务器和客户端可能先后开启,该声明是幂等的,多次声明,但只生效一次 # exclusive=True 参数是指只对首次声明它的连接可见 # exclusive=True 会在连接断开的时候,自动删除 result = self.channel.queue_declare(queue="", exclusive=True) # 将次队列指定为当前客户端的回调队列,用户接收服务端给客户端发送的信息 self.callback_queue = result.method.queue # 客户端订阅回调队列,当回调队列中有响应时,调用`on_response`方法对响应进行处理; # 有消息来临,立即执行callbak,从队列on_response中取数据;没有消息则夯住,等待消息 self.channel.basic_consume(queue=self.callback_queue, on_message_callback=self.on_response, auto_ack=True) # 对回调队列中的响应进行处理的函数 def on_response(self, ch, method, props, body): if self.corr_id == props.correlation_id: self.response = body # 发出RPC请求 # 例如这里服务端就是一场马拉松,跑完一段将棒交给下一个人,这个过程是发送rpc请求 def call(self, n): # 初始化 response self.response = None # 生成correlation_id 关联标识,通过python的uuid库,生成全局唯一标识ID,保证时间空间唯一性 self.corr_id = str(uuid.uuid4()) # 发送RPC请求内容到RPC请求队列`task2`,同时发送的还有`reply_to`和`correlation_id` self.channel.basic_publish(exchange='', routing_key='main_queue', properties=pika.BasicProperties( reply_to=self.callback_queue, correlation_id=self.corr_id, ), body=str(n)) while self.response is None: self.connection.process_data_events() return int(self.response) # 建立客户端 fibonacci_rpc = FibonacciRpcClient() # 发送RPC请求,丢进rpc队列,等待客户端处理完毕,给与响应 print("发送了请求sum(100)") response = fibonacci_rpc.call(100) print("得到远程结果响应%r" % response)
server.py
import pika credentials = pika.PlainCredentials("guest", "guest") # 建立连接,服务器地址为localhost,也可指定ip地址 connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost',credentials=credentials)) # 建立会话 channel = connection.channel() # 模拟一个进程,例如接力比赛 def sum(n): n+=100 return n # 对RPC请求队列中的请求进行处理 def on_request(ch, method, props, body): print(body,type(body)) n = int(body) print(" 正在处理sum(%s)..." % n) # 调用数据处理方法 response = sum(n) # 将处理结果(响应)发送到回调队列 ch.basic_publish(exchange='', # reply_to代表回复目标 routing_key=props.reply_to, # correlation_id(关联标识):用来将RPC的响应和请求关联起来。 properties=pika.BasicProperties(correlation_id= props.correlation_id), body=str(response)) ch.basic_ack(delivery_tag=method.delivery_tag) print(" 处理完成sum(%s)" % n) # 负载均衡,同一时刻发送给该服务器的请求不超过一个 channel.basic_qos(prefetch_count=1) channel.basic_consume(queue='main_queue',on_message_callback=on_request) print("等待接收rpc请求") #开始消费 channel.start_consuming()