操作系统:centos6.6(三台服务器)
环境:selinux disabled;iptables off;java 1.8.0_131
安装包:hadoop-2.5.0.tar.gz
hadoop完全分布式模式(生产环境使用)
1、节点规划

2、hosts配置
#vim /etc/hosts (三台机都做此配置)
![]()
3、解压安装包 (在bigdata-hadoop1上安装)
#tar zxvf hadoop-2.5.0.tar.gz -C /data/hadoop/hadoopfull/
4、设置JAVA_HOME路径
![]()
export JAVA_HOME="/data/jdk"
etc/共有三个配置文件需要添加java路径,hadoop-env.sh、mapred-env.sh、yarn-env.sh
5、修改配置文件(全部先在bigdata-hadoop1的机器上修改)
1)mapred-site.xml

mapreduce.frameword.name设置mapreduce任务运行在yarn上
mapreduce.jobhistory.address是设置mapreduce的历史服务器安装在bigdata-hadoop1机器上
mapreduce.jobhistory.webapp.address是设置历史服务器的web页面地址和端口
2)hdfs-site.xml

dfs.namenode.secondary.http-address设置secondarynamenode启动在bigdata-hadoop3上
3)core-site.xml

fs.defaultFS为NameNode的地址
hadoop.tmp.dir为hadoop的临时地址,NameNode和DataNode的数据文件都会存在这个目录对应的子目录下
4)slaves
![]()
5)yarn-site.xml
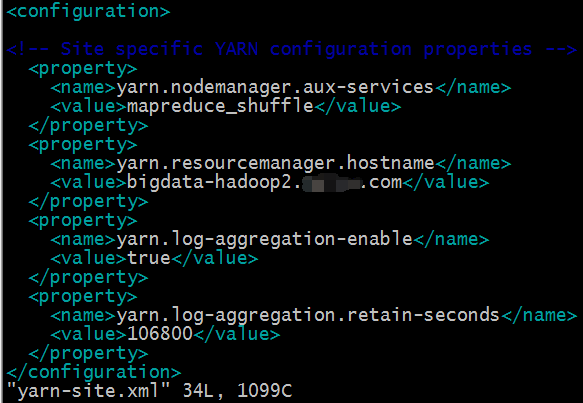
yarn.resourcemanager.hostname这个指定resourcemanager服务器指向bigdata-hadoop2
yarn.log-aggregation-enable是配置是否启用日志聚集功能
yarn.log-aggregation.retain-seconds是配置聚集的日志咋HDFS上最多保存多长时间
6、SSH无密码登录
hadoop服务器相互之间会通过SSH访问,以下步骤在hadoop服务器上都要执行
#ssh-keygen -t rsa
#ssh-copy-id bigdata-hadoop1.example.com
#ssh-copy-id bigdata-hadoop2.example.com
#ssh-copy-id bigdata-hadoop3.example.com
#ssh bigdata-hadoop1.example.com (测试登录一下)

7、分发hadoop文件(将bigdata-hadoop1上配置好的文件copy到bigdata-hadoop2和bigdata-hadoop3)
#scp -r hadoop-2.5.0/ bigdata-hadoop2.example.com:/data/hadoop/hadoopfull
#scp -r hadoop-2.5.0/ bigdata-hadoop3.example.com:/data/hadoop/hadoopfull
![]()
hadoop-2.5.0/share/doc目录的hadoop的文档,copy的时候可以把这些文档删除或者移到其他地方,提高copy的速度,doc/下的这些文档大约有1.6G
8、格式化NameNode
#bin/hdfs namenode -format
格式化完成之后会在tmp临时目录下生成dfs文件,如果需要重新格式化,要删除此dfs文件,否则NameNode的ID和DataNode的ID不一样,服务启动时会报错

9、启动集群
1)启动HDFS
#sbin/start-dfs.sh
这个脚本启动时namenode和datanode的分配
在bigdata-hadoop1上会看到namode和datanode

在bigdata-hadoop2上会看到datanode

在bigdata-hadoop3上会看到datanode和secondarynamenode

2)启动YARN
#/sbin/start-yarn.sh
在bigdata-hadoop1、bigdata-hadoop2和bigdata-hadoop3节点上会看到NodeManager

因为我们规划的ResourceManager是在bigdata-hadoop2上,所以需要在bigdata-hadoop2上启动ResourceManager
#sbin/yarn-daemon.sh start resourcemanager

3)启动日志服务
根据我们的规划,MapReduce日志服务在bigdata-hadoop1上启动
#sbin/mr-jobhistory-daemon.sh start JobHistoryServer

10、页面呈现
1)windows服务器上做hosts解析

2)访问地址bigdata-hadoop1.example.com:50070
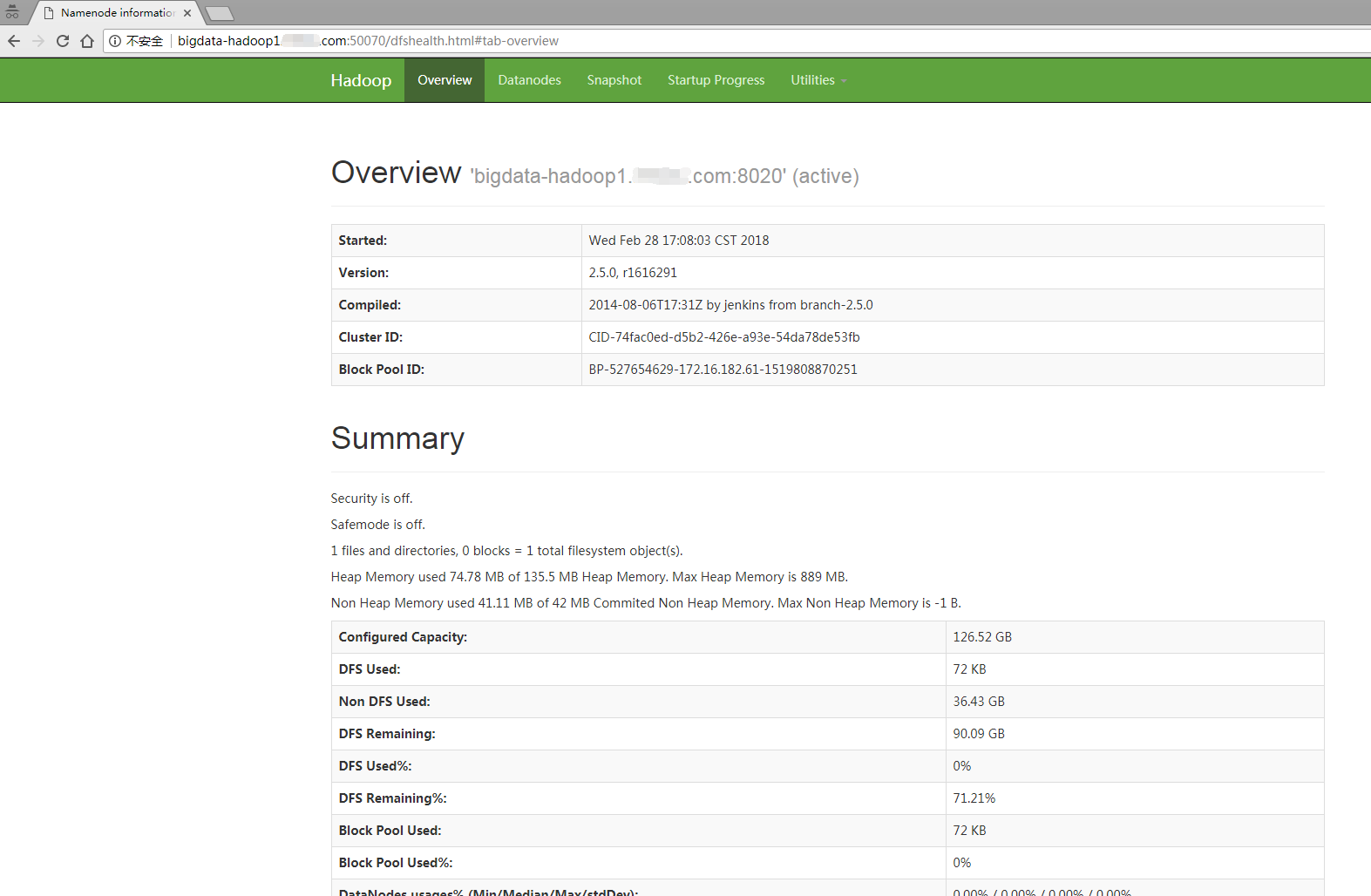
3、访问地址bigdata-hadoop2.example.com:8088

11、JOB测试
1、准备mapredue的输入文件
#cat wc.input

2、创建输入目录input
#hadoop fs -mkdir /input(或者#bin/hdfs dfs -mkdir /input)
![]()
3、上传wc.input文件(或者#bin/hdfs dfs -put wc.input /input)
#hadoop fs -put wc.input /input
![]()
4、运行hadoop自带的mapreduce demo
#bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /input/wc.input /output1
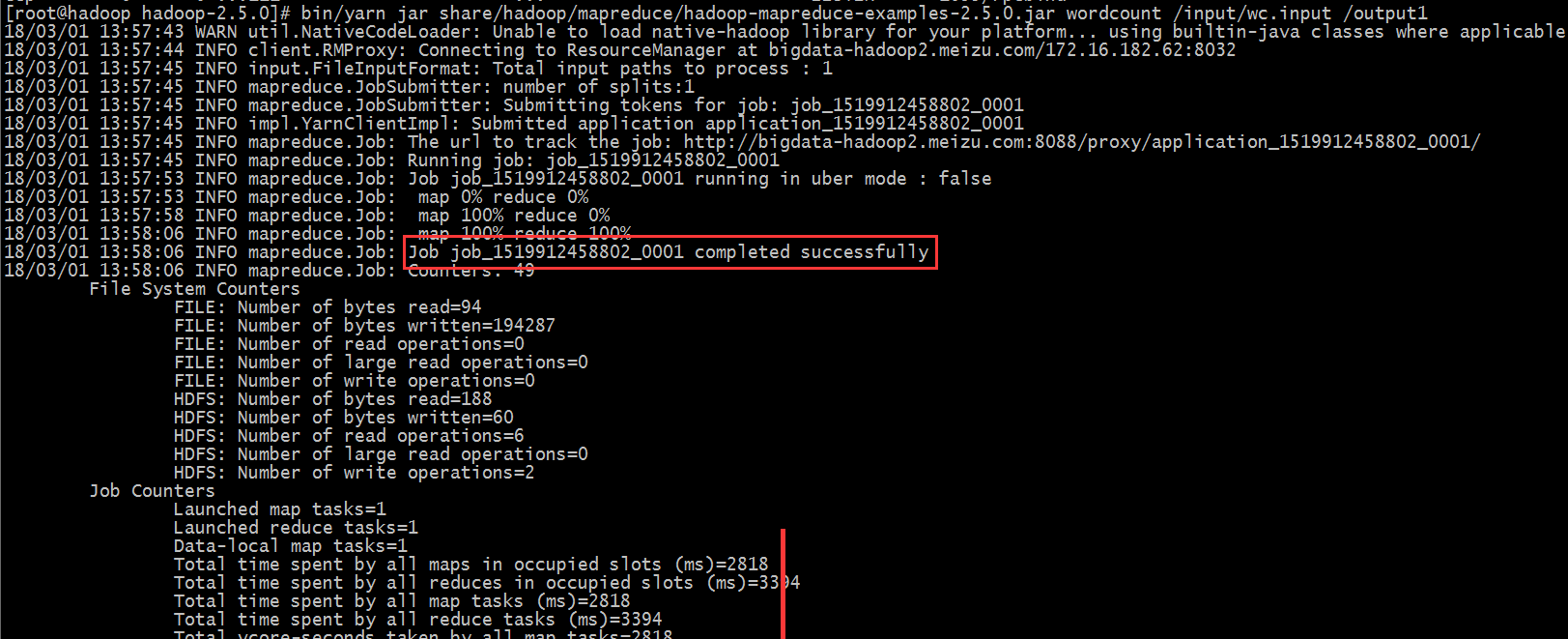
表示mapreduce计算成功的地方可以从三处查看:
第一个地方是执行过程中,从以上截图的Job job_1519912458802_0001 completed successfully表明执行成功
第二个地方是web界面
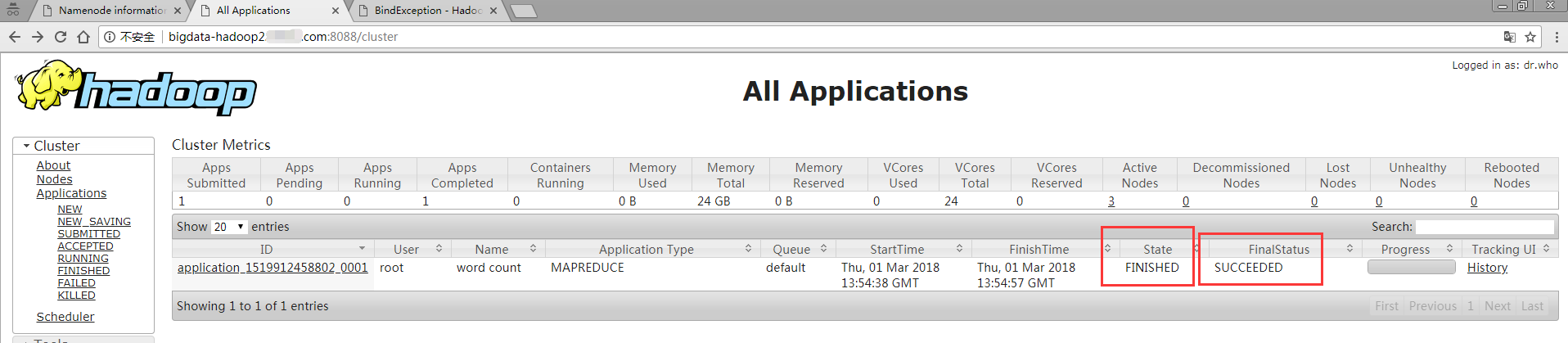
- 第三个地方是查看output1的目录#hadoop fs -ls /output1,看到_SUCCESS
![]()
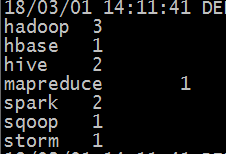
12、查看mapreduce的计算结果
#hadoop fs -cat /output1/part-r-00000