欢迎大家前往腾讯云社区,获取更多腾讯海量技术实践干货哦~
作者:解洪文
导语
随着最近几年机器人、无人机、无人驾驶、VR/AR的火爆,SLAM技术也为大家熟知,被认为是这些领域的关键技术之一。本文对SLAM技术及其发展进行简要介绍,分析视觉SLAM系统的关键问题以及在实际应用中的难点,并对SLAM的未来进行展望。
1. SLAM技术
SLAM(Simultaneous Localization and Mapping),同步定位与地图构建,最早在机器人领域提出,它指的是:机器人从未知环境的未知地点出发,在运动过程中通过重复观测到的环境特征定位自身位置和姿态,再根据自身位置构建周围环境的增量式地图,从而达到同时定位和地图构建的目的。由于SLAM的重要学术价值和应用价值,一直以来都被认为是实现全自主移动机器人的关键技术。
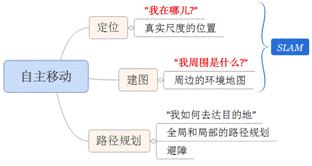
如下图,通俗的来讲,SLAM回答两个问题:“我在哪儿?”“我周围是什么?”,就如同人到了一个陌生环境中一样,SLAM试图要解决的就是恢复出观察者自身和周围环境的相对空间关系,“我在哪儿”对应的就是定位问题,而“我周围是什么”对应的就是建图问题,给出周围环境的一个描述。回答了这两个问题,其实就完成了对自身和周边环境的空间认知。有了这个基础,就可以进行路径规划去达要去的目的地,在此过程中还需要及时的检测躲避遇到的障碍物,保证运行安全。
2. SLAM发展简介
自从上世纪80年代SLAM概念的提出到现在,SLAM技术已经走过了30多年的历史。SLAM系统使用的传感器在不断拓展,从早期的声呐,到后来的2D/3D激光雷达,再到单目、双目、RGBD、ToF等各种相机,以及与惯性测量单元IMU等传感器的融合;SLAM的算法也从开始的基于滤波器的方法(EKF、PF等)向基于优化的方法转变,技术框架也从开始的单一线程向多线程演进。下面介绍这些过程中一些代表性的SLAM技术。
(1)激光雷达SLAM发展
基于激光雷达的SLAM(Lidar SLAM)采用2D或3D激光雷达(也叫单线或多线激光雷达),如下图所示。在室内机器人(如扫地机器人)上,一般使用2D激光雷达,在无人驾驶领域,一般使用3D激光雷达。

激光雷达的优点是测量精确,能够比较精准的提供角度和距离信息,可以达到<1°的角度精度以及cm级别的测距精度,扫描范围广(通常能够覆盖平面内270°以上的范围),而且基于扫描振镜式的固态激光雷达(如Sick、Hokuyo等)可以达到较高的数据刷新率(20Hz以上),基本满足了实时操作的需要;缺点是价格比较昂贵(目前市面上比较便宜的机械旋转式单线激光雷达也得几千元),安装部署对结构有要求(要求扫描平面无遮挡)。
激光雷达SLAM建立的地图常常使用占据栅格地图(Ocupanccy Grid)表示,每个栅格以概率的形式表示被占据的概率,存储非常紧凑,特别适合于进行路径规划。
现任Udacity创始人CEO、前Google副总裁、谷歌无人车领导者Sebastian Thrun大神(下图)在他2005年的经典著作《Probabilistic Robotics》一书中详细阐述了利用2D激光雷达基于概率方法进行地图构建和定位的理论基础,并阐述了基于RBPF粒子滤波器的FastSLAM方法,成为后来2D激光雷达建图的标准方法之一GMapping[1][2]的基础,该算法也被集成到机器人操作系统(Robot Operation System,ROS)中。

2013年,文献[3]对ROS中的几种2D SLAM的算法HectorSLAM,KartoSLAM,CoreSLAM,LagoSLAM和GMapping做了比较评估,读者可前往细看。
2016年,Google开源其激光雷达SLAM算法库Cartographer[4],它改进了GMapping计算复杂,没有有效处理闭环的缺点,采用SubMap和Scan Match的思想构建地图,能够有效处理闭环,达到了较好的效果。
(2)视觉SLAM发展
相比于激光雷达,作为视觉SLAM传感器的相机更加便宜、轻便,而且随处可得(如人人都用的手机上都配有摄像头),另外图像能提供更加丰富的信息,特征区分度更高,缺点是图像信息的实时处理需要很高的计算能力。幸运的是随着计算硬件的能力提升,在小型PC和嵌入式设备,乃至移动设备上运行实时的视觉SLAM已经成为了可能。
视觉SLAM使用的传感器目前主要有单目相机、双目相机、RGBD相机三种,其中RGBD相机的深度信息有通过结构光原理计算的(如Kinect1代),也有通过投射红外pattern并利用双目红外相机来计算的(如Intel RealSense R200),也有通过TOF相机实现的(如Kinect2代),对用户来讲,这些类型的RGBD都可以输出RGB图像和Depth图像。

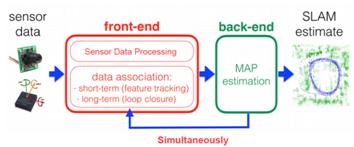
现代流行的视觉SLAM系统大概可以分为前端和后端,如下图所示。前端完成数据关联,相当于VO(视觉里程计),研究帧与帧之间变换关系,主要完成实时的位姿跟踪,对输入的图像进行处理,计算姿态变化,同时也检测并处理闭环,当有IMU信息时,也可以参与融合计算(视觉惯性里程计VIO的做法);后端主要对前端的输出结果进行优化,利用滤波理论(EKF、PF等)或者优化理论进行树或图的优化,得到最优的位姿估计和地图。
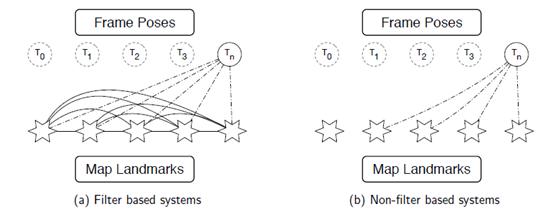
采用滤波器的SLAM,如下图(a),估计n时刻的相机位姿Tn需要使用地图中所有路标的信息,而且每帧都需要更新这些路标的状态,随着新的路标的不断加入,状态矩阵的规模增长迅速,导致计算和求解耗时越来越严重,因此不适宜长时间大场景的操作;而采用优化算法的SLAM,如下图(b),通常结合关键帧使用,估计n时刻的相机位姿Tn可以使用整个地图的一个子集,不需要在每幅图像都更新地图数据,因此现代比较成功的实时SLAM系统大都采取优化的方法。
下面介绍视觉SLAM发展历程中几个比较有代表性的SLAM系统进行介绍:
MonoSLAM[5]是2007年由Davison 等开发的第一个成功基于单目摄像头的纯视觉SLAM 系统。MonoSLAM使用了扩展卡尔曼滤波,它的状态由相机运动参数和所有三维点位置构成, 每一时刻的相机方位均带有一个概率偏差,每个三维点位置也带有一个概率偏差, 可以用一个三维椭球表示, 椭球中心为估计值, 椭球体积表明不确定程度(如下图所示),在此概率模型下, 场景点投影至图像的形状为一个投影概率椭圆。MonoSLAM 为每帧图像中抽取Shi-Tomasi角点[6], 在投影椭圆中主动搜索(active search)[7]特征点匹配。由于将三维点位置加入估计的状态变量中,则每一时刻的计算复杂度为O(n3) , 因此只能处理几百个点的小场景。

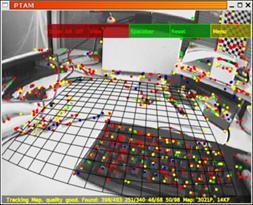
同年,Davison在Oxford的师父Murray和Klein发表了实时SLAM系统PTAM(Parallel Tracking and Mapping)[8]并开源(如下图),它是首个基于关键帧BA的单目视觉SLAM 系统, 随后在2009 年移植到手机端上[9]。PTAM在架构上做出了创新的设计,它将姿态跟踪(Tracking)和建图(Mapping)两个线程分开并行进行,这在当时是一个创举,第一次让大家觉得对地图的优化可以整合到实时计算中,并且整个系统可以跑起来。这种设计为后来的实时SLAM(如ORB-SLAM)所效仿,成为了现代SLAM系统的标配。具体而言,姿态跟踪线程不修改地图,只是利用已知地图来快速跟踪;而建图线程专注于地图的建立、维护和更新。即使建立地图线程耗时稍长,姿态跟踪线程仍然有地图可以跟踪(如果设备还在已建成的地图范围内)。此外,PTAM还实现丢失重定位的策略,如果成功匹配点(Inliers)数不足(如因图像模糊、快速运动等)造成跟踪失败时,则开始重定位[10]——将当前帧与已有关键帧的缩略图进行比较,选择最相似的关键帧作为当前帧方位的预测。
2011年,Newcombe 等人提出了单目DTAM 系统[11], 其最显著的特点是能实时恢复场景三维模型(如下图)。基于三维模型,DTAM 既能允许AR应用中的虚拟物体与场景发生物理碰撞,又能保证在特征缺失、图像模糊等情况下稳定地直接跟踪。DTAM采用逆深度(Inverse Depth)[12]方式表达深度。如下图,DTAM将解空间离散为M×N×S 的三维网格,其中M× N为图像分辨率,S为逆深度分辨率,采用直接法构造能量函数进行优化求解。DTAM 对特征缺失、图像模糊有很好的鲁棒性,但由于DTAM 为每个像素都恢复稠密的深度图, 并且采用全局优化,因此计算量很大,即使采用GPU 加速, 模型的扩展效率仍然较低。

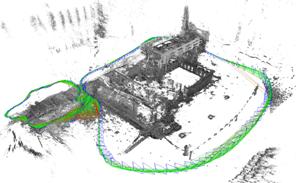
2013年,TUM机器视觉组的Engel 等人提出了一套同样也是基于直接法的视觉里程计(visual odometry, VO)系统,该系统2014年扩展为视觉SLAM 系统LSD-SLAM[13],并开源了代码。与DTAM相比,LSD-SLAM 仅恢复半稠密深度图(如下图),且每个像素深度独立计算, 因此能达到很高的计算效率。LSD-SLAM 采用关键帧表达场景,每个关键帧K包含图像 Ik、逆深度图Dk和逆深度的方差Vk。系统假设每个像素x的逆深度值服从高斯分布N(Dk (x),Vk (x))。LSD-SLAM 的前台线程采用直接法计算当前帧t与关键帧k之间相对运动,后台线程对关键帧中每个半稠密抽取的像素点x(梯度显著区域), 在It中沿极线搜索Ik (x)的对应点, 得到新的逆深度观测值及其方差,然后采用EKF更新Dk和Vk 。LSD-SLAM采用位姿图优化来闭合回环和处理大尺度场景。2015年,Engel等人对LSD-SLAM进行了功能拓展,使其能够支持双目相机[14]和全景相机[15]。
2014年,苏黎世大学机器人感知组的Forster等人提出开源的SVO系统[16],该系统对稀疏的特征块使用直接法配准(Sparse Model-based Image Alignment),获取相机位姿,随后根据光度不变假设构造优化方程对预测的特征位置进行优化(Feature Alignment),最后对位姿和结构进行优化(Motion-only BA和Structure-only BA),而在深度估计方面,构造深度滤波器,采用一个特殊的贝叶斯网络[17]对深度进行更新。SVO的一个突出优点就是速度快,由于使用了稀疏的图像块,而且不需要进行特征描述子的计算,因此它可以达到很高的速度(作者在无人机的嵌入式ARM Cortex A9 4核1.6Ghz处理器平台上可以达到55fps的速度),但是SVO缺点也很明显,它没有考虑重定位和闭环,不算是一个完整意义上的SLAM系统,丢失后基本就挂了,而且它的Depth Filter收敛较慢,结果严重地依赖于准确的位姿估计;2016年,Forster对SVO进行改进,形成SVO2.0[18]版本,新的版本做出了很大的改进,增加了边缘的跟踪,并且考虑了IMU的运动先验信息,支持大视场角相机(如鱼眼相机和反射式全景相机)和多相机系统,该系统目前也开源了可执行版本[19];值得一提的是,Foster对VIO的理论也进行了详细的推导,相关的文献[20]成为后续SLAM融合IMU系统的理论指导,如后面的Visual Inertial ORBSLAM等系统。
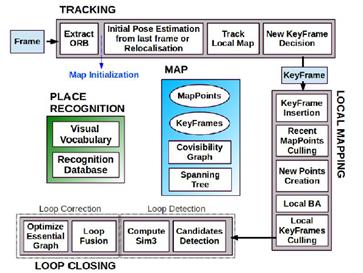
2015年,Mur-Artal 等提出了开源的单目ORB-SLAM[21],并于2016年拓展为支持双目和RGBD传感器的ORB-SLAM2[22],它是目前支持传感器最全且性能最好的视觉SLAM系统之一,也是所有在KITTI数据集上提交结果的开源系统中排名最靠前的一个[23]。ORB-SLAM 延续了PTAM 的算法框架,增加了单独的回环检测线程,并对框架中的大部分组件都做了改进,归纳起来主要有以下几点:1)ORB-SLAM追踪、建图、重定位和回环检测各个环节都使用了统一的ORB 特征[24],使得建立的地图可以保存载入重复利用;2)得益于共视图(convisibility graph)的使用,将跟踪和建图操作集中在一个局部互见区域中,使其能够不依赖于整体地图的大小,能够实现大范围场景的实时操作;3)采用统一的BoW词袋模型进行重定位和闭环检测,并且建立索引来提高检测速度;4)改进了PTAM只能手工选择从平面场景初始化的不足,提出基于模型选择的新的自动鲁棒的系统初始化策略,允许从平面或非平面场景可靠地自动初始化。后来,Mur-Artal又将系统进行了拓展,形成了融合IMU信息的Visual Inertial ORB-SLAM[25],采用了Foster的论文[]提出的预积分的方法,对IMU的初始化过程和与视觉信息的联合优化做了阐述。
2016年,LSD-SLAM的作者,TUM机器视觉组的Engel等人又提出了DSO系统[26]。该系统是一种新的基于直接法和稀疏法的视觉里程计,它将最小化光度误差模型和模型参数联合优化方法相结合。为了满足实时性,不对图像进行光滑处理,而是对整个图像均匀采样。DSO不进行关键点检测和特征描述子计算,而是在整个图像内采样具有强度梯度的像素点,包括白色墙壁上的边缘和强度平滑变化的像素点。而且,DSO提出了完整的光度标定方法,考虑了曝光时间,透镜晕影和非线性响应函数的影响。该系统在TUM monoVO、EuRoC MAV和ICL-NUIM三个数据集上进行了测试,达到了很高的跟踪精度和鲁棒性。

2017年,香港科技大学的沈绍劼老师课题组提出了融合IMU和视觉信息的VINS系统[27],同时开源手机和Linux两个版本的代码,这是首个直接开源手机平台代码的视觉IMU融合SLAM系统。这个系统可以运行在iOS设备上,为手机端的增强现实应用提供精确的定位功能,同时该系统也在应用在了无人机控制上,并取得了较好的效果。VINS-Mobile使用滑动窗口优化方法,采用四元数姿态的方式完成视觉和IMU融合,并带有基于BoW的闭环检测模块,累计误差通过全局位姿图得到实时校正。

推荐阅读
此文已由作者授权腾讯云技术社区发布,转载请注明原文出处