导语 | 鹰眼是由腾讯PCG技术运营部负责的海量级分布式实时监控和日志分析系统,为响应公司战略要求,将原先的业务迁移上云,最终产生了可喜的变化。本文将介绍分布式日志系统(鹰眼)的整体上云方案,希望与大家一同交流。
一、鹰眼平台介绍
鹰眼是由PCG技术运营部负责的海量级分布式实时监控和日志分析系统,支持多语言的上报,域名为:http://log2.oa.com/
鹰眼的数据上报是通过ATTA提供的,ATTA支持多语言的上报(JAVA,Python,C++等),上报之后,鹰眼从ATTA系统拉取数据最终写入到ES,通过ES的倒排索引机制,快速查询功能,写入功能等。
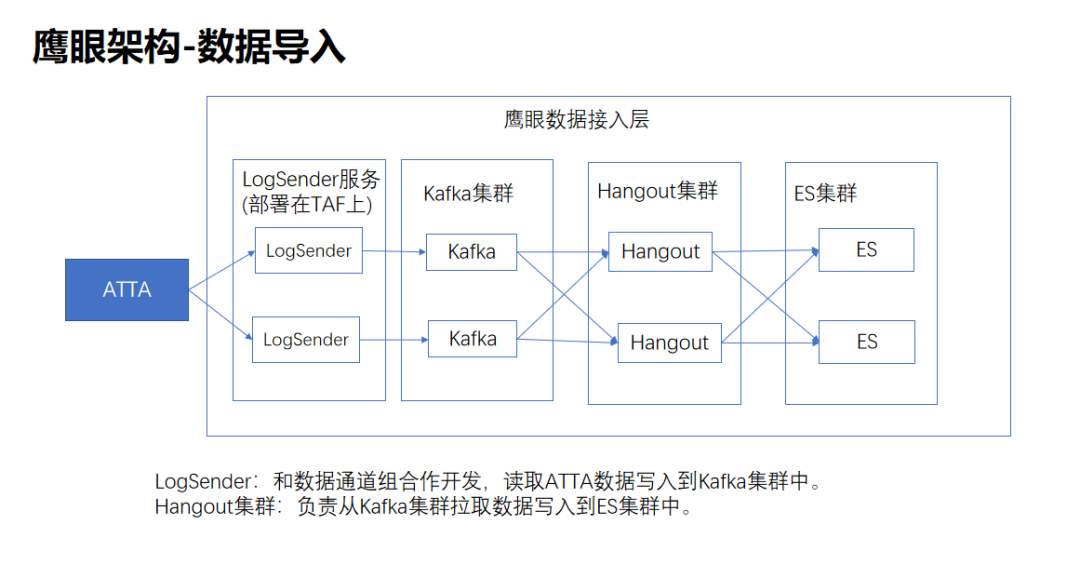
使用ES的倒排索引机制,百亿数据秒级查询返回的能力,鹰眼提供了以下功能:
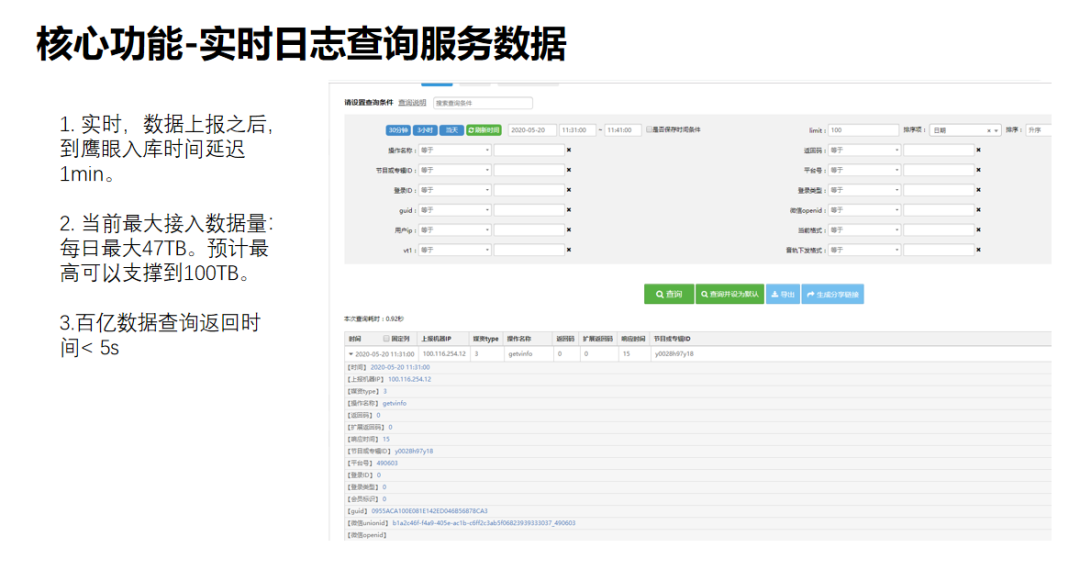
1. 实时日志查询服务数据
实时日志查询服务数据上报到ATTA之后,开发可以通过鹰眼及时查询到日志,定位问题,运维可以通过鹰眼提供的数据统计界面实时查询到业务的运行情况。
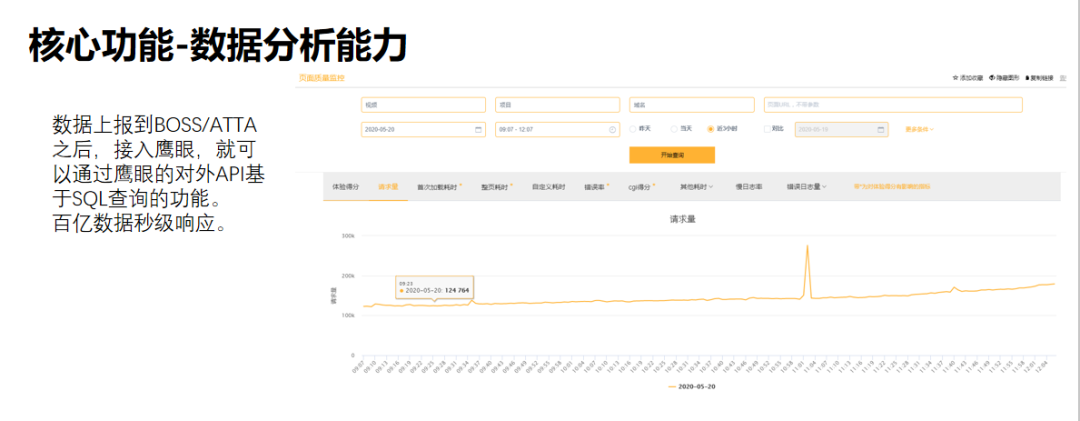
2. 数据分析能力
鹰眼数据入库后,用户可以通过API直接调用,进行OLAP分析。
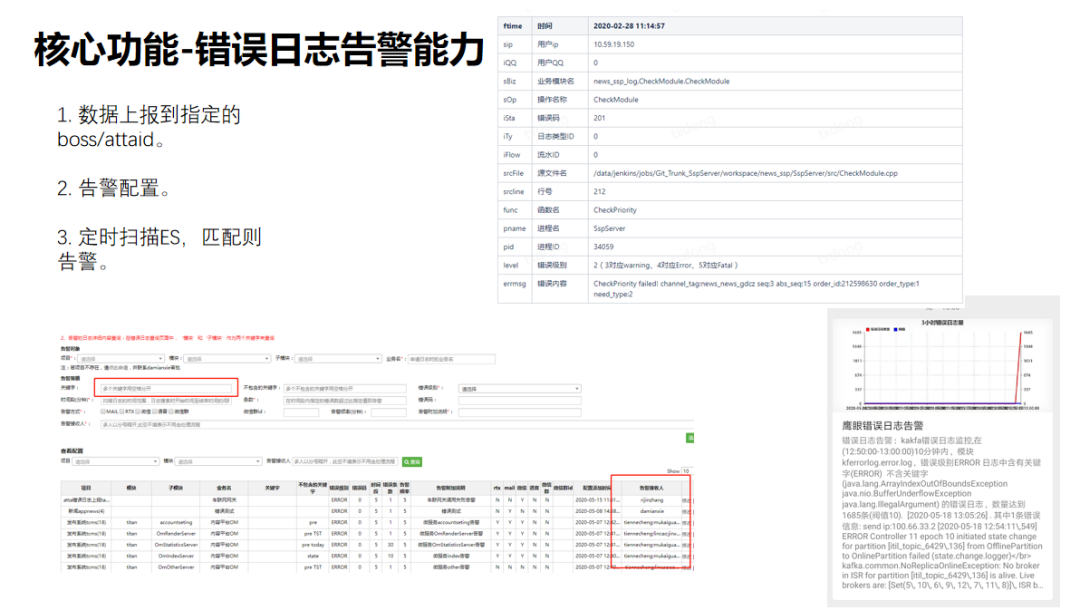
3. 错误日志告警服务
程序如果出现错误之后,可以按照鹰眼规范来上报错误日志,鹰眼进行分词,根据不同的错误码进行分钟级别的告警。
4. grafana实时分析告警
通过grafana对上报到鹰眼的数据进行实时的分析告警。(由于ES不支持大并发查询,所以无法对超大数据进行实时分析)
二、上云的背景
公司战略调整,成立新的云事业群,内部成立“技术委员会”,启动“开源协同”和“业务上云”的两大战略方向。
在架构演进中,鹰眼团队上云能得到什么好处?上云的价值是什么?
1. 业务价值
-
聚焦业务,提升研发效率 ;
-
加快技术换代,保持技术优势(传统互联网 vs 云时代);
-
使用更好的云开源组件服务(可用性、稳定性、文档API…);
-
计算资源重用,弹性伸缩,优化成本 ;
-
标准化CI/CD流程。
2. 工程师价值
-
扩宽技术视野,避免闭门造车 ;
-
掌握的技能更有价值 ;
-
输出优秀组件到云,提高影响力。
3. 腾讯云价值
-
为客户输出业务上云经验 ;
-
帮助腾讯云打磨云组件。
三、组件上云架构选型
为了保证业务的延续性和架构的演进,数据导入过程中的主体流程并没有太大改变,Kafka直接使用到云上的CKAFKA,ES直接使用到云上的ES。

ES和Kafka直接使用云上组件,其他组件需要进行重构。
1. 重构LogSender
生产者程序写入Kafka性能瓶颈特别大,高峰期丢数据特别严重。
生产者程序写数据流程:读取BOSS订阅->IP解析->写入Kafka。
(1)IP解析性能瓶颈
之前生产者程序是C++版本,经过打印日志,发现高峰期IP解析耗时特别严重。排查代码,发现IP解析加锁了。所以高峰期丢数据特别严重。解决方法是:将IP解析改为二分查找算法来进行IP定位,然后取消锁,解决。
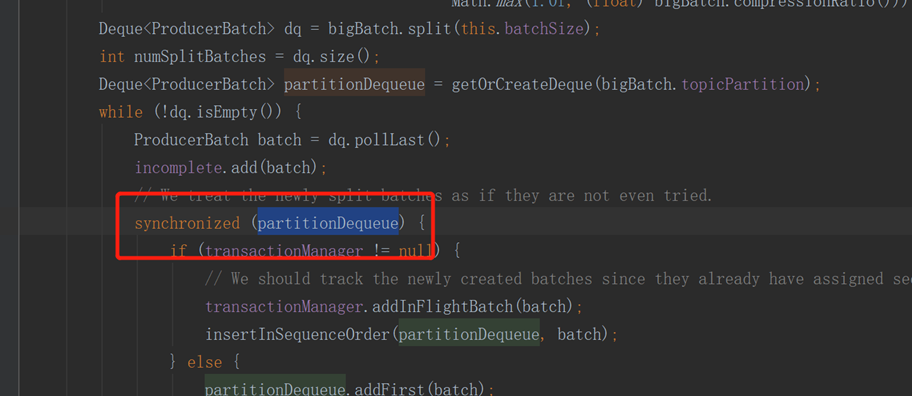
(2)Kafka性能瓶颈问题
由于我们生产者程序,一个程序会读取很多很多个topic,然后写入到Kafka,我们尝试,使用一个producer和多个producer发送,性能都提升不起来。
经过源代码排查,发现Kafka发送时,会根据topic分区来锁队列,当这个队列满的时候,就会发送一批消息出去。所以解决方案为,每个BOSSID应该有独立的发送客户端。
-
数据量大的,有多个Kafka客户端
-
数据量小的一批topic,可以共用一个kafka生产者。
优化之后:在数据量非常大的时候,因为程序性能原因,会导致一分钟单节点最多只能处理13万条左右的数据。改进后, 单节点能处理55w条左右的数据。 性能提升4倍。
2. Kafka选型
Kafka整体来说,高版本比低版本支持的功能更多,如事务,磁盘间的数据转移等,写入性能并不会下降。此处选型选的是最高版本。
当然CKAFKA并没有给我们选择版本的机会,客户端写入的时候还是得注意下和Kafka服务端版本一致,避免不必要的问题。
如低版本的客户端写入高版本的Kafka时,如果使用数据压缩,则服务端接受到数据后,会进行解压,然后再按照对应的格式压缩(如果版本一致,则不会有此动作),增加服务端的运行成本。
Kafka上云之后,单机性能能达到400MB/s,而我们自建的Kafka,单机性能最多达到100MB/s,性能提升4倍。
3. 重构Hangout
ES写入部分,业界有很多组件,最出名的是Logstach,由于性能不够,我们自己重新开发了一套读取Kafka写入ES的组件。
核心优化点如下所示:

由于磁盘IO的大幅减少,能在极限优化下继续提升性能2倍以上。整体来说,ES写入提升性能6倍左右。
4. ES选型
ES低版本支持TCP写入和HTTP写入两种方式,高版本只支持一种HTTP写入方式。实测发现有如下区别:
-
TCP写入比HTTP更快;
-
HTTP写入更稳定一点,TCP写入是直接写到节点上面的,容易出现负载不均衡,HTTP更容易通过数据节点节点进行负载均衡。
因此我们采用了云版本ES 6.8.2。
上云之后的效果:
-
平均写入1TB数据,云下需要 80核,256G内存 12TB磁盘 (BX1机型);
-
云上需要 3 * (16核 64GB 5TB硬盘 );
-
平均节省资源1倍左右。
四、上云之后的变化
ES/Kafka上云之后,统计有50多个ES集群,12个Kafka集群.
1. 工作量的减少
如果不上云的话,搭建这些集群平均一个ES集群需要20台机器,从申请机器,到机器初始化,磁盘RAID,安装ES,平均每个ES需要3-4人/天,则搭建成本就已经需要200多人(62*3-4)/天了,还没有谈到集群运维成本,远远超过鹰眼团队的人力。
2. 成本的减少
上云之后,伴随着各个组件的优化,整体性能提升至少2-3倍,所需要的资源同比会减少2-3倍、每年节省成本至少2kw。
3. 工作更加聚焦
上云之后:
-
鹰眼聚焦于写入性能优化,大大提升了写入效率;
-
监控体系的建立,数据上报到ATTA之后,就进行数据对账,及时发现数据的延迟给出告警;
-
在新功能开发上,基于ES支持隔天查询,如果当日数据暴涨之后,通过建立备份索引的机制增大写入量。
五、后续架构演进
1. 监控体系建设
核心模块既要有日志,也要有监控,不同模块的监控维度对应起来,让核心的模块,日志和监控都有,当业务出现异常时,及时调出发生异常的基础数据(如CPU/Mem等),指标数据,日志数据等进行完整的监控体系的建设。
2. 架构持续升级
目前自研Hangout写入只能保证at least once,但是无法保证exactly once。尝试通过flink的checkpoint机制,保证数据链路的完整性。