一.线程
1.什么是线程(thread)
线程:线程是cpu处理的单位(实体),线程存在于进程中.线程没有主次之分,是平等的.
2.线程的两种创建方式


from threading import Thread import time def f1(n): time.sleep(1) print(f"{n}号线程") def f2(n): print(f"{n}号线程") if __name__ == '__main__': t1 = Thread(target=f1,args=(1,)) # 创建线程 和创建进程一样 t2 = Thread(target=f2,args=(2,)) t1.start() t2.start() print(t1.ident) # t1.name = "666" # 给线程的name属性赋值 # print(t1.getName()) # getName() 获取对象的名字 # print(t1.isAlive()) # 判断是否还运行 # t1.join() print("线程")
class MyThread(Thread): # 创建一个线程类, 和创建进程一样 def __init__(self,name): super().__init__() self.name = name def run(self): print(f"{self.name}:hah") if __name__ == '__main__': t = MyThread("赏金猎人") t.start() print("线程")
3.线程中的几个方法
start():启动线程
join():等待该线程结束,再往下执行
is_alive():查看线程是否还在运行
getName():获取线程的名称
4.线程中的几个属性
name:线程的名称,可以自定义
daemon:守护线程,默认为False
二.线程是共享这一进程中的数据
线程存在于同一个进程中,所以线程是共享同一进程里的数据,但是多个线程内部都有自己的数据栈,数据不共享.
from threading import Thread import time,os num = 100 def f1(): time.sleep(1) global num num = 3 print(os.getpid()) print(num) if __name__ == '__main__': t = Thread(target=f1,) t.start() t.join() # 等待线程代码执行完再往下执行 print(os.getpid()) print(num)
三.线程与进程效率的对比
1.线程比进程开销小,因为进程需要开辟内存,而线程是在进程中的.
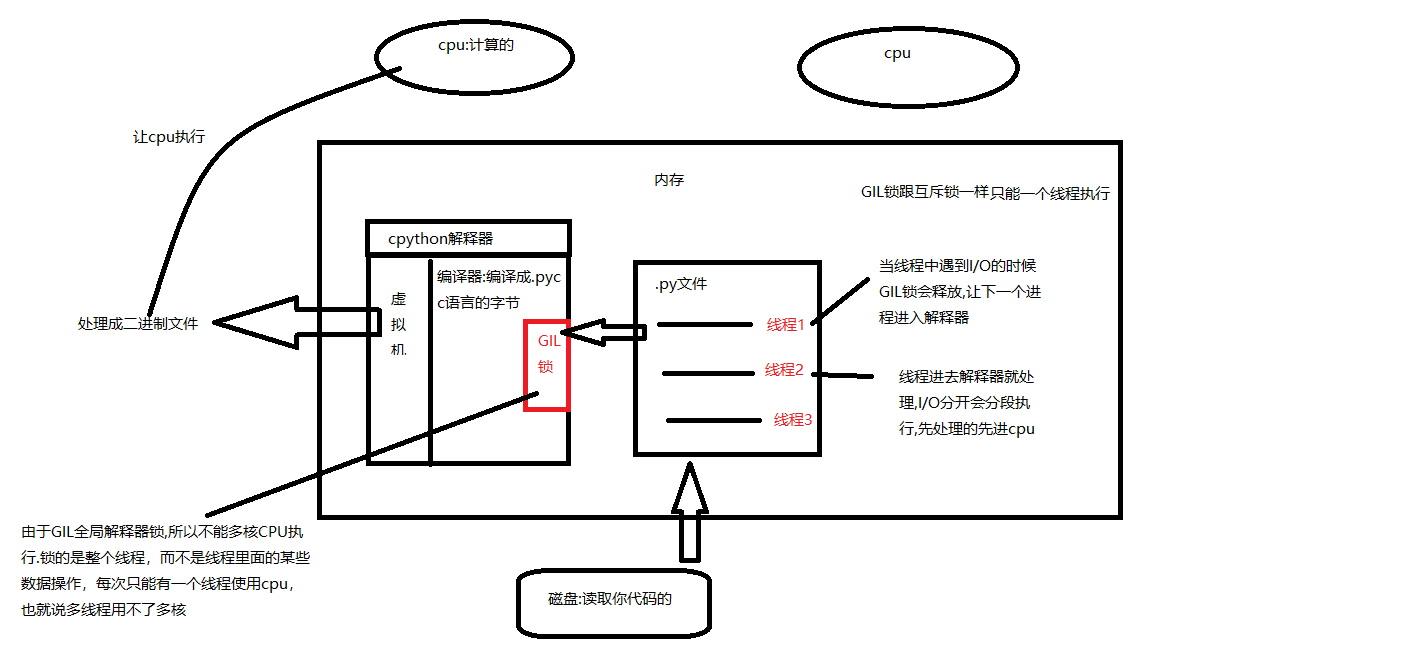
2.由于cpython解释器的原因,线程不能应用多核.
from multiprocessing import Process,Pool from threading import Thread import time def f1(): pass if __name__ == '__main__': t_start_time = time.time() t_lst = [] for i in range(8): t = Thread(target=f1,) t.start() t_lst.append(t) [tt.join() for tt in t_lst] t_end_time = time.time() t_res_time = t_end_time - t_start_time p_start_time = time.time() p_lst = [] for i in range(8): p = Process(target=f1, ) p.start() t_lst.append(p) [pp.join() for pp in p_lst] p_end_time = time.time() p_res_time = p_end_time - p_start_time print("多线程:",t_res_time) print("多进程:",p_res_time)
四.守护线程和守护进程
1.线程的结束方式:等所有线程都结束了主线程再结束.
守护线程:其他非守护线程结束,守护线程也随之结束
2.进程的结束方式:主进程代码先执行完,但是主进程需要等待所有的进程结束后(回收,否则子进程就成了僵尸进程)才结束.
守护进程:随着主进程的结束而结束
五.锁
1.线程锁(互斥锁/同步锁)
线程锁:锁定一段代码,只能有一个线程执行.保护数据安全
from threading import Thread , Lock import time num = 100 def f1(loc): loc.acquire() global num temp = num temp -= 1 time.sleep(0.1) num = temp loc.release() if __name__ == '__main__': l = Lock() t_lst = [] for i in range(10): t = Thread(target=f1,args=(l,)) t.start() t_lst.append(t) [tt.join() for tt in t_lst] print(num)
2.死锁现象
现象:出现在锁嵌套的时候,两个线程互相抢对方已经获取的锁,双方互相等待,就造成了死锁现象
from threading import Thread , Lock , RLock import time def f1(locA,locB): locA.acquire() print("f1抢到A锁") time.sleep(1) # 停一秒,确保f2把B锁抢到 locB.acquire() print("f1抢到B锁") locB.release() locA.release() def f2(locA,locB): locB.acquire() print("f2抢到了B锁") time.sleep(1) # 停一秒,确保f1把A锁抢到 locA.acquire() print("f2抢到了A锁") locA.release() locB.release() if __name__ == '__main__': locA = Lock() locB = Lock() t1 = Thread(target=f1,args=(locA,locB)) t2 = Thread(target=f2,args=(locA,locB)) t1.start() t2.start()
3.递归锁(RLock)
递归锁:递归锁要使用同一把锁,只是锁名不一样.内部类似有一个计数器,获取锁的时候+1,释放锁的时候-1,为0的时候别的线程就能抢这把锁.能够解决死锁现象
from threading import Thread , Lock , RLock import time def f1(locA,locB): locA.acquire() print("f1抢到A锁") time.sleep(1) # 停一秒,确保f2把B锁抢到 locB.acquire() print("f1抢到B锁") locB.release() locA.release() def f2(locA,locB): locB.acquire() print("f2抢到了B锁") time.sleep(1) # 停一秒,确保f1把A锁抢到 locA.acquire() print("f2抢到了A锁") locA.release() locB.release() if __name__ == '__main__': locA = locB = RLock() # 必须是同一把递归锁,递归锁内部计数来操作什么时候释放锁 t1 = Thread(target=f1,args=(locA,locB)) t2 = Thread(target=f2,args=(locA,locB)) t1.start() t2.start() """ lockA = lockB = RLock() 创建一个递归锁,一定要同一个锁,不同变量名 lockA.acquire() 一次内部计数器 +1 lockA.release() 一次内部计数器 -1 为0的时候,别的线程就能抢锁了 """
4.GIL(Global Interpreter Lock )全局解释器锁
GIL锁:是在cpython解释器中的一把互斥锁.
由于GIL锁的存在,线程不能应用多核,使得python在处理计算密集型的线程效率会很低.
六.信号量
和进程中的信号量一样
七.事件
和进程中的事件一样