为什么需要主从复制
1.在复杂业务场景中,有一个场景,有一个sql语句需要锁表,导致不能使用读的服务,这就很影响运行中的业务,使用主从复制,主库负责写,从库负责读,即使主库出现锁表,从库也可以正常运行工作。
2.做数据的热备
3.架构的扩展,业务量越来越大,io访问频率过高,单机无法满足,此时做多库的存储,降低磁盘io访问频率,提高单个机器的io性能。
什么是主从复制?
mysql主从复制是指数据可以从一个mysql数据库库主节点复制到一个或者多个从节点,mysql默认采取异步复制的方式,这样从节点就不用一直访问主服务器来更新自己的数据,数据的更新可以在远程连接上进行,从节点可以复制主数据库中所有数据库或者特定的数据库,特定的表。
mysql复制原理
原理:
1.master服务器将数据的改变记录二进制binlog日志,当master上的数据发生改变时,则将其改编写入二进制文件中。
2.slave服务器会在一定时间间隔内对master二进制进行探测其是否发生改变,如果发生改变,则开始一个i/oThread请求master二进制时间
3.同时主节点为每个io线程启动一个dump线程,用于发送二进制事件,并保存至从节点本地的中继日志中读取二进制日志,在本地重放,使得其数据和主节点的保持一致,最后io和sql的thread进入睡眠状态,等待下一次被唤醒。
也就说:
从库会生成两个线程,一个io线程一个sql线程。
io线程会去请求主库的binlog,并将得到的binlog写入到本地relay-log(中继日志)文件中.
主库会生成一个log dump线程,用来给从库io线程传binlog;
sql线程,会读取relay log文件中的日志,并解析成sql语句逐一执行。
注意:
1.master将操作语句记录到binlog日志中,然后授予slave远程连接的权限(master,一定要开启binlog二进制日志功能,通常为了数据安全考虑,slave也开启binlog功能).
2.slave开启两个线程,io线程和sql线程,其中:io线程负责读取master的binlog内容到中继日志relay log中。
sql线程负责从relay log日志里读取出binlog内容,并更新到slave的数据库里,这样就能保证slave数据和master数据保持一致了。
3.mysql复制至少需要两个Mysql服务器,当然mysql服务可以分布在不通的服务器上,也可以在一台mysql服务器上,也可以在一台服务器上启动多个服务。
4.mysql复制最好确保master和slave服务器上的mysql版本相同(如果不能满足版本一致,那么要保证master主节点的版本低于slave从节点的版本).
具体步骤:
1.从库通过手工执行change master to 语句连接主库,提供了连接的用户一切条件(user,password,port,ip),并且让从库知道,二进制的起点位置(file名 position号); start slave
2.从库的io线程和主库的dump线程建立连接。
3.从库根据change master to语句提供的file名和position号,io线程向主库发起binlog的请求。
4.主库dump线程根据从库的请求将本地binlog以events的方式发给从库io线程。
5.从库io线程接受binlog events,并存放到本地relay-log中,传送过来的信息,会记录到master.info中。
6.从库sql线程应用relay-log,并且把应用过的记录到relay-log.info中,默认情况下,已经使用的relay会自动被清理。
1.主从复制
通过binlog进行数据同步,一般从数据库都只有读的权限,主库进行写操作,不过从数据库也会有备份,避免数据丢失。
2.主主复制(互为主备)两个数据库数据保持一致。
3.一主多从(读多写少)
4.多主一从 多台服务器作为主,一台数据库作为同步
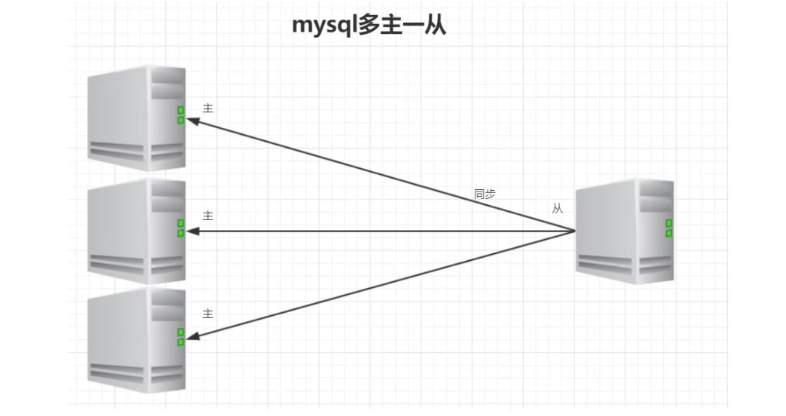
级联复制
如何实现主从复制
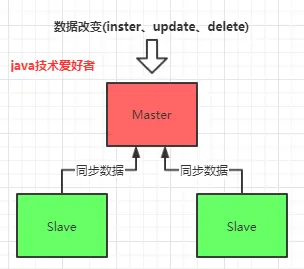
我这里用三台虚拟机(Linux)演示,IP分别是200(Master),57(Slave),82(Slave)。
预期的效果是一主二从,如下图所示:
使用命令行进入想设置为主库的mysql:
mysql -u root -p
输入密码登录
登录后设置参数如下:
//192.168.31.82是slave从机的IP
GRANT REPLICATION SLAVE ON *.* to 'root'@'192.168.31.57' identified by 'player3.';
//192.168.0.107是slave从机的IP
GRANT REPLICATION SLAVE ON *.* to 'root'@'192.168.31.82' identified by 'player3.';
//刷新系统权限表的配置
FLUSH PRIVILEGES;
上面的命令是给从库配置访问主库的账号和密码,如果报错如下:
ERROR 1819 (HY000): Your password does not satisfy the current policy requirements
输入命令,可以正常设置。
set global validate_password_policy=0;
接下来在找到mysql的配置文件/etc/my.cnf,增加以下配置:
# 开启binlog
log-bin=mysql-bin
server-id=104
# 需要同步的数据库,如果不配置则同步全部数据库
binlog-do-db=test_db
# binlog日志保留的天数,清除超过10天的日志
# 防止日志文件过大,导致磁盘空间不足
expire-logs-days=10
我的下面这个注释了,没有用,让他走全部的复制好了。。
#binlog-do-db=test_db
wq保存。
配置完成后,重启mysql:
service mysqld restart
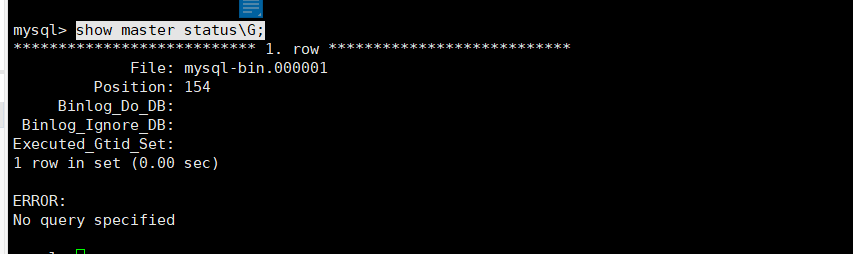
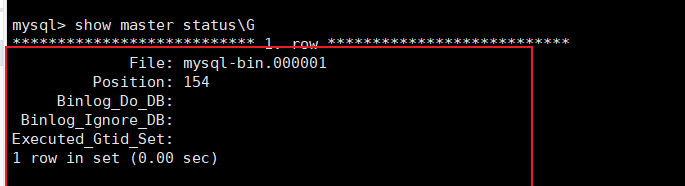
登录后通过命令查看:
show master status\G
Slave配置
Slave配置相对简单一点。从机肯定也是一台MySQL服务器,所以和Master一样,找到/etc/my.cnf配置文件,增加以下配置:
# 不要和其他mysql服务id重复即可
server-id=106
接着使用命令行登录到mysql服务器:
mysql -u root -p
然后输入密码登录进去。
进入到mysql后,再输入以下命令:
CHANGE MASTER TO MASTER_HOST='192.168.31.200',MASTER_USER='root',MASTER_PASSWORD='player3.',MASTER_LOG_FILE='mysql-bin.000001',MASTER_LOG_POS=862,master_port=3306;
报错如下:
ERROR 1794 (HY000): Slave is not configured or failed to initialize properly. You must at least set --server-id to enable either a master or a slave. Additional error messages can be found in the MySQL error log.
怀疑是没有重启导致的,由于数据是之前拷贝过来的,先把从库的数据删除了。MASTER_LOG_POS=0,偏移量改成了0.
重启了一下试试
service mysqld restart

没报错,再重启一下。
进入命令行输入:
show slave status\G
*************************** 1. row ***************************
Slave_IO_State:
Master_Host: 192.168.31.200
Master_User: root
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000001
Read_Master_Log_Pos: 4
Relay_Log_File: MiWiFi-R4CM-srv-relay-bin.000002
Relay_Log_Pos: 4
Relay_Master_Log_File: mysql-bin.000001
Slave_IO_Running: No
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 4
Relay_Log_Space: 154
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 1593
Last_IO_Error: Fatal error: The slave I/O thread stops because master and slave have equal MySQL server UUIDs; these UUIDs must be different for replication to work.
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 104
Master_UUID:
Master_Info_File: /var/lib/mysql/master.info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp: 220124 01:52:40
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position: 0
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)
上面的解决方案如下:
主从复制完成后,我们还需要实现读写分离,master负责写入数据,两台slave负责读取数据。怎么实现呢?
spring.shardingsphere.datasource.names=master,slave0,slave1
#master
spring.shardingsphere.datasource.master.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.master.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.master.url=jdbc:mysql://192.168.31.200:3306/test001?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.master.username=root
spring.shardingsphere.datasource.master.password=player3.
#slave0
spring.shardingsphere.datasource.slave0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.slave0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.slave0.url=jdbc:mysql://192.168.31.57:3306/test001?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.slave0.username=root
spring.shardingsphere.datasource.slave0.password=player3.
#slave1
spring.shardingsphere.datasource.slave1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.slave1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.slave1.url=jdbc:mysql://192.168.31.82:3306/test001?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.slave1.username=root
spring.shardingsphere.datasource.slave1.password=player3.
#配置slave节点的负载均衡均衡策略,采用轮询机制
spring.shardingsphere.masterslave.load-balance-algorithm-type=round_robin
spring.shardingsphere.masterslave.name=ms
#置主库master,负责数据的写入
spring.shardingsphere.masterslave.master-data-source-name=master
#配置从库slave节点
spring.shardingsphere.masterslave.slave-data-source-names=slave0,slave1
# 打开sql输出日志
spring.shardingsphere.props.sql.show=true
spring.main.allow-bean-definition-overriding=true
package com.player3.sharding.jdbc.pojo;
import lombok.Data;
import lombok.ToString;
@Data
@ToString
public class TbCommodityInfo {
private Long id;
private String commodityName;
private String commodityPrice;
private String description;
private Integer number;
}
package com.player3.sharding.jdbc.dao;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.player3.sharding.jdbc.pojo.TbCommodityInfo;
import org.springframework.stereotype.Repository;
@Repository
public interface TbCommodityInfoMapper extends BaseMapper<TbCommodityInfo> {
}
@Test
public void addCourse(){
for (int i = 200; i < 202; i++) {
TbCommodityInfo tbCommodityInfo=new TbCommodityInfo();
tbCommodityInfo.setCommodityName("商品"+i);
tbCommodityInfo.setCommodityPrice("price"+i);
tbCommodityInfo.setDescription("备注"+i);
tbCommodityInfo.setNumber(i);
tbCommodityInfoMapper.insert(tbCommodityInfo);
}
}
//查询的方法
@Test
public void findCourseDb(){
QueryWrapper<TbCommodityInfo> wrapper = new QueryWrapper<>();
// wrapper.eq("id","1485561295984947211");
wrapper.eq("commodity_name","商品189");
TbCommodityInfo tbCommodityInfo = tbCommodityInfoMapper.selectOne(wrapper);
System.out.println(tbCommodityInfo);
}
缺点
尽管主从复制、读写分离能很大程度保证MySQL服务的高可用和提高整体性能,但是问题也不少:
- 从机是通过binlog日志从master同步数据的,如果在网络延迟的情况,从机就会出现数据延迟。那么就有可能出现master写入数据后,slave读取数据不一定能马上读出来。
可能有人会问,有没有事务问题呢?
实际上这个框架已经想到了,我们看回之前的那个截图,有一句话是这样的:

目前查询好像一直都是查询slave0,不过配置随机访问是正常的:RANDOM
现在不确定是代码的bug还是配置出现问题。