一.实现思路
本文讲解如何使用python实现一个简单的模板引擎, 支持传入变量, 使用if判断和for循环语句, 最终能达到下面这样的效果:
渲染前的文本: <h1>{{title}}</h1> <p>十以内的奇数:</p> <ul> {% for i in range(10) %} {% if i%2==1 %} <li>{{i}}</li> {% end %} {% end %} </ul> 渲染后的文本,假设title="高等数学": <h1>高等数学</h1> <p>十以内的奇数:</p> <ul> <li>1</li> <li>3</li> <li>5</li> <li>7</li> <li>9</li> </ul>
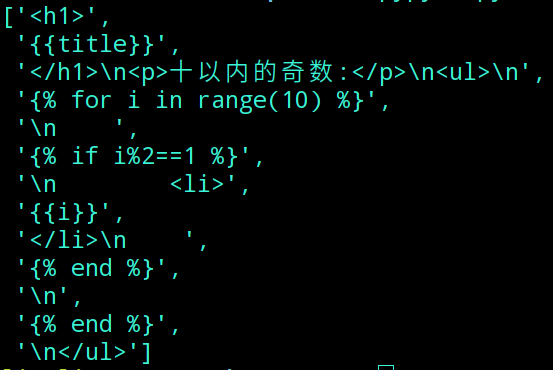
要实现这样的效果, 第一步就应该将文本中的html代码和类似{% xxx %}这样的渲染语句分别提取出来, 使用下面的正则表达式可以做到:
re.split(r'(?s)({{.*?}}|{%.*?%}|{#.*?#})', html)
用这个正则表达式处理刚才的文本, 结果如下:
在提取文本之后, 就需要执行内部的逻辑了. python自带的exec函数可以执行字符串格式的代码:
exec('print("hello world")') # 这条语句会输出hello world
因此, 提取到html的渲染语句之后, 可以把它改成python代码的格式, 然后使用exec函数去运行. 但是, exec函数不能返回代码的执行结果, 它只会返回None. 虽然如此, 我们可以使用下面的方式获取字符串代码中的变量:
global_namespace = {} code = """ a = 1 def func(): pass """ exec(code, global_namespace) print(global_namespace) # {'a': 1, 'func': <function func at 0x00007fc61e3462a0>, '__builtins__': <module 'builtins' (built-in)>}
因此, 我们只要在code这个字符串中定义一个函数, 让它能够返回渲染后的模板, 然后使用刚才的方式把这个函数从字符串中提取出来并执行, 就能得到结果了.
基于上面的思路, 我们最终应该把html文本转化为下面这样的字符串:
# 这个函数不是我们写的, 是待渲染的html字符串转化过来的 def render(context: dict) -> str: result = [] # 这一部分负责提取所有动态变量的值 title = context['title'] # 对于所有的html代码或者是变量, 直接放入result列表中 result.extend(['<h1>', str(title), '</h1> <p>十以内的奇数:</p> <ul> ']) # 对于模板中的for和if循环语句,则是转化为原生的python语句 for i in range(10): if i % 2 == 1: result.extend([' <li>', str(i), '</li> ']) result.append(' </ul>') # 最后,让函数将result列表联结为字符串返回就行, 这样就得到了渲染好的html文本 return ''.join(result)
如何将html文本转化为上面这样的代码, 是这篇文章的关键. 上面的代码是由最开始那个html demo转化来的, 每一块我都做了注释. 如果没看明白的话, 就多看几遍, 不然肯定是看不懂下文的.
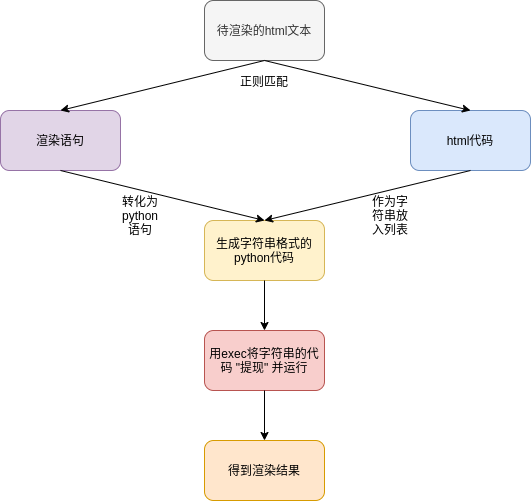
总的来说, 要渲染一个模板, 思路如下:
二.字符串代码
为了能够方便地生成python代码, 我们首先定义一个CodeBuilder类:
class CodeBuilder: INDENT_STEP = 4 def __init__(self, indent_level: int = 0) -> None: self.indent_level = indent_level self.code = [] self.global_namespace = None def start_func(self) -> None: self.add_line('def render(context: dict) -> str:') self.indent() self.add_line('result = []') self.add_line('append_result = result.append') self.add_line('extend_result = result.extend') self.add_line('to_str = str') def end_func(self) -> None: self.add_line("return ''.join(result)") self.dedent() def add_section(self) -> 'CodeBuilder': section = CodeBuilder(self.indent_level) self.code.append(section) return section def __str__(self) -> str: return ''.join(str(line) for line in self.code) def add_line(self, line: str) -> None: self.code.extend([' ' * self.indent_level + line + ' ']) def indent(self) -> None: self.indent_level += self.INDENT_STEP def dedent(self) -> None: self.indent_level -= self.INDENT_STEP def get_globals(self) -> dict: if self.global_namespace is None: self.global_namespace = {} python_source = str(self) exec(python_source, self.global_namespace) return self.global_namespace
这个类作为字符串代码的容器使用, 它的本质是对字符串代码的封装, 在字符串的基础上增加了以下的功能:
- 代码缩进
CodeBuilder维护了一个indent_level变量, 当调用它的add_line方法写入新代码的时候, 它会自动在代码开头加上缩进. 另外, 调用indent和dedent方法就能方便地增加和减少缩进.
- 生成函数
由于定义这个类的目的就是在字符串里面写一个函数, 而这个函数的开头和结尾都是固定的, 所以把它直接写到对象的方法里面. 值得一提的是, 在start_func这个方法中, 我们写了这样三行代码:
append_result = result.append extend_result = result.extend to_str = str
这样做是为了提高渲染模板的性能, 调用我们自己定义的函数, 需要的时间比调用result.append或者str等函数的时间少. 首先对于列表的append和extend两个方法来说, 每调用一次, python都需要在列表中的所有方法中找一次, 而直接把它绑定到我们自己定义的变量上, 就能避免python重复地去列表的方法中来找. 然后是str函数, 理论上, python查找局部变量的速度比查找内置变量的快, 因此我们使用一个局部变量to_str, python找到它的速度就比找str要快.
上面这段话都是我从网上看到的, 实际测试了一下, 在python3.7上, 运行append_result需要的时间比直接调用result.append少了大约25%, to_str则没有明显的优化效果.
- 代码嵌套
有的时候我们需要在一块代码中嵌套另外一块代码, 这时候可以调用add_section方法, 这个方法会创建一个新的CodeBuilder对象作为内容插入到原CodeBuilder对象里面, 这个和前端的div套div差不多.
这个方法的好处是, 你可以在一个CodeBuilder对象中预先插入一个CodeBuilder对象而不用写入内容, 相当于先占着位置. 等条件成熟之后, 再回过头来写入内容. 这样就增加了字符串代码的可编辑性.
- 获取变量
调用get_globals方法获取当前字符串代码内的所有全局变量.
三.Template模板
在字符串代码的容器做好之后, 我们只需要解析html文本, 然后把它转化为python代码放到这个容器里面就行了. 因此, 我们定义如下的Template类:
class Template: html_regex = re.compile(r'(?s)({{.*?}}|{%.*?%}|{#.*?#})') valid_name_regex = re.compile(r'[_a-zA-Z][_a-zA-Z0-9]*$') def __init__(self, html: str, context: dict = None) -> None: self.context = context or {} self.code = CodeBuilder() self.all_vars = set() self.loop_vars = set() self.code.start_func() vars_code = self.code.add_section() buffered = [] def flush_output() -> None: if len(buffered) == 1: self.code.add_line(f'append_result({buffered[0]})') elif len(buffered) > 1: self.code.add_line(f'extend_result([{", ".join(buffered)}])') del buffered[:] strings = re.split(self.html_regex, html) for string in strings: if string.startswith('{%'): flush_output() words = string[2:-2].strip().split() ops = words[0] if ops == 'if': if len(words) != 2: self._syntax_error("Don't understand if", string) self.code.add_line(f'if {words[1]}:') self.code.indent() elif ops == 'for': if len(words) != 4 or words[2] != 'in': self._syntax_error("Don't understand for", string) i = words[1] iter_obj = words[3] # 这里被迭代的对象可以是一个变量,也可以是列表,元组或者range之类的东西,因此使用_variable来检验 try: self._variable(iter_obj, self.all_vars) except TemplateSyntaxError: pass self._variable(i, self.loop_vars) self.code.add_line(f'for {i} in {iter_obj}:') self.code.indent() elif ops == 'end': if len(words) != 1: self._syntax_error("Don't understand end", string) self.code.dedent() else: self._syntax_error("Don't understand tag", ops) elif string.startswith('{{'): expr = string[2:-2].strip() self._variable(expr, self.all_vars) buffered.append(f'to_str({expr})') else: if string.strip(): # 这里使用repr把换行符什么的改成/n的形式,不然插到code字符串中会打乱排版 buffered.append(repr(string)) flush_output() for var_name in self.all_vars - self.loop_vars: vars_code.add_line(f'{var_name} = context["{var_name}"]') self.code.end_func() def _variable(self, name: str, vars_set: set) -> None: # 当解析html过程中出现变量,就调用这个函数 # 一方面检验变量名是否合法,一方面记下变量名 if not re.match(self.valid_name_regex, name): self._syntax_error('Not a valid name', name) vars_set.add(name) def _syntax_error(self, message: str, thing: str) -> None: raise TemplateSyntaxError(f'{message}: {thing}') # 这个Error类直接继承Exception就行 def render(self, context=None) -> str: render_context = dict(self.context) if context: render_context.update(context) return self.code.get_globals()['render'](render_context)
首先, 我们实例化了一个CodeBuilder对象作为容器使用. 在这之后, 我们定义了all_vars和loop_vars两个集合, 并在CodeBuilder生成的函数开头插了一个子容器. 这样做的目的是, 最终生成的函数应该在开头添加类似 var_name = context['var_name']之类的语句, 来提取传入的上下文变量的值. 但是, html中有哪些需要渲染的变量, 这是在渲染之后才知道的, 所以先在开头插入一个子容器, 并创建all_vars这个集合, 以便在渲染html之后把这些变量的赋值语句插进去. loop_vars则负责存放那些由于for循环产生的变量, 它们不需要从上下文中提取.
然后, 我们创建一个bufferd列表. 由于在渲染html的过程中, 变量和html语句是不需要直接转为python语句的, 而是应该使用类似 append_result(xxx)这样的形式添加到代码中去, 所以这里使用一个bufferd列表储存变量和html语句, 等渲染到for循环等特殊语句时, 再调用flush_output一次性把这些东西全写入CodeBuilder中. 这样做的好处是, 最后生成的字符串代码可能会少几行.
万事具备之后, 使用正则表达式分割html文本, 然后迭代分割结果并处理就行了. 对于不同类型的字符串, 使用下面的方式来处理:
- html代码块
只要有空格和换行符之外的内容, 就放入缓冲区, 等待统一写入代码
- 带的{{}}的变量
只要变量合法, 就记录下变量名, 然后和html代码块同样方式处理
- if条件判断 & for循环
这两个处理方法差不多, 首先检查语法有无错误, 然后提取参数将其转化为python语句插入, 最后再增加缩进就行了. 其中for语句还需要记录使用的变量
- end语句
这条语句意味着for循环或者if判断结束, 因此减少CodeBuilder的缩进就行
在解析完html文本之后, 清空bufferd的数据, 为字符串代码添加变量提取和函数返回值, 这样代码也就完成了.
四.结束
最后, 实例化Template对象, 调用其render方法传入上下文, 就能得到渲染的模板了:
t = Template(html) result = t.render({'title': '高等数学'})