本篇文章主要是对asyncio和相关内容的补充, 以及一个异步爬虫实例. 这个系列还有另外两篇文章:
一. 使用同步代码
上一篇文章已经讲到, 使用asyncio模块的基本套路是, 把要执行的代码写成协程函数的形式, 在函数内部IO操作的部分使用await挂起任务. 最后将协程给asyncio运行即可.
假设现在需要使用requests库请求数据:
import requests def fetch(url): response = requests.get(url) # 以下省略一万字
显然, 对一个url的get请求属于耗时的IO操作, 但是requests是个同步库, 没法await, 如果直接以同步的方式运行, 那么又不能发挥出异步的效率优势.
这种必须使用同步代码的情况下, 可以这样做:
import asyncio import requests async def fetch(url): loop = asyncio.get_running_loop() asyncIO = loop.run_in_executor(None, requests.get, url) response = await asyncIO # 继续省略一万字
loop就是当前线程运行的事件循环, 调用它的run_in_execcutor方法, 可以将一个同步代码的函数封装为future对象, 然后就可以对其await了.
这个方法接受三个参数: executor, func和*args, 其中executor为线程池或者进程池(concurrent.futures.ThreadPoolExecutor&ProcessPoolExecutor), 如果传入None则使用默认的线程池. func和*args就是同步函数以及对应的参数. 这个方式的本质是将同步代码放在其它的线程或者进程运行, 来避免其阻塞主线程, 故只是权宜之计.
目前已经有越来越多支持asyncio的异步库, 比如上面说的requests库, 就可以用aiohttp来替代. 在https://github.com/timofurrer/awesome-asyncio可以找到支持用asyncio异步的库.
二. async语句的其它用法
async除了用于定义协程函数外, 另两种用法是async with和async for, 这两种语句和await一样有异步属性, 必须在协程函数内使用.
1. async with
async with和with类似, async with的对象应该实现__aenter__和__aexit__方法, 并且这两个方法是异步的.
一个简单的async with实例如下:
import asyncio class Lock: def __init__(self): self._locked = False async def __aenter__(self): while self._locked: await asyncio.sleep(0) self._locked = True return self async def __aexit__(self, exc_type, exc, tb): self._locked = False lock = Lock() async def coro(): async with lock: pass asyncio.run(coro())
这里实现了一个简单的协程锁, 其中__aenter__和__aexit__方法分别用于请求和释放锁.
2. async for
async for也和for类似, 后面接的迭代对象需要实现__aiter__和__anext__两个方法, 其中__anext__方法是异步的.
一个简单的async for实例如下:
import asyncio class Xrange: def __init__(self, lower, upper): self._num = lower-1 self.upper = upper def __aiter__(self): return self async def __anext__(self): self._num += 1 if self._num < self.upper: return self._num raise StopAsyncIteration async def coro(): async for i in Xrange(1, 10): print(i) asyncio.run(coro())
需要注意的是, 要在__anext__方法中迭代结束的位置引发StopAsyncIteration, 否则这个对象就会永远迭代下去.
三. 协程补充
1. coro.throw()
coro.throw(type, value=None, traceback=None)
class Awaitable: def __await__(self): yield async def coro(): while 1: aw = Awaitable() await aw c = coro() # 如果不预先激活协程就直接调用throw,那么throw方法就会在async def coro这一行引发异常 c.send(None) c.throw(Exception, 'haha')
运行结果如下:
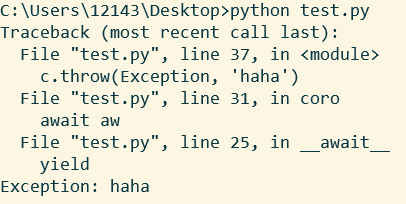
如果一个协程没有被激活, 那么调用throw, 就会直接在定义协程的那个位置抛出异常, 否则, 协程卡在哪个yield, 就在那个位置抛出异常. 当然, 协程也可以在内部捕获这个异常.
除此之外, 其实throw和send是相似的, 二者都会获得yield返回的值. 并且, throw和send一样会驱动协程, 前提是协程能捕获到这个异常而不退出.
2. coro.close()
close函数用于关闭协程, 使之完全停止. 这个函数其实是使用了throw函数, 伪码如下:
def close(self): try: self.throw(GeneratorExit) except (GeneratorExit, StopIteration): pass else: raise RuntimeError("generator ignored GeneratorExit")
其中GeneratorExit继承自BaseException, 也是异常的一种. 因此, close方法其实就是通过往协程内部扔异常的方式让协程停止, 如果这个协程执意要捕获异常而不停止的话, close方法就会抛出RuntimeError.
四. task/future补充
上一篇文章讲过, future用在协程内部, 主要特性就是暂停和回调:
- 协程在这个位置暂停和切换, 因此可用于IO操作
- 在协程被task封装的前提下, 调用set_result就等于结束本次暂停, 并将set_result的值返回给协程
- 可以设置回调函数, 当暂停结束的时候调用回调
task继承自future, 性质和future差不多, 另外还负责封装和驱动协程.
1.task&future的创建与鉴别
鉴别一个对象是不是task&future, 可以调用asyncio.isfuture, 这个函数会返回一个布尔值. 相应的, 调用asyncio.iscoroutine和asyncio.iscoroutinefunction就可以判断协程对象和协程函数.
如果要创建task或者future对象, 可以调用以下函数;
# 要把协程封装为task对象,可以使用以下两个函数: # 这个函数必须在有事件循环运行时调用,不然报错 # 一般来说,在协程中调用就行 asyncio.create_task(coro) # 这个函数不光可以接收协程对象,只要是可等待对象都可以 # 如果没有事件循环, 它就会调用get_event_loop获取 asyncio.ensure_future(aw) # 或者在获取到当前事件循环的前提下 loop.create_task() # 如果要创建future对象,可以使用以下方法: asyncio.Future() # 或者在获取到当前事件循环的前提下 loop.create_future()
2.取消task&future
task&future有pending, 和done两种状态, 其中done又可以再分为finished和cancelled. 简单来说, 还能运行就是pending, 正常结束就是finished. 被取消了就是cancelled, 调用cancel方法就可以取消一个task&future对象.
现在使用如下代码取消一个future对象:
import asyncio loop = asyncio.get_event_loop() async def coro(): fut = loop.create_future() def cb(fut): print('这是一个回调函数') fut.add_done_callback(cb) # 在一秒之后取消fut loop.call_later(1, fut.cancel) try: await fut except Exception as e: print('异常:', type(e)) print('future对象:', fut) loop.run_until_complete(coro())
运行结果如下:

首先, cancel方法会处理所有的回调函数, 这一点和set_result方法是一样的. 在这之后, future.__await__方法内部会引发CancelledError, 如果协程不捕获的话, 这整个协程就停止了. 最后可以看到, fut对象的状态变为cancelled. 简单点说, 就是首先处理回调函数, 然后往协程里面throw一个CancelledError使之结束.
task的cancel方法与future类似, 首先处理回调函数, 然后调用future.cancel来取消协程.
五. 事件循环
上一篇中讲过了, 事件循环相当于一个调度者, 对多个task进行管理, 当触发到事件时, 就驱动对应的task运行.
1. 获取和设置事件循环
使用以下函数获取或者设置事件循环:
# 如果没有正在运行的事件循环, 下面这个函数会报错 # 因此, 只能在协程或者相关的回调中调用这个函数 asyncio.get_running_loop() # 获取事件循环, 没有就会新建一个 asyncio.get_event_loop() # 新建一个事件循环 asyncio.new_event_loop() # 将loop绑定到当前的线程中 asyncio.set_event_loop(loop)
事件循环对象绑定了很多方法, 主要是运行回调, 网络通信等方面的, 可以看https://docs.python.org/zh-cn/3/library/asyncio-eventloop.html.
2. 令人迷惑的点
不论是future还是task, 都需要依赖事件循环来调度. 显然, 在一个线程只需要一个事件循环, 否则会造成程序混乱.
现在运行下面这段程序:
import asyncio loop = asyncio.get_event_loop() async def coro(): fut = loop.create_future() loop.call_later(1, fut.set_result, None) await fut print('the end') asyncio.run(coro())
运行结果如下:
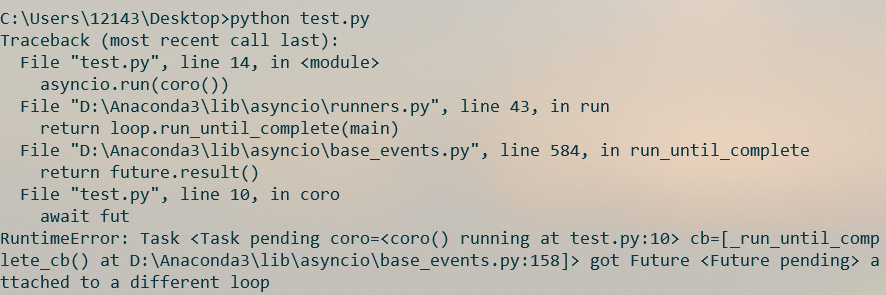
这是因为, asyncio.run会创建一个事件循环A来运行传入的协程对象, 但是, 这个协程自身又通过事件循环B来创建了一个future对象, 那么这个future对象就绑定到事件循环B上去了, 这就导致程序的混乱和错误.
如果要避免这种情况, 可以采取以下两种措施;
- 首先, 尽量使用asyncio.get_running_loop而非asyncio.get_event_loop, 这样能确保获取的事件循环就是当前运行的那个
- 然后, 如果调用的API可以接收loop参数, 就传入loop参数以保证事件循环的一致性. 我统计了一下, asyncio模块的task.py共定义了42个函数, 其中有14个函数能接收loop参数.
六. asyncio.wait&asyncio.gather
之前讲过, 如果要同时运行多个协程, 可以使用asyncio.wait将其打包, 其实asyncio中还有一个效果类似的函数, 即asyncio.gather.
1. wait&gather的实现原理
import asyncio
def gather(*coros): def _done_callback(fut): nonlocal nfinished nfinished += 1 if nfinished == nfuts: results = [] for fut in children: res = fut.result() results.append(res) outer.set_result(results) nfuts = 0 nfinished = 0 children = [] for c in coros: fut = asyncio.create_task(c) fut.add_done_callback(_done_callback) children.append(fut) nfuts = len(children) outer = _GatherFuture(children) return outer class _GatherFuture(asyncio.Future): ''' 这个future类是gather函数的辅助 如果调用它的cancel方法, 就会把所有的子协程都取消 ''' def __init__(self, children): super().__init__() self._children = children def cancel(self): if self.done(): return False ret = False for child in self._children: if child.cancel(): ret = True return ret async def wait(fs): fs = {asyncio.create_task(f) for f in set(fs)} loop = asyncio.get_running_loop() waiter = loop.create_future() counter = len(fs) def _on_completion(f): nonlocal counter counter -= 1 if counter <= 0: waiter.set_result(None) for f in fs: f.add_done_callback(_on_completion) await waiter done, pending = set(), set() for f in fs: f.remove_done_callback(_on_completion) if f.done(): done.add(f) else: pending.add(f) return done, pending
2. wait&gather的使用差异
# coros是一个包含了多个协程的可迭代对象, 比如一个协程列表 asyncio.wait(coros) # 如果使用gather,应该用以下两种方式传参 asyncio.gather(*coros) asyncio.gather(coro1,coro2,coro3)
然后, wait是一个协程函数, 因此直接调用会返回一个协程对象, 可以使用asyncio.run运行. 但是gather则是返回一个future对象, 因此与asyncio.run不兼容:
# run收到的参数是一个协程,没毛病 asyncio.run(asyncio.wait(coros)) # run收到一个future对象,因此下面这句话会报错 asyncio.run(asyncio.gather(*coros)) # 如果要运行gather打包的协程, 可以用以下两种方式: loop = asyncio.get_event_loop() loop.run_until_complete(asyncio.gather(*coros)) # 或者 async def main(): res = await asyncio.gather(*coros) asyncio.run(main())
另一方面, 由于gather函数返回的是一个future对象, 因此可以对其调用cancel方法来提前结束, 此时gather内所有的协程都会被取消.
最后, 由上面的代码可知, 二者的完成时的返回值有差异, wait会返回done和pending两个集合, 即已完成和未完成的协程集合, 而gather则是直接把协程的结果放在列表中返回.
async def func(coros): # wait会返回两个集合, 分别存放coros中已完成和未完成的协程 done_coros, pending_coros = await asyncio.wait(coros) # gather则是直接把协程的结果放在一个列表中返回 results = await asyncio.gather(*coros)
3. wait&gather函数的附加功能
wait和gather函数的附加功能主要体现在其附加的参数上.
wait可以设置timeout和return_when两个参数, 从而让wait函数提前结束, 这时未完成的协程就会被放入pending这个集合中返回. 不过, wait并不会将这些未完成的协程取消掉.
import asyncio import concurrent.futures # return_when只能设置以下三个值, 不然会报错 concurrent.futures.FIRST_COMPLETED # 在有一个协程结束时返回 concurrent.futures.FIRST_EXCEPTION # 在有一个协程抛出异常时返回 concurrent.futures.ALL_COMPLETE # 在所有协程都结束时返回, 这是默认值 async def main(coros): # timeout表示几秒后返回, 不设置则不起作用 done, pending = await asyncio.wait(coros, timeout=3, return_when=concurrent.futures.FIRST_COMPLETED)
需要注意的是, 就算将return_when设置为FIRST_COMPLETED, 如果多个协程的完成时间相近, 那么这几个协程可能都会被放到done集合中. FIRST_EXCEPTION同理.
gather可以设置return_exceptions这个参数, 其默认值为False, 如果设置为True, 那么协程在运行中的错误将不会直接抛出, 而是将错误信息作为返回结果, 存入最后返回的结果列表中.


按照python官方文档的说法, 从python3.8开始, wait函数不会将传入的协程封装为task对象, 也就是说, 在将协程传入wait函数之前, 应该先调用asyncio.create_task方法将协程转化为task对象. 详细说明可以看https://docs.python.org/zh-cn/3/library/asyncio-task.html?highlight=asyncio%20wait#asyncio.wait. 但是, 我今天特地安装了一个python3.8进行测试, 发现并没有这回事, 传一个协程列表给wait, 程序还是可以正常运行. 而且wait内部的代码也没改, 还是会调用ensure_future将协程封装成task对象. 总之, 这里还是注意一下吧, 指不定哪天就变了. 今天是2020-1-7.
七. 一个简单的爬虫实例
以https://xkcd.com/这个网站为例, 这是一个漫画网站, 每张漫画对应的页面是https://xkcd.com/int/, 其中int为1-2244之间的整数. 现在从网站上下载一百张漫画, 代码如下:
import asyncio import os import random import re import time import aiofiles import aiohttp class Producer: def __init__(self, session, queue): self.session = session self.regex = re.compile( '''<div id="comic"> <img src="(//imgs.xkcd.com/comics/[a-z0-9_]+.(jpg|png))"''') self.q = queue self.urls = self.url_factory() async def start(self): workers = [self.worker() for i in range(10)] await asyncio.wait(workers) self.q.put_nowait('all tasks are done') async def worker(self): while self.urls: url = self.urls.pop() html = await self.fetch(url) await self.pares_html(html) def url_factory(self, n=100): # 返回一个含有n个url的集合 urls = set() while len(urls) < n: urls.add('https://xkcd.com/{}/'.format(random.randrange(1, 2245))) return urls async def fetch(self, url): async with self.session.get(url) as response: assert response.status == 200 return await response.text() async def pares_html(self, html): res = re.search(self.regex, html) if res is None: return img_url = 'https:'+res.group(1) await self.q.put(img_url) class Consumer: def __init__(self, session, queue): self.session = session self.q = queue self.save_folder = os.path.join(os.path.dirname(__file__), 'webcomics') try: os.mkdir(self.save_folder) except FileExistsError: pass async def start(self): workers = [self.worker() for i in range(10)] await asyncio.wait(workers) async def worker(self): while 1: url = await self.q.get() if url == 'all tasks are done': break await self.download(url) self._on_worker_done() def _on_worker_done(self): self.q.put_nowait('all tasks are done') async def download(self, url): filename = os.path.split(url)[-1] save_path = os.path.join(self.save_folder, filename) if os.path.exists(save_path): return async with self.session.get(url) as response: assert response.status == 200 content = await response.read() async with aiofiles.open(save_path, 'wb') as f: await f.write(content) async def main(): queue = asyncio.Queue(maxsize=100) async with aiohttp.ClientSession() as session: producer = Producer(session, queue) consumer = Consumer(session, queue) tasks = asyncio.gather(producer.start(), consumer.start()) await tasks if __name__ == '__main__': asyncio.run(main())
这段代码主要分为两部分: producer和consumer, 即生产者和消费者. 生产者负责生成图片下载链接, 消费者则处理这些链接, 将对应的图片下载到本地.
1. producer代码解析
首先, producer需要两个参数, session和queue. session是连接池, 其特点是结束之后, 对应的连接不会断开, 下次需要同一个目标的连接时, 直接使用上次未断开的连接, 也就是实现了tcp连接的重复使用. 由于本次连接的目标都是同一个网站, 因此使用连接池可以减少创建和断开tcp连接的开销(三次握手, 四次挥手). queue则是队列, 生产者产生图片下载链接之后, 不直接交给消费者, 而是放在队列中让消费者自取. 这样二者不是同步的, 效率低的一方不会阻塞到效率高的另一方.
producer的工作策略是, 首先产生好100个网页链接存在self.urls这个列表中, 然后让worker不断从集合中取出url. worker方法首先调用fetch方法获取到对应的html, 然后调用parse_html提取html中的图片链接, 将图片链接储存到队列中.
这段代码并不算复杂, 需要注意的有三点.
- 首先, producer调用start方法开始工作, 这个方法创建了10个worker协程, 相当于最大并发数为10. 之所以只创建10个协程, 一方面是因为爬取的数量不多, 没必要爬太狠, 一方面是创建过多的tcp连接, 也会造成较大的开销(虽然连接池有tcp复用机制, 但是多个协程同时在爬, 每个协程都需要一个tcp连接). 如果要限制协程的并发量, 除了限制创建协程的数量之外, 还可以使用信号量的方式, 这部分可以在asyncio的高级api中找到, 用法比较简单.
- 然后, 这里worker从self.urls中取值的方式是直接取, 这里不需要担心线程安全问题, 因为协程只会在指定的位置, 比如await时切换到其它协程, 也就是说, 从self.urls中取值这一操作是原子性的.
2. consumer代码解析
consumer类的代码与producer相似, 本身也不算复杂, 主要变化就是把fetch换成download, 将请求的数据直接写入本地的图片文件. 值得讲讲的就是这里停止消费者的机制:
- 由于本次只爬取100张图片, 所以爬取结束之后, 消费者应该停止. 这里停止消费者的机制是, 生产者结束后, 往队列中放 "all tasks are done" 这一语句来通知消费者, 消费者的某个worker收到这一消息后, 就停止, 并将这一消息再放入队列来通知其它worker, 从而让所有worker都停止.
如果要停止消费者, 另外一个方式是使用asyncio.Queue自带的join方法. 首先, 将 "all tasks are done" 这一机制删除, 然后, 将start和worker方法的代码修改如下:
async def start(self): workers = [asyncio.Task(self.worker()) for i in range(10)] await self.q.join() for worker in workers: worker.cancel() async def worker(self): while 1: url = await self.q.get() await self.download(url) self.q.task_done()
asyncio.Queue内部带有一个future对象和一个_unfinished_tasks计数, 当往队列添加数据时, _unfinished_tasks+1, 调用task_done方法时, _unfinished_tasks-1, 并且如果此时_unfinished_task为0, 就调用future对象的set_result方法.
这种停止机制的关键就在于队列: 调用队列的join方法会返回队列的future对象, 因此, await self.q.join()这句话实际是在等待future对象结束. start方法首先用asyncio.Task对worker进行封装, 使其开始运行. worker每从队列中取出一个url并下载图片, 就调用一次task_done. 这样队列为空时, 队列的future对象就结束了, 于是start协程再反过来将worker协程取消.
这种方法的问题是, 首先, 这里的生产者和消费者是同时运行的, 当生产者没有产生数据之前, 队列为空, 此时消费者就会直接结束. 然后, 如果生产者效率比消费者低很多, 在生产中途出现了队列为空的情况, 此时消费者也可能提前结束, 因此这种方法更适用于消费者消费队列中已有数据的场景, 在这里不适用.
在使用爬虫获取网站内容之前, 应该先查看这个网站的robots协议, 该协议放在root_url/robots.txt, 比如https://xkcd.com/的robots协议可以在https://xkcd.com/robots.txt看到. 这个协议规定了允许的爬虫和可以爬取的目录. 比如: User-agent: * Disallow: /personal/ 表示任何爬虫都可以爬, 但是不能爬取/personal/目录下的内容.