这篇文章主要是介绍生成器和IO多路复用机制, 算是学习asyncio需要的预备知识. 这个系列还有另外两篇文章:
一. 简单爬虫实例
首先创建一个crawler.py文件, 写入以下代码:
import socket req = 'GET / HTTP/1.0 Host:cn.bing.com '.encode('utf8') address = ('cn.bing.com', 80) db = [] def simple_crawler(): sock = socket.socket() sock.connect(address) sock.send(req) response = b'' while 1: chunk = sock.recv(1024) if chunk == b'': sock.close() break else: response += chunk db.append(response) if __name__ == '__main__': print('开始爬取...') simple_crawler() print('获取到{}条数据'.format(len(db)))
运行crawler.py文件, 结果如下:

其中, simple_crawler函数做了如下几件事:
- 创建一个socket对象
- 连接服务器
- 向服务器发送http请求
- 接收服务端的响应内容
- 处理和储存响应内容
通过这五个步骤, 我们实现了一个最基本的爬虫实例.


这里的请求之所以使用HTTP1.0协议, 是因为HTTP1.0默认不是长连接, 服务器在发送完数据后会自己断开. 因此当socket接收到空字节的时候, 就说明服务器已经断开了, 也就是说数据已经接收完了.
如果要使用HTTP1.1协议, 那么在请求头中加上Connection:close就行.
二. IO操作
1. 爬虫实例中的耗时操作
首先测试一下simple_crawler获取一次数据的用时:
import time print('开始爬取...') start=time.time() simple_crawler() print('获取到{}条数据'.format(len(db))) print('本次用时:{:.2f}秒'.format(time.time()-start))
运行几次crawler.py文件, 结果如下:
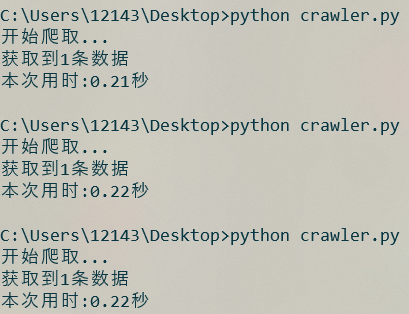
相比计算机的计算速度而言, 这段代码的运行速度是相当慢的, 如果现在需要获取100个数据, 那么就需要大约三分半钟的时间.
现在修改一下crawler.py的代码, 看看各个步骤的执行时间:
import socket import time req = 'GET / HTTP/1.0 Host:cn.bing.com '.encode('utf8') address = ('cn.bing.com', 80) db = [] def simple_crawler(): print('开始运行',time.time()) sock = socket.socket() print('已创建socket对象',time.time()) sock.connect(address) print('已连接服务器',time.time()) sock.send(req) print('已发送请求',time.time()) response = b'' while 1: chunk = sock.recv(1024) if chunk == b'': sock.close() break else: response += chunk print('已接收响应',time.time()) db.append(response) print('已处理响应',time.time()) if __name__ == '__main__': simple_crawler()
代码运行结果如下:

可以看到, 在这个程序中, 创建socket对象, 发送http请求, 处理响应结果, 基本都是不耗时的, 耗时操作在于连接服务器和接收响应.
socket对象的send方法只是将数据写入到内核态, 由系统将数据发送到服务器. 因此, 如果socket对应的内核位置的可写缓冲区还没装满, 并且还能装下本次send的数据, 就不会阻塞, 否则, send操作也会是阻塞的.
2. 阻塞IO
现在运行下面一段代码:
input('按回车退出>>>') exit()
显然, 如果不按回车或者ctrl+c, 程序就会一直卡在input这一行. 在这段时间, 程序没有做任何事, 只是单纯地等待用户按回车而已, 就像下面这张图:

IO的全称是input/output, 即向/从计算机传输数据的操作, 在针对文件和网络操作中比较常见. 其特点是需要花费一定的等待时间才能完成操作, 上一节的代码中, sock.connect和sock.recv就是IO操作, 花费了大量的时间在等待服务器响应上, 因此用时较长.
一般情况下, 这些基本的IO操作是阻塞式的, 也就是程序会卡在等待的期间, 直到IO操作完成. 比如input语句, 在用户按下回车之前, 程序处于'死机'状态.
3. 非阻塞IO
现在运行如下代码:
import socket import time sock = socket.socket() sock.setblocking(0) print('开始连接服务器', time.time()) try: sock.connect(('cn.bing.com', 80)) except BlockingIOError: pass print('完成连接服务器', time.time())
然后运行:

可以看到, 原本耗时的连接操作变得不耗时了.
调用socket对象的setblocking方法, 传入False, 就可以将这个socket对象设置为非阻塞式的, 这时再调用该对象涉及到IO操作的方法, 程序将不会阻塞, 但如果操作不能立即完成, 就会抛出异常.
现在将刚才写的爬虫改为非阻塞的形式:
import socket req = 'GET / HTTP/1.0 Host:cn.bing.com '.encode('utf8') address = ('cn.bing.com', 80) db = [] def noblocking_crawler(): sock = socket.socket() sock.setblocking(0) # connect_ex与connect类似,但在这种情况下不会抛出异常,而是返回错误码 # 因此,这里使用connect_ex来省略一个try语句 sock.connect_ex(address) while 1: try: sock.send(req) break except OSError: pass response = b'' while 1: try: chunk = sock.recv(1024) if chunk == b'': sock.close() break else: response += chunk except BlockingIOError: pass db.append(response) if __name__ == '__main__': print('开始爬取...') noblocking_crawler() print('获取到{}条数据'.format(len(db)))
非阻塞式IO并非意味着不需要等待时间, 而是说程序不会卡在这里, 但这并不代表IO操作的等待时间会消失. 因此, 在使用connect方法之后, 需要在while循环中一直重复send, 如果捕获到OSError异常, 就说明还没有连接成功, 也就是IO操作还未结束, 于是继续循环, 直到IO结束为止. 这一部分的流程如下:

recv方法同理.
对函数的运行时间进行测试, 会发现耗时并没有减少, 这是因为IO操作中的等待时间并不会消失. 因此, 单纯将程序设置为非阻塞并不能提高效率, 只有利用等待时间执行其它任务, 程序的整体效率才会提高.
三. 生成器
在上一节中, 非阻塞IO之所以没有体现出优势, 是因为没有利用好IO操作的等待时间去执行其他程序. 假如现在有ABC三个任务, 而有一种机制, 能让任务A遇到IO操作时, 切换到任务B, 任务B遇到IO操作时, 再切换到任务C, 最后就可以充分利用IO操作的等待时间, 从而提升程序的整体运行效率.
定义一个如下函数:
def gen(): print('这里是gen函数内部, 现在执行step1') yield print('这里是gen函数内部, 现在执行step2') yield print('这里是gen函数内部, 现在执行step3') return
现在查看这个函数的返回值:
g = gen() print(type(g))
结果如下:

在函数中加入yield语句后, 调用这个函数, 函数内的语句就不会执行, 而是返回一个generator对象, 即生成器.
如果想执行这个函数内部的语句, 可以调用python内置的next函数对生成器进行驱动:
g = gen() for i in range(1, 4): print('这里是gen函数外部,现在是第%s次驱动生成器' % i) next(g)
结果如下:
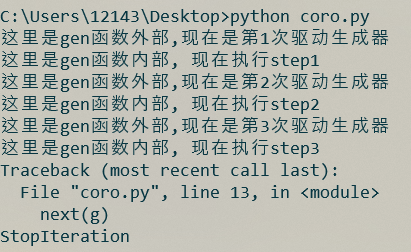
对于生成器, 在外部调用next对其驱动, 就能执行其内部的代码, 如果执行到yield语句, 就会切换回外部, 下次再驱动, 会从上次结束的地方继续. 程序的执行流程如下:
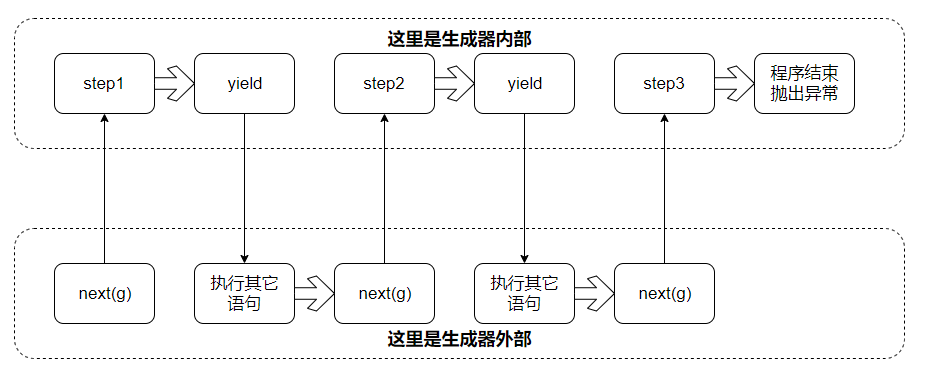
只要调用next函数驱动生成器, 程序就会切换到生成器的内部, 从上次停下来的位置开始继续运行, 运行过程中如果遇到yield语句, 再切换回调用next函数的位置. 因此, 使用next和yield, 就可以方便地在不同程序中来回切换. 需要注意的是, 如果生成器内部的程序执行结束, 会抛出StopIteration异常.
这样看来, 生成器就满足了我们的需求: 即在不同的程序之间切换, 对于一个任务, 在IO操作的时候使用yield语句切换到其它任务, 然后在特定时间再用next函数切换回来, 这样就能利用IO操作的等待时间.
yield语句除了能暂停程序的执行外, 它还是个生成器内部与外部的双向通道. 需要向外部传值时, yield的用法等于return; 如果要向生成器内部传值, 那么就在生成器内部写成a=yield的形式, 然后在外部调用生成器的send方法将值传给a(此方法同时会驱动生成器) 举个例子: def gen(): first_sentence = '天王盖地虎' second_sentence = yield first_sentence print('生成器从外部获取的值:', second_sentence) yield g = gen() first_sentence = next(g) print('外部从生成器获取的值:', first_sentence) g.send('小鸡炖蘑菇') 有关python生成器的更多内容, 可以参考https://www.python.org/dev/peps/pep-0342/
四. IO多路复用
程序之间切换的问题解决了, 现在的问题是, IO操作的等待时间是不确定的, 如果在操作还未结束的时候, 就调用next对生成器进行驱动, 比如还没连接成功时就调用send语句, 显然得不到想要的结果. 因此, 需要一种机制, 能够在IO操作完成的时候进行通知, 这时候再驱动生成器进行后续的操作.
使用python自带的select模块可以对多个socket对象进行监听, 当触发到可读, 可写或者错误事件时, 返回触发事件的socket对象列表.
基于IO多路复用和生成器等功能写的爬虫代码如下:
import select import socket import time req = 'GET / HTTP/1.0 Host:cn.bing.com '.encode('utf8') address = ('cn.bing.com', 80) db = [] class GenCrawler: ''' 这里使用一个类将生成器封装起来,如果要驱动生成器,就调用next_step方法 另外,这个类还可以获取到使用的socket对象 ''' def __init__(self): self.sock = socket.socket() self.sock.setblocking(0) self._gen = self._crawler() def next_step(self): next(self._gen) def _crawler(self): self.sock.connect_ex(address) yield self.sock.send(req) response = b'' while 1: yield chunk = self.sock.recv(1024) if chunk == b'': self.sock.close() break else: response += chunk db.append(response) def event_loop(crawlers): # 首先,建立sock与crawler对象的映射关系,便于由socket对象找到对应的crawler对象 # 建立映射的同时顺便调用crawler的next_step方法,让内部的生成器运行起来 sock_to_crawler = {} for crawler in crawlers: sock_to_crawler[crawler.sock] = crawler crawler.next_step() # select.select需要传入三个列表,分别对应要监听的可读,可写和错误事件的socket对象集合 readable = [] writeable = [crawler.sock for crawler in crawlers] errors = [] while 1: rs, ws, es = select.select(readable, writeable, errors) for sock in ws: # 当socket对象连接到服务器时,会创建可读缓冲区和可写缓冲区 # 由于可写缓冲区创建时为空,因此连接成功时,就触发可写事件 # 这时再转为监听可读事件,接收到数据时,就可以触发可读事件了 writeable.remove(sock) readable.append(sock) sock_to_crawler[sock].next_step() for sock in rs: try: sock_to_crawler[sock].next_step() except StopIteration: # 如果生成器结束了,就说明对应的爬虫任务已经结束,不需要监听事件了 readable.remove(sock) # 所有的事件都结束后,就退出循环 if not readable and not writeable: break if __name__ == '__main__': start = time.time() n = 10 print('开始爬取...') event_loop([GenCrawler() for _ in range(n)]) print('获取到{}条数据,用时{:.2f}秒'.format(len(db), time.time()-start))
首先看看Crawler._crawler部分的代码, 在调用connect_ex方法之后, 程序并不能确定什么时候能连接到服务器, 在调用recv方法之前, 程序也不能确定什么时候能收到服务器的数据, 因此, 在这两个位置插入yield语句, 来使程序挂起. 这样, 一个基于生成器的爬虫程序就做好了.
然后是event_loop部分, 首先, 由于select监听到事件后, 返回的是socket对象, 因此先建立一个socket对象映射crawler对象的字典, 这样当监听到事件时, 就可以马上找到对应的crawler并对其驱动. 映射建立后, 就可以在while循环中持续监听socket对象, 监听到结果时, 就驱动对应的crawler, 直到所有的爬虫任务都结束为止.
在程序末尾分别设置n=1以及 n=10, 运行程序, 结果如下 :
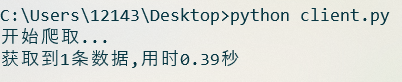 n=1
n=1
 n=10
n=10
程序的执行流程如下:

event_loop负责对多个爬虫任务进行调度, 在这个流程图中, 首先监听到某个事件, 于是驱动对应的crawler2, 而crawler2遇到IO操作后, 就使用yield挂起自己, 在crawlerr2的IO操作结束之前, event_loop又可以去驱动crawler1, 不同的crawler任务和event_loop穿插运行, 减少了IO操作中的时间浪费.
五. 总结
- IO在对文件和网络的操作中较常见. 特点是需要花费一定的等待时间才能完成操作;
- 在函数中加入yield关键字, 这个函数就能够返回一个生成器. 生成器的特点是运行到yield时会暂停, 而调用next函数由可以将其继续驱动;
- IO多路复用机制可以同时监听多个socket对象. 在本文最后的实例中, 使用IO多路复用机制监听socket对象, 触发到事件时, 驱动对应的生成器运行, 当生成器运行到IO操作时, 再使用yield语句切换回事件监听, 这样一方面利用了IO操作中的等待时间, 提高的运行效率, 一方面实现了多个任务并发的效果.