作业说明
github项目地址
PSP 表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | **实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 480 | 480 |
| Development | 开发 | 60 | 60 |
| · Analysis | · 需求分析 (包括学习新技术) | 30 | 180 |
| · Design Spec | · 生成设计文档 | 0 | 0 |
| · Design Review | · 设计复审 | 10 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 0 | 0 |
| · Design | · 具体设计 | 60 | 240 |
| · Coding | · 具体编码 | 60 | 120 |
| · Code Review | · 代码复审 | 10 | 10 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 90 |
| Reporting | 报告 | 20 | 120 |
| · Test Repor | · 测试报告 | 60 | 120 |
| · Size Measurement | · 计算工作量 | 10 | 120 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 0 | 0 |
| 合计 | 870 | 1580 |
解题思路
- 看到题目之后,统计词频,于是就直接打算用map去做了(因为简单方便)-但是运行速度并不是很理想
- 然后题目涉及到了文件的读取,于是就是开始查找关于文件读写的方法
- 接下来就是使用命令行运行exe文件以及封装,这一步是等写完整个代码之后才开始修改的,开始百度资料。
设计过程
-
流程图:

-
模块划分
- judge(string str)用来判度该串是否符合长度小于4以及首位不能为字符
- get(string str,int &num)对每行string进行拆分
- work(string file_name) 进行每行读取以及计算
- output(string file_name) 用于输出

-
最后将该模块放在一个类中
性能分析图

- 其中消耗最大的是work函数,毕竟这个整个程序的交汇点,进行了很多文件的读取操作
- 其次是get函数,主要是对于每一行进行字符串拆分,由于我是用简单的string +的操作来进行,因此在速度会相对较慢。
- 自我认为,如果把代码改成C语言的文件读取,以及把string类型修改成char 的话,会变得比较快,但是就不能用简单的map来实现了(因此就没有进行大部分优化)。
关键代码
- work函数
void WordCounts::work(string file_name,string fout_name) {
ifstream fin(file_name, ios::in);
ofstream fout(fout_name, ios::out);//将 ans 写入output文件
int chnu = 0, words = 0, lines = 0;
string tmp;
int nucnt = 0;
while (getline(fin, tmp)) {
nucnt++;//
chnu += tmp.length();//字符个数记录
if(get(tmp, words))lines++;//分解每行字符串+判断是否为有效行数
}
si_map::iterator it;//利用迭代器遍历map
vector<Word>w;
for (it = mp.begin(); it != mp.end(); it++) {
Word t;
t.word = it->first; t.num = it->second;
w.push_back(t);
}
sort(w.begin(), w.end());
//读入output文件
fout << "characters: " << chnu + nucnt << endl;///chun没有存取回车符
fout << "words: " << words << endl;
fout << "lines: " << lines << endl;
int cnt = w.size();
for (int i = 0; i < min(10, cnt); i++)
{
fout << "<" << w[i].word << ">: " << w[i].num << endl;
}
return;
}
- get函数
bool WordCounts::get(string str, int & num) {//对每行string进行分解+统计单词个数
int len = str.length();
int fg = 0;
string neword = "";
for (int i = 0; i < len; i++) {
if (str[i] != '
' && str[i] != ' ') fg = 1;
if ((str[i] > 'Z' || str[i] < 'A') && (str[i] > 'z' || str[i] < 'a') && (str[i] > '9' || str[i] < '0')) {
if (judge(neword)) num++;
neword = "";
continue;
}
else
{
neword += str[i];
}
}
if (judge(neword))num++;
return fg;
}
- judge函数
bool WordCounts::judge(string str) {//判断是否符合条件+统计每个单词的出现次数
int len = str.length();
if (len < 4) return false;//长度小于4
if ((str[0] <= 'Z'&&str[0] >= 'A') || (str[0] <= 'z'&&str[0] >= 'a')) {//开头不能是数字
for (int i = 0; i < len; i++) {
if (str[i] <= 'Z'&&str[i] >= 'A') str[i] = str[i] - 'A' + 'a';
}
mp[str]++;//存入map
return true;
}
return false;
}
单元测试
| 测试点 | 测试内容 | 通过情况 |
|---|---|---|
| in1.txt | 数字不能为开头 | 通过 |
| in2.txt | 有效行数 | 修改后通过 |
| in3.txt | 小数据字典序排序 | 通过 |
| in4.txt | 大写字母转小写 | 通过 |
| in5.txt | 非字母非字符的分割 | 通过 |
| in6.txt | 字母之间混杂数字的排序 | 通过 |
| in7.txt | 小篇短文 | 通过 |
| in8.txt | 全为数字字符和非字母字符 | 通过 |
| in9.txt | 空白文件 | 通过 |
| in10.txt | 字母的字典序排序 | 通过 |
- 部分单元测试代码
TEST_METHOD(TestMethod1)
{
// TODO: 在此输入测试代码
WordCounts test;
string fin_name = "../UnitTest1/in1.txt", fout_name = "../UnitTest1/out1.txt";
test.work(fin_name,fout_name);
test.output(fout_name);
ifstream fxx(fout_name, ios::in);
string tmp;
getline(fxx, tmp);
Assert::AreEqual((string)"characters: 16",tmp);
getline(fxx, tmp);
Assert::AreEqual(tmp, (string)"words: 1");
getline(fxx, tmp);
Assert::AreEqual(tmp, (string)"lines: 1");
getline(fxx, tmp);
Assert::AreEqual(tmp, (string)"<abcd123>: 1");
}
TEST_METHOD(TestMethod3)
{
// TODO: 在此输入测试代码
WordCounts test;
string fin_name = "../UnitTest1/in3.txt", fout_name = "../UnitTest1/out3.txt";
test.work(fin_name, fout_name);
test.output(fout_name);
ifstream fxx(fout_name, ios::in);
string tmp;
getline(fxx, tmp);
Assert::AreEqual((string)"characters: 32", tmp);
getline(fxx, tmp);
Assert::AreEqual(tmp, (string)"words: 3");
getline(fxx, tmp);
Assert::AreEqual(tmp, (string)"lines: 1");
getline(fxx, tmp);
Assert::AreEqual(tmp, (string)"<windows2000>: 1");
getline(fxx, tmp);
Assert::AreEqual(tmp, (string)"<windows95>: 1");
getline(fxx, tmp);
Assert::AreEqual(tmp, (string)"<windows98>: 1");
}
-
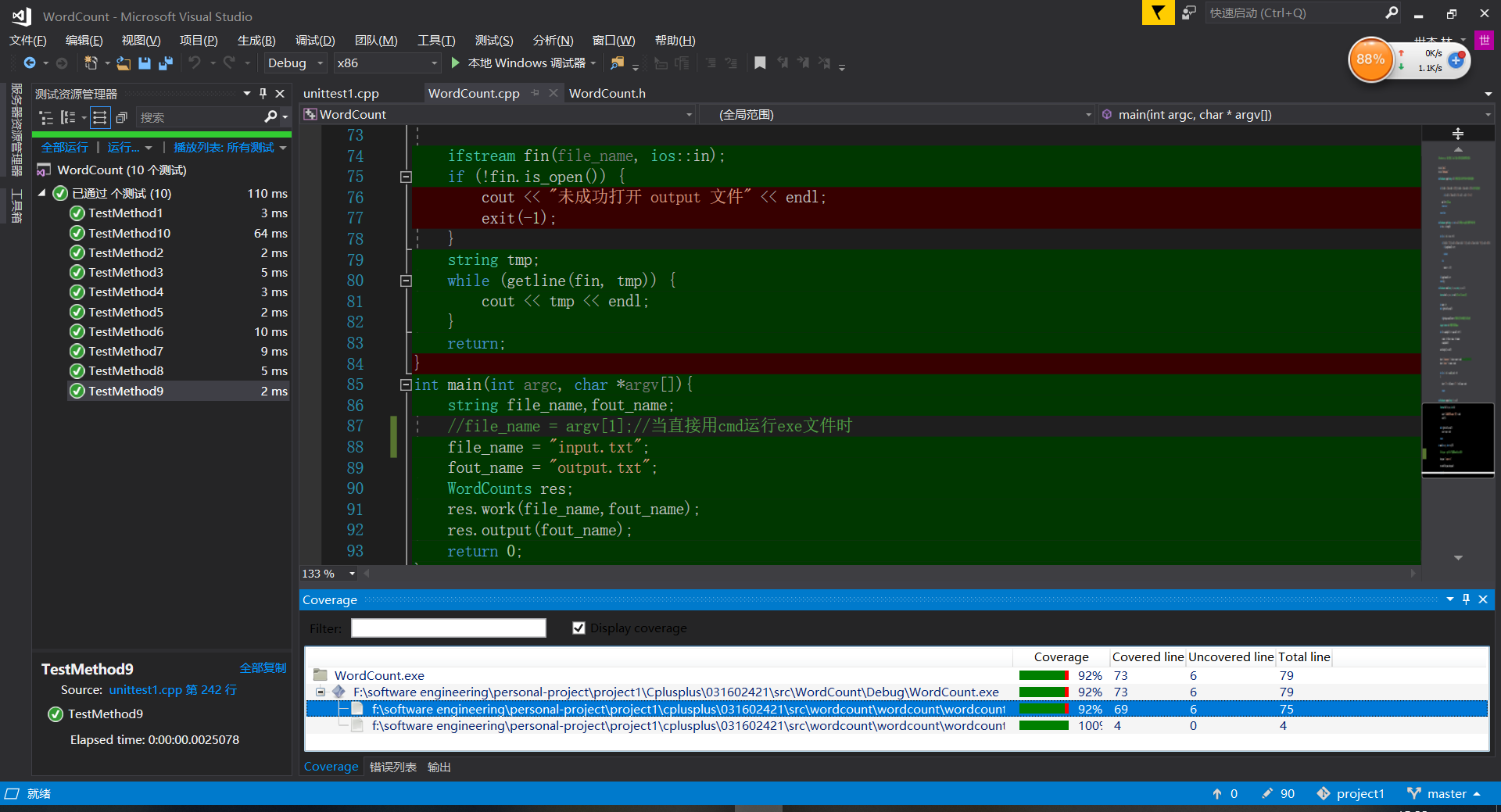
代码覆盖率
-
异常处理部分
- 主要异常是文件的读取部分,因此由以下来判断异常

- 主要异常是文件的读取部分,因此由以下来判断异常
体会与收获
- 体会:从作业布置开始,完成上面的任务,几乎已经没有心情写体会了,感觉自己做得挺崩溃的。回想起来之前每天给这个作业的时间并不多,一开始也直接胡乱写,没有认真看好设计要求,导致后面这个几个任务寸步难行。真的是像老师说的写代码的时间在整个作业的过程中是非常少的。对于我来说作业后面的性能分析、单元测试、代码覆盖率,这些基本之前没有听说过,也没有用过。在这最后两天的时间内疯狂摸索,只能说自己之前时间花得太少了,在这过程中问了一些同学,也参考了一些博客。看到提交的作业,想到为什么别人写得这么好,这么强,而我现在却是勉勉强强的把作业完成。我想每个人的差距就是在这过程中逐渐拉开的把。
- 收获:首先,自己熟悉了git的一些操作,这次作业因为有时代码改崩了,就进行了git版本控制,真心想说 git大法好,如果没有版本控制,我基本可能就凉凉了。其次,就是VS的功能运用吧,这里的单元测试是参考 畅畅博客中的他推荐刘乾学长的博客。之后就是代码覆盖率这是参考了钧昊的在博客中提供的关于OpenCppCoverage的博客,以及钧昊博客中的使用教程。