Python写爬虫的感觉那叫一个爽!100行代码不到,爬取整站,貌似这样下去拉钩还不加强服务器么?下面看看半智能的效果,下面看图:
输入命令后,小爬虫开始工作了!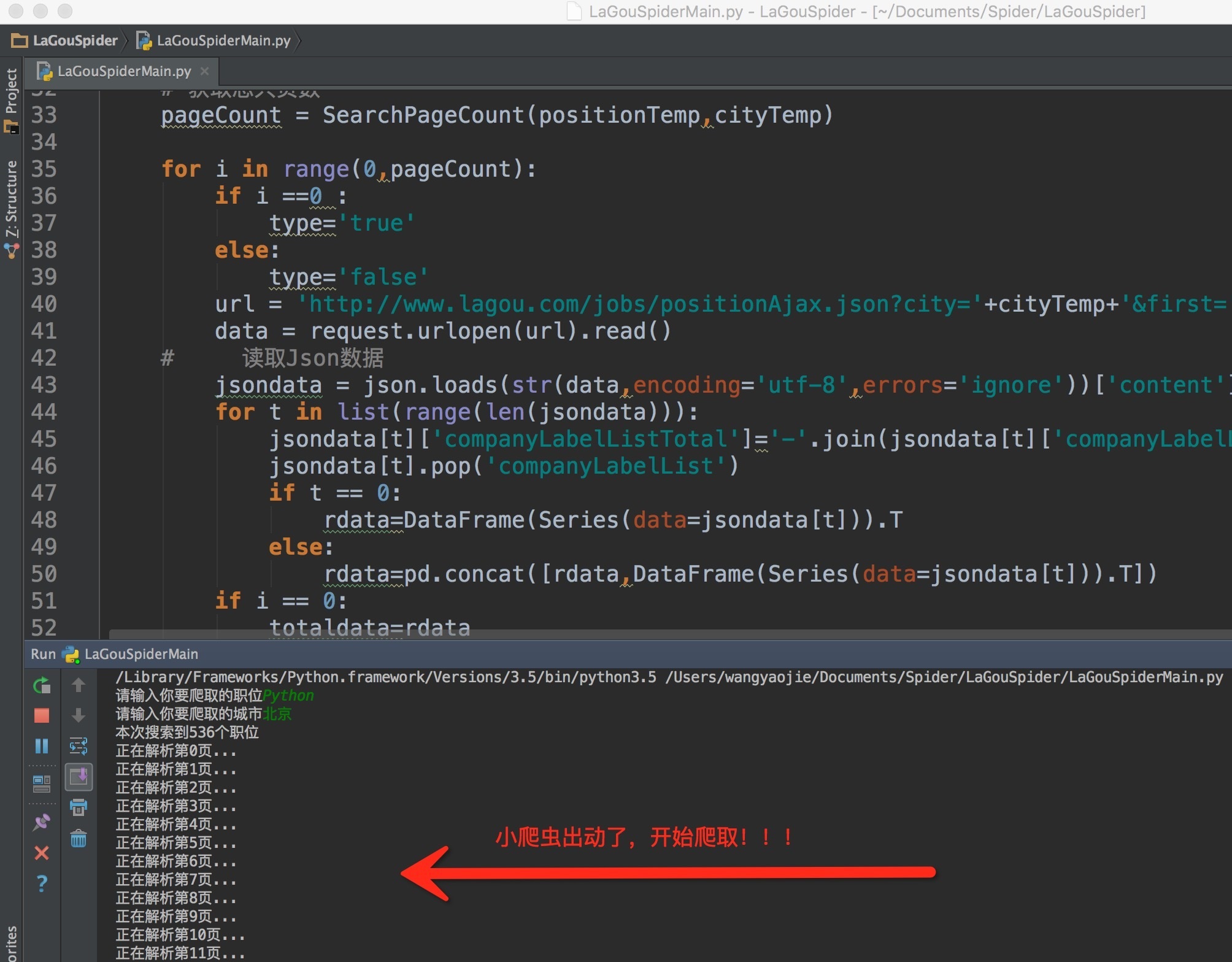
爬去结束后小爬虫自动生成了一个XLS文件,一般的excel就能打开了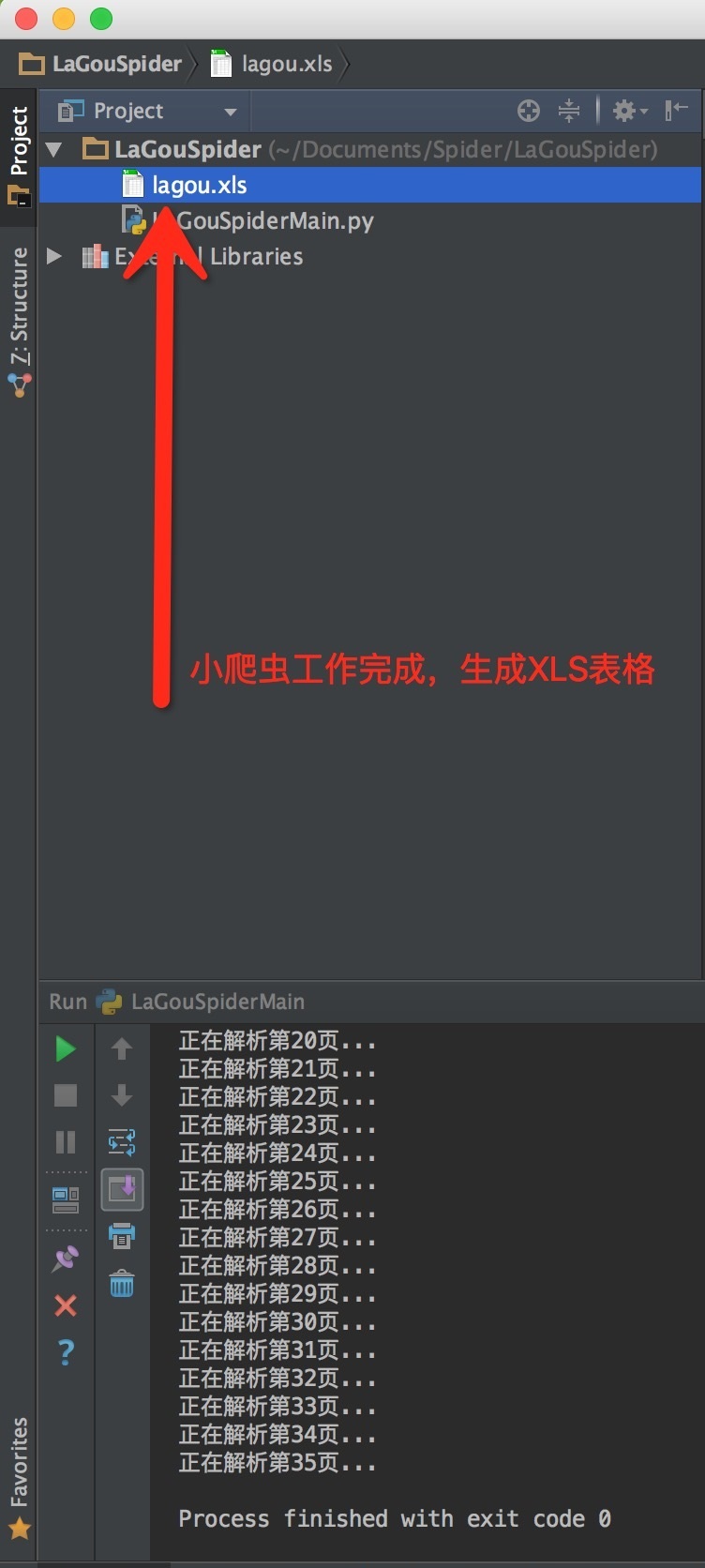
最后看看成果: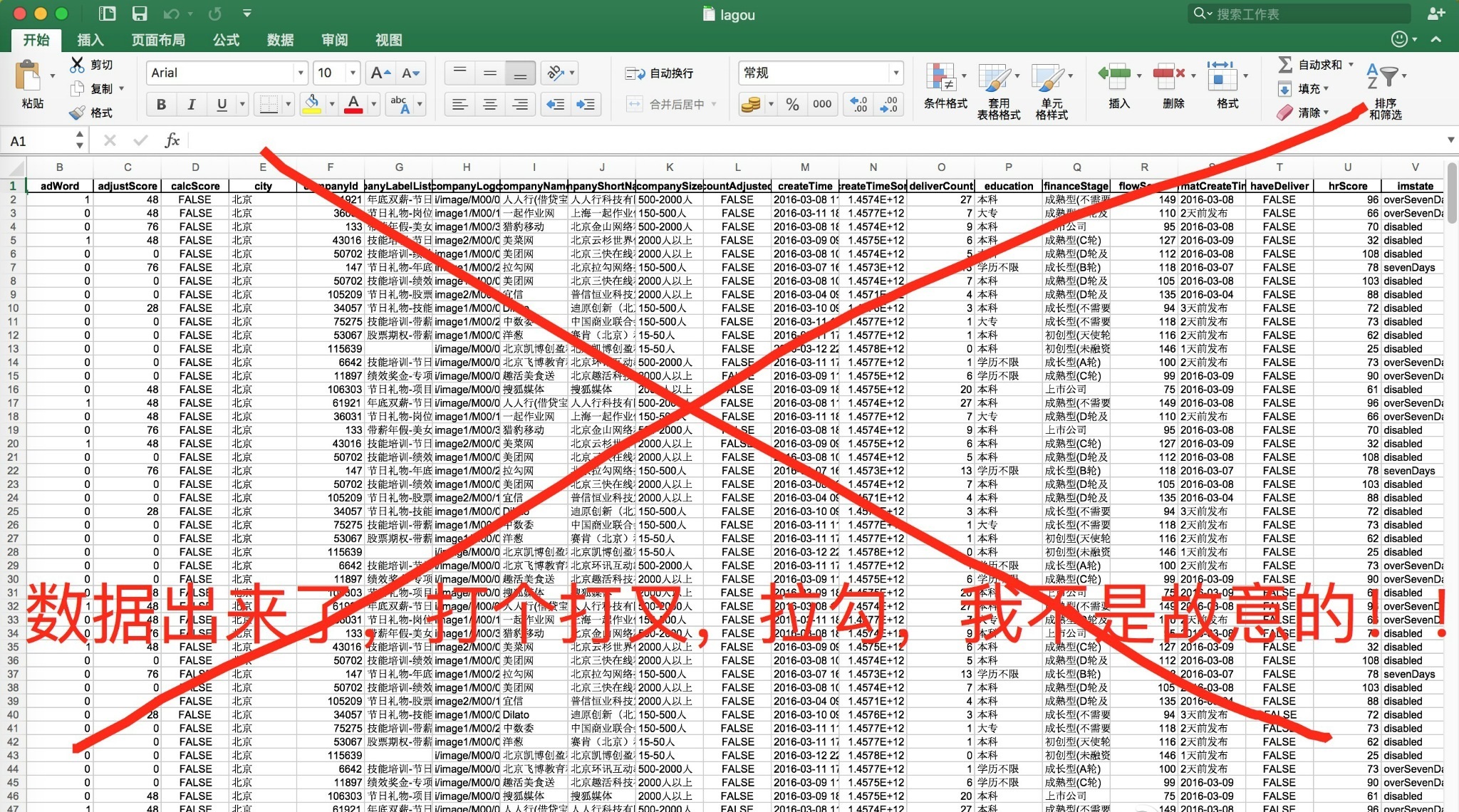
好了,效果看完了,看看小爬虫怎么制造出来的吧。。。
其中也没有什么难点的技术,不过pandas很值得学习,给个学习链接http://pandas.pydata.org,挺不错的。。下面贴一下代码吧。。。
# -*- coding:utf-8 -*-
import re,json
from urllib import request
from pandas import DataFrame,Series
import pandas as pd
__author__ = "放养的小爬虫"
# 处理字符串的函数
def ProcessingString(string):
string = string.encode('utf-8')
string = str(string).replace(r'x','%').replace(r"'","")
string = re.sub('^b','',string)
return string
# 计算总共页数
def SearchPageCount(position, city):
i = 0
type = 'true'
url = 'http://www.lagou.com/jobs/positionAjax.json?city='+city+'&first='+type+'&kd='+position+'&pn='+str(i+1)
with request.urlopen(url) as f:
data = f.read()
count = int(json.loads(str(data,encoding='utf-8',errors='ignore'))["content"]["totalPageCount"])
totalCount = int(json.loads(str(data,encoding='utf-8',errors='ignore'))["content"]["totalCount"])
print('本次搜索到%d个职位'%totalCount)
return count
def LaGouSpiderWithKeyWord(position, city):
positionTemp = ProcessingString(position)
cityTemp = ProcessingString(city)
# 获取总共页数
pageCount = SearchPageCount(positionTemp,cityTemp)
for i in range(0,pageCount):
if i ==0 :
type='true'
else:
type='false'
url = 'http://www.lagou.com/jobs/positionAjax.json?city='+cityTemp+'&first='+type+'&kd='+positionTemp+'&pn=1'
data = request.urlopen(url).read()
# 读取Json数据
jsondata = json.loads(str(data,encoding='utf-8',errors='ignore'))['content']['result']
for t in list(range(len(jsondata))):
jsondata[t]['companyLabelListTotal']='-'.join(jsondata[t]['companyLabelList'])
jsondata[t].pop('companyLabelList')
if t == 0:
rdata=DataFrame(Series(data=jsondata[t])).T
else:
rdata=pd.concat([rdata,DataFrame(Series(data=jsondata[t])).T])
if i == 0:
totaldata=rdata
else:
totaldata=pd.concat([totaldata,rdata])
print('正在解析第%d页...'%i)
totaldata.to_excel('lagou.xls',sheet_name='sheet1')
if __name__ == "__main__":
position = input('请输入你要爬取的职位')
city = input('请输入你要爬取的城市')
LaGouSpiderWithKeyWord(position, city)