面试题
在Django的ORM操作中,返回列表查询集的过滤器有哪些?
- order_by():排序
- all() :返回所有的数据
- filter():返回满足条件的数据
- exclude():返回满足条件之外的数据,相当于sql语句中where部分的not关键字
在Django中,QuerySet的get和filter方法的区别,请从接收参数、返回内容以及异常三个方面来阐述?
| 方法 | 输入参数 | 返回值 | 异常 |
|---|---|---|---|
| get | 严格匹配 | 一个定义的model对象 | 当返回多条记录或者没有找到记录的时候都会抛出异常 |
| filter | 支持模糊匹配 | 查询集、支持链式操作 | 不抛异常 |
在Django视图中,可以获取前端传过来的哪些参数?如何获取?
-
form提交的参数
- request.POST
-
url路径参数
- def get(request, some_param)
-
查询字符串参数
- request.GET
-
请求头获取参数
- request.META
Redis数据库中有哪几种数据类型呢?
一、CSRF是什么?django中如何防护?
1.开启csrf
Cross-site request forgery (CSRF) is an attack that tricks a user into making unwanted actions on a website, where they are already authenticated, while they are visiting another site.
- 全局开启csrf防护
# 全局开启csrf防护 django.middleware.csrf.CsrfViewMiddleware # 生成csrf cookie和判断csrf token是否正确
-
针对某一个函数视图开启csrf防护
@csrf_protect def my_view(request): # 函数视图逻辑 return render(request, "example.html")
-
针对某一个类视图开启csrf防护
@method_decorator(csrf_protect) class MyClassView(request): # 类视图逻辑 return render(request, "example.html")
-
在template模版中,使用
{% csrf_token %},去生成随机的csrf token(key为csrfmiddlewaretoken的隐藏字段)
2.关闭csrf
注释掉CsrfViewMiddleware中间件,添加csrf_exempt装饰器
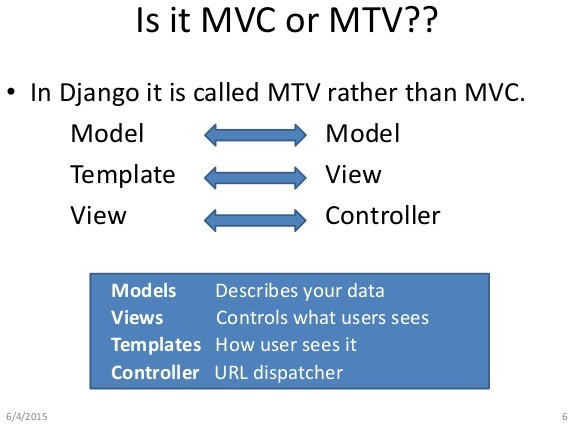
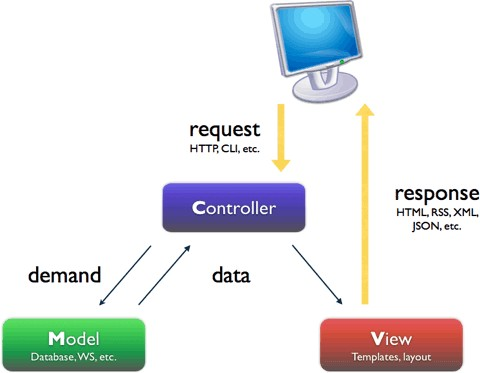
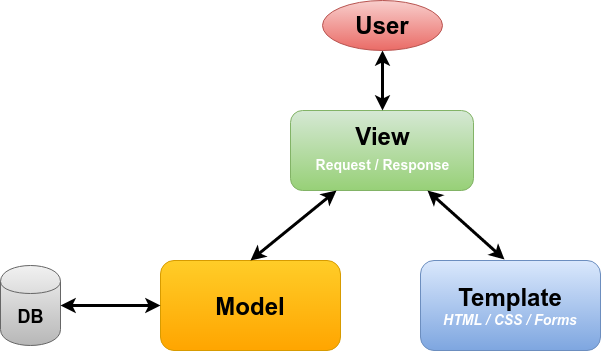
请简略描述一下Django的架构(提示:MVT)?
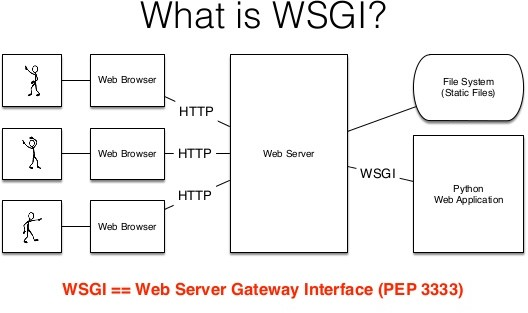
什么是wsgi协议?
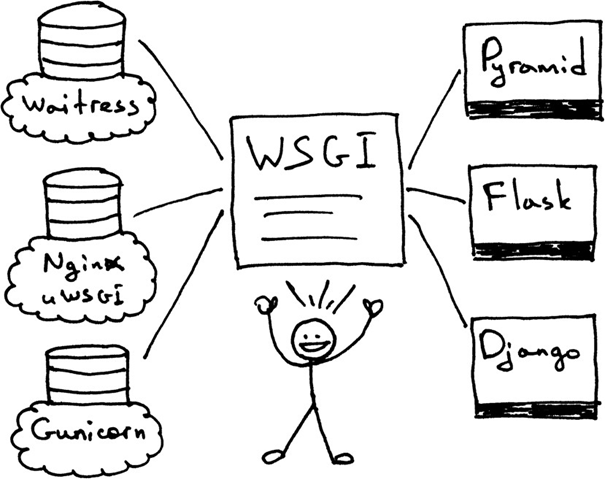
请分析一下,django、flask、tornado这三个主流框架的优缺点?
请分析一下,Django ORM和原生SQL的优缺点?
| 优点 | 缺点 | |
|---|---|---|
| Django ORM | 快速开发、隐藏数据访问细节、避免不规范的SQL、简化迁移 | 影响性能、复杂查询效率低 |
| RAW SQL | 复杂查询更灵活 | 需要检查SQL是否有问题、SQL注入漏洞 |
Django ORM高级操作:
-
Lazy load和Cache提升性能
-
defer和only
-
Django中使用原生SQL
-
News.objects.only('title').filter(tag_id=1).extra(where=['clicks>800'])
-
news = News.objects.raw('select id, title from tb_news')
-
类似pymysql操作
from django.db import connection cursor = connection.cursor() cursor.execute("select id, title from tb_news") cursor.fetchall()
-
-
select_related关联查询
-
using 多个数据库时控制QuerySet在哪个数据库上操作---
Django 从请求到响应发生了什么?
一、Django的启动
1、启动的服务器
开发、测试中:runserver
生产环境中:nginx + uwsgi
应用启动会做如下操作:
- 创建WSGIServer类的实例,接受用户请求
- WSGIHandler,处理用户请求和响应
2、WSGI
Python Web Server Gateway Interface (或简称 WSGI,读作“wizgy”)。WSGI不是服务器,也不用于与程序交互的API,更不是代码,而只是定义了一个接口,用于描述web server如何与web application通信的规范。
它允许开发者将选择web框架和web服务器分开。可以让不同的web服务器和不同的web框架配合在一起运行,选择一个适合的配对。
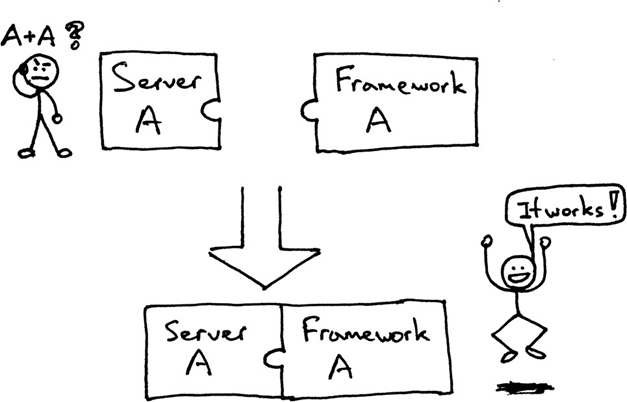
wsgi server 中会定义一个start_response函数,然后将用户请求信息environ和start_response传给框架
# 在wsgi server中会调用application方法,生成django框架中的一个应用实例 def application(environ, start_response): start_response('200 OK', [('Content-Type', 'text/html')]) return 'Hello World!' def start_response(self, status_code, header): """ 生成响应头 :param status_code: 响应状态码 :param header: 响应头 :return: 聚合之后的响应头 """ temp_header = ' '.join((str(k) + ': ' + str(v) for k, v in header)) self.response_headers = 'HTTP/1.1 ' + status_code + ' ' + temp_header + ' '
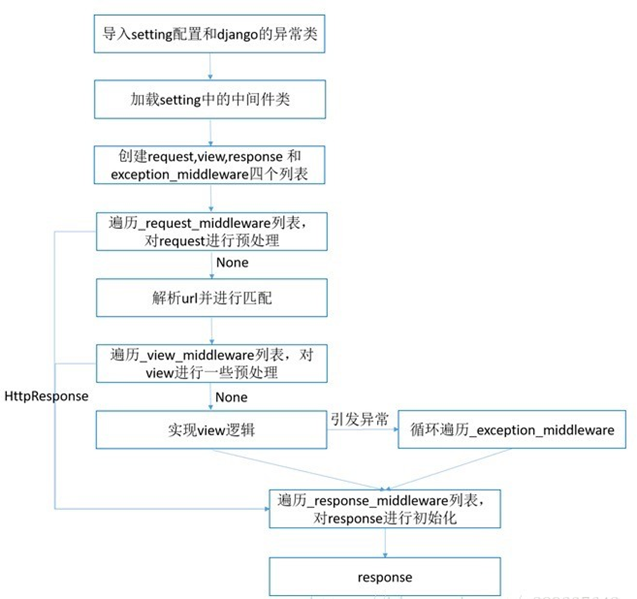
二、请求到响应的整个过程
图一:
图二:
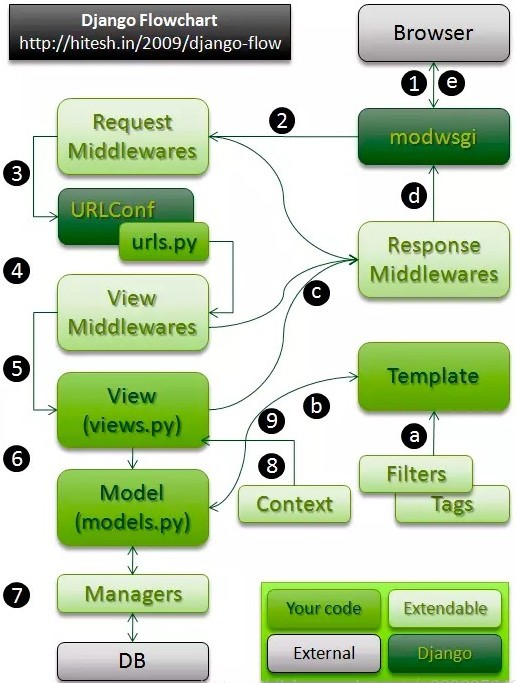
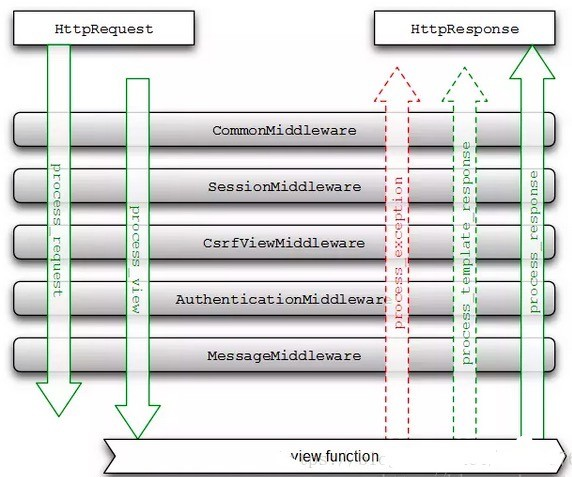
1、中间类中的顺序与方法
# 5个方法 process_request、 process_view、process_template_response、process_exception、process_response for middleware_path in settings.MIDDLEWARE: ··· if hasattr(mw_instance, 'process_request'): request_middleware.append(mw_instance.process_request) if hasattr(mw_instance, 'process_view'): self._view_middleware.append(mw_instance.process_view) if hasattr(mw_instance, 'process_template_response'): self._template_response_middleware.insert(0,mw_instance.process_template_response) if hasattr(mw_instance, 'process_response'): self._response_middleware.insert(0, mw_instance.process_response) if hasattr(mw_instance, 'process_exception'): self._exception_middleware.insert(0, mw_instance.process_exception)
中间件执行顺序:
Mysql集群和负载均衡
一、为什么要使用数据库集群和负载均衡?
1.高可用
2.高并发
3.高性能
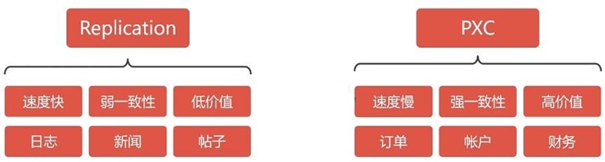
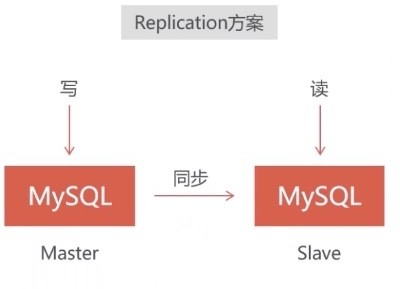
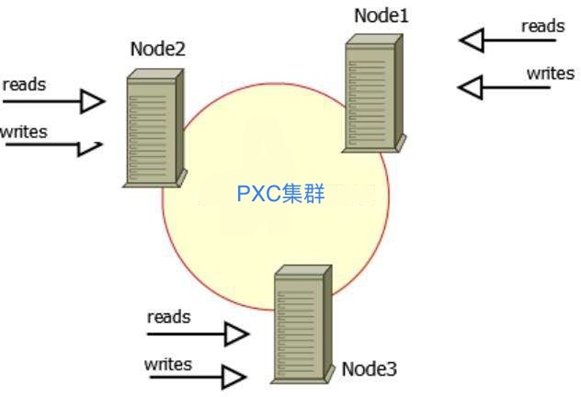
二、mysql数据库集群方式
三、使用docker安装PXC
1.拉取PXC镜像
docker pull percona/percona-xtradb-cluster:5.7
2.创建volume卷
docker volume create --name v1 docker volume create --name v2 docker volume create --name v3
3.创建network网络
docker network create --subnet=172.18.0.0/24 net1
4.运行PXC容器
# 创建node1 docker run -d -p 8002:3306 -v v1:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=qwe123 -e XTRABACKUP_
PASSWORD=qwe123 -e CLUSTER_NAME=PXC --name=node1 --net=net1 --ip 172.18.0.2 percona/percona-xtradb-cluster:5.7 # 创建node2 docker run -d -p 8003:3306 -v v2:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=qwe123 -e XTRABACKUP_
PASSWORD=qwe123 -e CLUSTER_NAME=PXC -e CLUSTER_JOIN=node1 --name=node2 --net=net1 --ip 172.18.0.3 percona/percona-xtradb-cluster:5.7 # 创建node3 docker run -d -p 8004:3306 -v v3:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=qwe123 -e XTRABACKUP_
PASSWORD=qwe123 -e CLUSTER_NAME=PXC -e CLUSTER_JOIN=node1 --name=node3 --net=net1 --ip 172.18.0.4 percona/percona-xtradb-cluster:5.7
四、为什么要使用Haproxy?
1.高性能
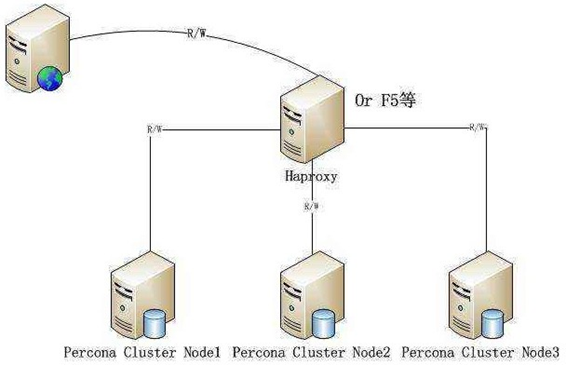
2.使用docker安装Haproxy
# 拉取haproxy image docker pull haproxy # 在虚拟机中创建保存haproxy配置文件的目录 mkdir -p ~/haproxy_conf/
# 创建haproxy.cfg配置文件 global #工作目录 chroot /usr/local/etc/haproxy #日志文件,使用rsyslog服务中local5日志设备(/var/log/local5),等级info log 127.0.0.1 local5 info #守护进程运行 daemon defaults log global mode http option httplog option dontlognull timeout connect 5000 timeout client 50000 timeout server 50000 #监控界面 listen admin_stats #监控界面的访问的IP和端口 bind 0.0.0.0:8888 #访问协议 mode http #URI相对地址 stats uri / stats realm Global statistics #登陆帐户信息 stats auth admin:qwe123 #数据库负载均衡 listen proxy-mysql #访问的IP和端口 bind 0.0.0.0:3306 #网络协议 mode tcp #负载均衡算法(轮询算法) #轮询算法:roundrobin #权重算法:static-rr #最少连接算法:leastconn #请求源IP算法:source balance roundrobin #日志格式 option tcplog #在MySQL中创建一个没有权限的haproxy用户,密码为空。Haproxy使用这个账户对MySQL数据库心跳检测 option mysql-check user haproxy server MySQL_1 172.18.0.2:3306 check weight 1 maxconn 2000 server MySQL_2 172.18.0.3:3306 check weight 1 maxconn 2000 server MySQL_3 172.18.0.4:3306 check weight 1 maxconn 2000 option tcpka
# 运行容器 docker run -it -d -p 8078:8888 -p 8036:3306 -v /home/pyvip/haproxy_conf:/usr/local/etc/haproxy --name h1 --privileged --net=net1 --ip 172.18.0.5 haproxy # 进入haproxy容器,启动haproxy docker exec -it h1 bash # 加载haproxy配置文件 haproxy -f /usr/local/etc/haproxy/haproxy.cfg
3.使用Navicat登录haproxy
在数据库中创建一个没有任何权限的haproxy用户,密码为空,来测试mysql负载均衡是否正常。
CREATE USER 'haproxy'@'%' IDENTIFIED BY '';
性能优化
一、celery异步
1.为什么要使用celery?
- 手机短信验证,一直等待
- 发送激活邮件,一直等待
- 上传文件,一直等待
2.celery是什么?
- 即插即用
- 异步任务队列
- 简单:易于使用和维护,有丰富的文档
- 高效:单个进程每分钟可以处理数百万个任务
- 灵活:几乎每个部分都可以自定义扩展
3.组成
- broker(中间人、任务队列)
- client(任务的发出者)
- worker(任务的处理者)

4.安装celery
# 进入项目虚拟环境中pip install celery
5.异步发送手机短信验证码
# 在项目根目录创建celery_tasks/celery_main.py文件 #!/usr/bin/env python3 # -*- coding: utf-8 -*- from celery import Celery # 为celery使用django配置文件进行设置 import os # if not os.getenv('DJANGO_SETTINGS_MODULE'): # os.environ['DJANGO_SETTINGS_MODULE'] = 'dj_pre_class.settings' os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'dj_pre_class.settings') app = Celery('dj_pre_class') # 创建celery应用 app.config_from_object('celery_tasks.celery_config') # 导入celery配置 # 导入任务 app.autodiscover_tasks(['celery_tasks.sms', ])
# 创建celery_tasks/celery_config.py文件 #!/usr/bin/env python3 # -*- coding: utf-8 -*- broker_url = "redis://127.0.0.1:6379/3" # 存放broker消息队列 result_backend = "redis://127.0.0.1:6379/4" # 存放执行结果
# 创建celery_tasks/sms/tasks.py文件 #!/usr/bin/env python3 # -*- coding: utf-8 -*- import logging from utils.yuntongxun.sms import CCP from celery_tasks.celery_main import app # 导入日志器 logger = logging.getLogger('django') @app.task(name='send_sms_code') def send_sms_code(mobile, sms_num, expires, temp_id): """ 发送短信验证码 :param mobile: 手机号 :param sms_num: 短信验证码 :param expires: 云通讯验证码过期时间 :param temp_id: 短信模版id :return: """ try: result = CCP().send_template_sms(mobile, [sms_num, expires], temp_id) except Exception as e: logger.error("发送验证码短信[异常][ mobile: %s, message: %s ]" % (mobile, e)) else: if result == 0: logger.info("发送验证码短信[正常][ mobile: %s sms_code: %s]" % (mobile, sms_num)) else: logger.warning("发送验证码短信[失败][ mobile: %s ]" % mobile)
加载异步任务,发送短信验证码
# 在apps/verifications/views.py中 # 调用delay方法,使用celery 发送手机验证码 celery_res = send_sms_code.delay(mobile, sms_num, constants.SMS_CODE_YUNTX_EXPIRES, constants.SMS_CODE_TEMP_ID) logger.info("发送验证码短信[正常][ mobile: %s sms_code: %s]" % (mobile, sms_num)) return to_json_data(errno=Code.OK, errmsg="短信验证码发送成功")
开启celery异步任务
# 进入虚拟环境,切换到项目根目录中 celery -A celery_tasks.celery_main worker -l info
二、缓存机制
1.为什么要使用缓存?
- 提升页面加载速度
- 不是所有的场景都适合缓存
- 访问频繁,更新不频繁
2.加载缓存提升网站主页访问速度
# 在dj_pre_class/settings.py中添加如下配置: CACHES = { # 页面缓存技术 "page_cache": { "BACKEND": "django_redis.cache.RedisCache", "LOCATION": "redis://127.0.0.1:6379/5", 'TIMEOUT': 120, # 过期时间设为120秒 "OPTIONS": { "CLIENT_CLASS": "django_redis.client.DefaultClient", } }, }
# 在apps/news/views.py中添加如下配置: from django.utils.decorators import method_decorator from django.views.decorators.cache import cache_page @method_decorator(cache_page(timeout=120, cache='page_cache'), name='dispatch') class IndexView(View): pass @method_decorator(cache_page(timeout=120, cache='page_cache'), name='dispatch') class NewsListView(View): pass @method_decorator(cache_page(timeout=120, cache='page_cache'), name='dispatch') class NewsBanner(View): pass