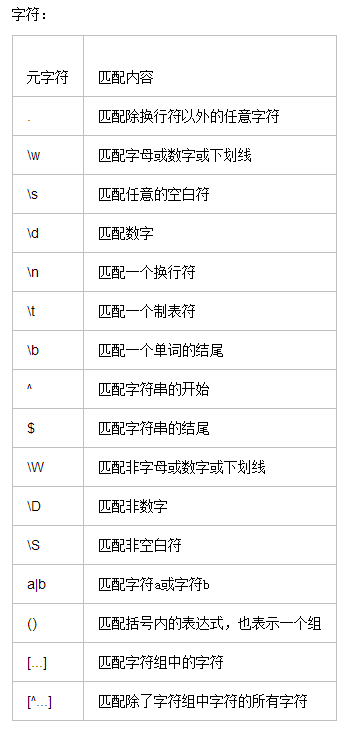
正则表达式本身也和python没有什么关系,就是匹配字符串内容的一种规则。
官方定义:正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。

# re.findall('正则表达式','带匹配的字符') # ret = re.findall('d+','alex83wusir38') # print(ret)#['83', '38'] # ret = re.findall('d','alex83wusir38') # print(ret)#['8', '3', '3', '8'] # ret = re.search('d','alex83wusir38') # print(ret) # 返回的匹配结果,而不是具体的值 # print(ret.group()) # 从左到右找到第一个匹配的就返回 # ret = re.search('d+','alex83wusir') # print(ret) # 返回的匹配结果,而不是具体的值 # if ret: # print(ret.group()) ret = re.match('d+','alex222wusir38') print(ret)#None # print(ret.group()) ret = re.search('^d+','83alex222wusir38') print(ret)#<re.Match object; span=(0, 2), match='83'> print(ret.group())#83 # 参数 返回值 # findall 正则 待匹配字符串 列表,所有符合的项 # search 变量,.group取结果,只有一项结果 # match 变量,.group取结果,默认在正则之前加上^ # 正则表达
import re ret = re.findall('www.(baidu|oldboy).com', 'www.oldboy.com') print(ret) # ['oldboy'] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可 ret = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com') print(ret) # ['www.oldboy.com']
# ret = re.search('(www).(baidu|google).(com)','www.baidu.com,www.google.com') # print(ret) # print(ret.group()) # print(ret.group(0)) # print(ret.group(1)) # print(ret.group(2)) # print(ret.group(3))