-
def 函数名():
- 函数内部功能代码
函数的命名规范:
可以由数字、字母和下划线组成,并且不能用数字开头
不能使用Python中的关键字
函数命名的风格:
单词之间下划线隔开(Python中函数命名更推荐这种风格)
大驼峰
小驼峰

(1)形参

不定长参数
定义:有时可能需要一个函数能处理比当初声明时更多的参数,声明时不会命名。
*args:接收0个或多个位置参数
**kwargs:接收0个或多个关键字参数
(2)实参
调用函数的时候,参数传递的两种方式
位置参数:通过位置传递参数(按顺序传递,第一个实参,传个形参...)
关键字传参:通过参数名指定传给某个参数(传参的时候,不用注意参数的位置关系)

函数的返回值:return
函数的返回值是由return来决定的
函数中没有return:函数的返回值默认为None
return后面没有任何内容,返回值也是None
函数要返回多个数据:在return后面每一个数据之间用逗号隔开,调用函数之后接收到的是个元组形式的数据。
return的作用是结束函数的运行
局部变量:在函数内部定义的变量,叫局部变量,只能在该函数内部使用,函数外部无法使用。
全局变量:直接定义在py文件中的变量,叫全局变量,在该文件中任何地方都可以使用。

global:在函数内部声明全局变量

-
-
input :输入(输入的不管是什么类型数据,都会当成字符串处理)
-
type:查看数据类型
-
id : 获取数据内存地址
-
range : 生成数据
-
len : 获取数据的长度(元素总数)
-
int、float、bool 、 str、list、tuple 、dict 、set :代表对应的数据类型
-
min :求最小值
-
max :求最大值
-
sum :求和
- enmerate:获取列表、字符串、元组的每个元素和对应的下标(是一个元组序列)
li=[11,22,33]
s='hduihiddfa'
res=enumerate(s)
print(list(res))
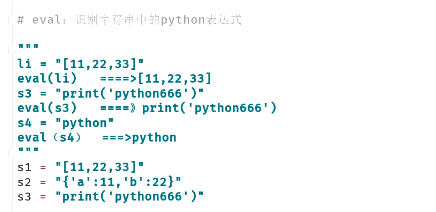
- eval:识别字符串中的python表达式
- filter:过滤器函数
参数1:过滤的规则函数
参数2: 要被过滤的数据
# 并且将case_id大于3的用例数据过滤出来
res1 = [
{'case_id': 1, 'case_title': '用例1', 'url': 'www.baudi.com', 'data': '001', 'excepted': 'ok'},
{'case_id': 4, 'case_title': '用例4', 'url': 'www.baudi.com', 'data': '002', 'excepted': 'ok'},
{'case_id': 2, 'case_title': '用例2', 'url': 'www.baudi.com', 'data': '002', 'excepted': 'ok'},
{'case_id': 3, 'case_title': '用例3', 'url': 'www.baudi.com', 'data': '002', 'excepted': 'ok'},
{'case_id': 5, 'case_title': '用例5', 'url': 'www.baudi.com', 'data': '002', 'excepted': 'ok'}
]
def func(data):
return data['case_id'] > 3
# 使用过滤器对数据进行过滤
data = filter(func, res1)
print(list(data))
- zip:聚合打包

