python3简单实现一个爬去网站图片的小功能:
有时候想要下载自己喜欢的多个图片时,不需要一个个点击来下载,使用python脚本批量拉取,并保存到本地。
1. 首先找到自己要下载图片的url

2. 上代码:
1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 # __Author__: 陌路疏途 4 5 6 # 四部曲:1.导入模块 2.获取网页源码 3.正则匹配下载 4.调用函数 7 8 import urllib.request #获取网址模块 9 import re #正则匹配模块 10 11 #定义获取网页源代码函数 12 def gethtml(): 13 papg = urllib.request.urlopen('http://www.wmpic.me/tupian/cute') #打开图片的网址 14 html = papg.read() #用read方法读成网页源代码,格式为字节对象 15 html = html.decode('UTF-8') #定义编码格式解码字符串(字节转换为字符串) 16 return html 17 18 #匹配 19 20 def getimg(html): 21 imgre = re.compile(r' src="(.*?)" class=')#正则匹配,compile为把正则表达式编译成一个正则表达式对象,提供效率。 22 imglist = re.findall(imgre, html)#获取字符串中所有匹配的字符串 23 x = 0 #定义全局变量默认为0 24 for imgurl in imglist: #循环图片字符串列表并输出 25 print(imgurl) 26 27 #下载 28 urllib.request.urlretrieve(imgurl,'D:\pictures\%s.jpg' % x)#把图片下载到本地并指定保存目录 29 x += 1 #每次自增1 30 print("正在下载第%s张" % x)#格式化输出张数 31 32 #调用函数 33 html = gethtml() 34 35 print(getimg(html))
3. 执行脚本输出信息

4. 进入保存图片路径查看:
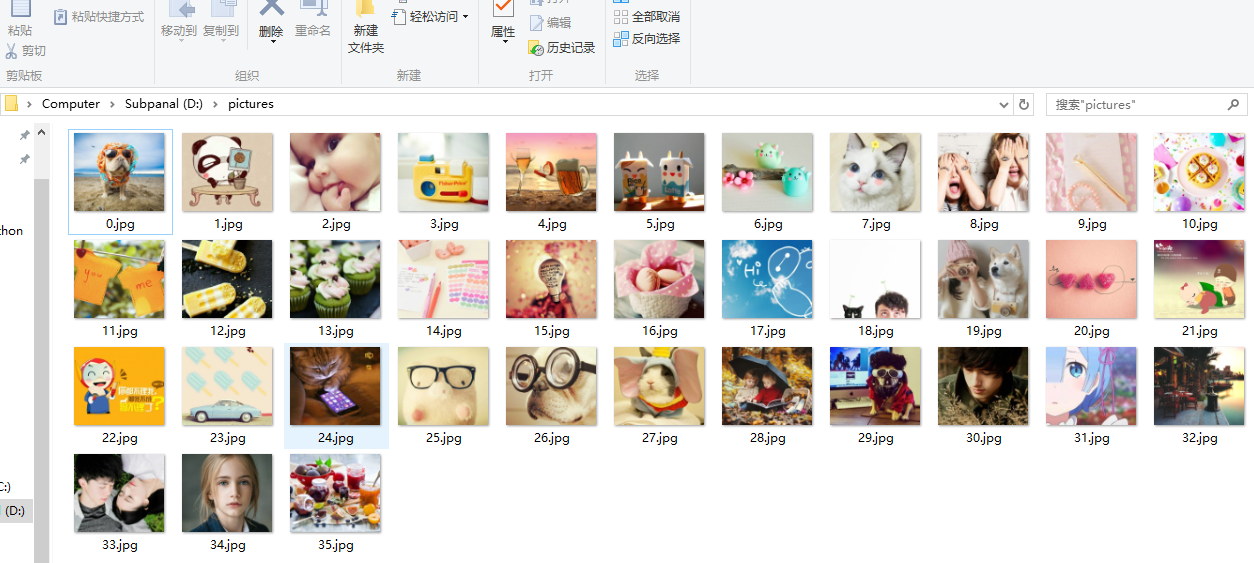
图片已经拉取下来,这样可以很容易得到自己想要的很多图片。而不用一个个点击下载。